이 글은 AI Harness 시리즈 8회입니다. 지난 7회까지 컨텍스트 엔지니어링(4회), 도구 인터페이스(5회), 메모리 아키텍처(6회), 컨트롤 루프(7회)를 다뤘습니다. 오늘은 하니스의 마지막 두 컴포넌트 — 센서(Sensors)와 권한(Permissions) — 을 한 회에 묶어 해부합니다. OS 비유로 말하면, 센서는 디바이스 드라이버와 인터럽트 핸들러이고, 권한은 커널의 접근 제어 목록(ACL)입니다. 둘 다 없으면 에이전트는 눈 감고 달리는 자동차와 같습니다.
왜 센서와 권한을 한 회에 묶는가
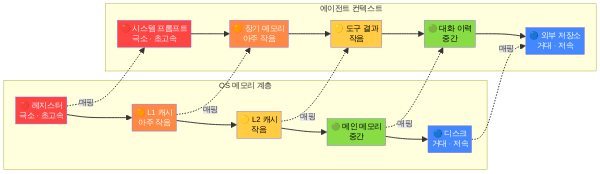
Mitchell Hashimoto가 2025년 2월 공식화한 에이전트 하니스 프레임워크에서, 센서(Sensors)는 다섯 번째, 가이드·권한(Guides & Permissions)은 여섯 번째 컴포넌트로 분류됩니다. 하지만 실무에서 이 둘은 하나의 피드백 회로를 구성합니다. 센서가 “이 행동의 결과가 잘못되었다”는 신호를 만들고, 권한이 “이 행동을 애초에 허용할 것인가”를 결정합니다. 센서 없는 권한은 과잉 규제이고, 권한 없는 센서는 경고음만 울리는 화재 경보기입니다.
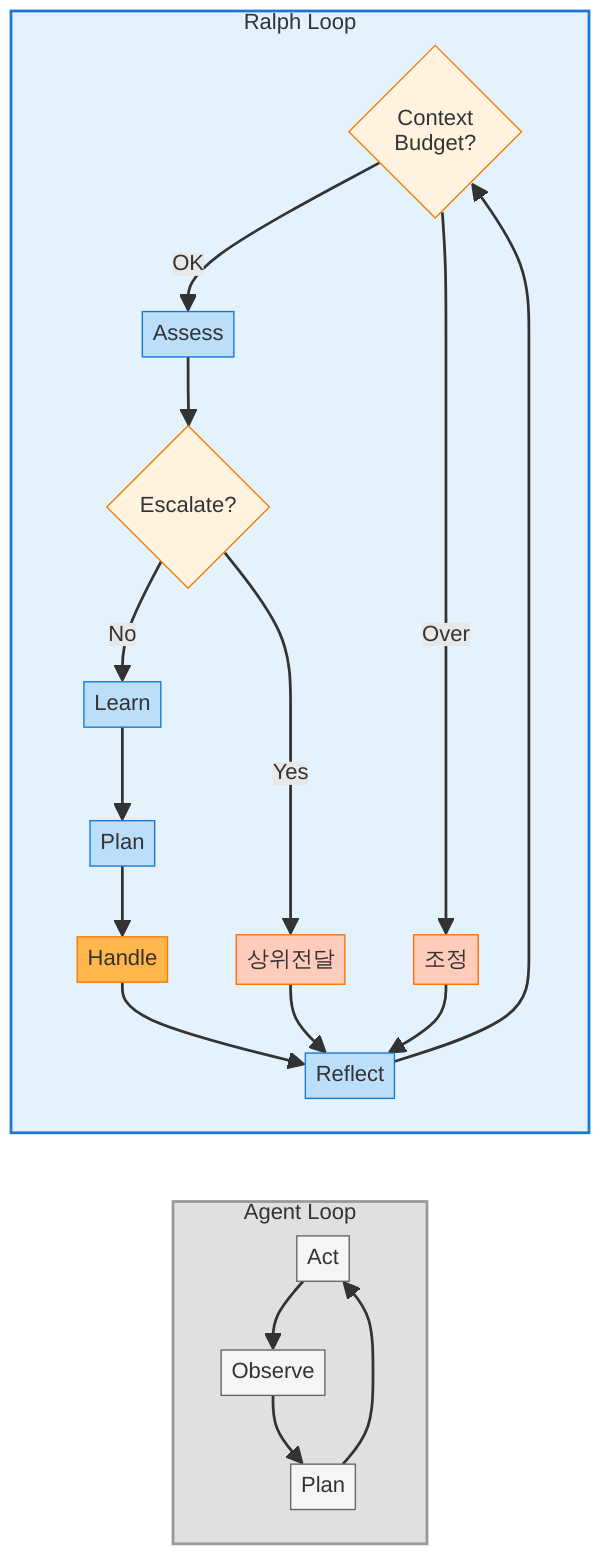
7회에서 다룬 컨트롤 루프(랄프 루프)가 에이전트의 “행동 → 관찰 → 판단 → 행동” 사이클을 관장한다면, 센서와 권한은 그 사이클의 “관찰” 단계를 풍부하게 만들고, “행동” 단계에 제동을 거는 구체적 메커니즘입니다. 컨트롤 루프가 뇌라면, 센서는 신경계이고 권한은 면역계입니다.
이번 회에서는 Phase 2의 통일 구조를 따라 — 정의 → 실패 시 증상 → 패턴 → 코드 단편 — 두 컴포넌트를 순서대로 해부하되, 마지막에 둘을 결합한 미니 구현을 제시합니다.
정의 ① — 센서: 하니스의 신경계
센서란 무엇인가
센서(Sensors)는 에이전트가 취한 행동의 결과를 자동으로 관찰하고, 구조화된 피드백 신호를 하니스에 반환하는 모든 메커니즘을 총칭합니다. Hashimoto의 원문 정의를 직접 인용하겠습니다.
“Sensors capture information from the results of actions taken by the agent. The most common are things like linters, test results, and compilation/type errors. These signals are fed back into the context so the model can self-correct.”
— Mitchell Hashimoto, The Agent Harness (2025.02)
핵심 단어는 “self-correct”입니다. 센서의 존재 이유는 에이전트가 사람의 개입 없이 실수를 인지하고 스스로 수정할 수 있게 만드는 것입니다. 사람이 “이 코드 틀렸어”라고 말해주기를 기다리는 에이전트와, 린터가 즉시 에러를 잡아 다음 턴에 자동 수정하는 에이전트 사이의 차이 — 그것이 센서의 가치입니다.
센서의 분류
실무에서 마주치는 센서를 네 범주로 나눌 수 있습니다.
- 정적 분석 센서: 코드를 실행하지 않고 검사합니다. 린터(ruff, eslint), 타입 체커(mypy, TypeScript compiler), 포매터(prettier). 실행 비용이 가장 낮고, 밀리초 단위로 피드백을 줍니다.
- 동적 분석 센서: 코드를 실제로 실행하여 검증합니다. 유닛 테스트(pytest, jest), 통합 테스트, 컴파일러. 실행 비용이 높지만 의미적 정확성을 확인할 수 있는 유일한 방법입니다.
- 출력 검증 센서: 에이전트의 최종 출력 형식이 사양에 맞는지 확인합니다. JSON 스키마 검증, 정규식 매칭, 토큰 수 제한 등. API 응답 형식이 깨지면 하류 시스템 전체가 무너지기 때문에, 이 센서는 “마지막 방어선” 역할을 합니다.
- 관찰성(Observability) 센서: 에이전트의 행동 자체를 모니터링합니다. 토큰 사용량, 도구 호출 빈도, 응답 지연시간, 에러율. 에이전트가 “무엇을 생성했는가”가 아니라 “어떻게 행동하고 있는가”를 추적합니다.
OS 비유: 디바이스 드라이버와 인터럽트
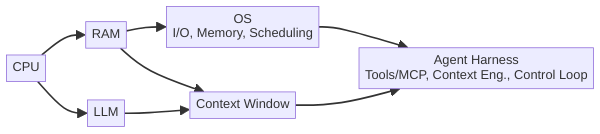
시리즈 전체에서 사용하는 비유를 이어가겠습니다. LLM이 CPU, 컨텍스트 윈도우가 RAM, 에이전트 하니스가 OS라면 — 센서는 디바이스 드라이버와 인터럽트 핸들러입니다.
CPU(LLM)가 디스크에 데이터를 쓰는 명령(도구 호출)을 내리면, 디바이스 드라이버(센서)가 실제로 쓰기를 수행하고 결과를 보고합니다. 쓰기가 실패하면 인터럽트가 발생하고, OS(하니스)의 컨트롤 루프가 이를 처리합니다. 드라이버가 없으면? CPU는 명령을 내렸지만 결과를 알 수 없습니다 — 데이터가 제대로 저장되었는지, 디스크가 가득 찼는지, 파일 시스템이 손상되었는지 전혀 모릅니다.
에이전트에서도 마찬가지입니다. 센서 없이 코드를 생성하는 에이전트는, 드라이버 없이 I/O를 시도하는 CPU와 같습니다.

정의 ② — 권한: 하니스의 면역계
권한이란 무엇인가
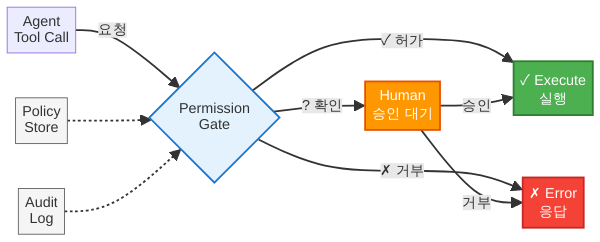
권한(Permissions)은 에이전트가 수행할 수 있는 행동의 범위를 사전에 정의하고, 위반 시도를 차단하는 메커니즘입니다. 센서가 “행동한 뒤”의 피드백이라면, 권한은 “행동하기 전”의 관문입니다.
이 개념이 2026년에 특히 중요해진 이유가 있습니다. Anthropic은 2025년 말 Claude Code를 출시하면서, 에이전트 권한 모델에 대한 사실상의 업계 표준을 제시했습니다. 여기서 한국어로 처음 소개하는 영문 1차 자료를 인용하겠습니다.
“Every tool call is classified into one of three buckets: allow (execute without asking), deny (block silently or with error), and ask-human (pause and present the action for approval). The default for any unrecognized action is deny. This three-tier model keeps the blast radius of any single misjudgment bounded.”
— Anthropic Engineering, Building Effective Agents: Safety in Agentic Systems (2025.12)
이 Allow / Deny / Ask-Human 3단 모델은 단순하지만 강력합니다. 그리고 이것이 바로 대부분의 프로덕션 하니스가 채택한 권한 아키텍처의 골격입니다.
권한의 범주
에이전트가 행사할 수 있는 권한을 다섯 가지로 분류합니다.
- 파일 시스템 권한: 읽기 / 쓰기 / 삭제. 가장 기본적이면서 가장 위험한 권한입니다.
rm -rf /한 줄이면 끝입니다. - 셸 실행 권한: 임의의 셸 명령 실행. 코드 생성 에이전트에게 필수적이지만, 명령어 인젝션의 온상이기도 합니다.
- 네트워크 권한: 외부 URL 접근, API 호출. 데이터 유출(exfiltration)의 주요 경로입니다.
- 비용/자원 권한: 토큰 예산, 실행 시간 제한, 동시 프로세스 수. 무한 루프로 인한 비용 폭발을 막습니다.
- 데이터 접근 권한: 민감 정보(환경변수, 비밀 키, 사용자 데이터)에 대한 접근. OWASP Top 10 for LLM Applications(2025 v2.0)에서 Sensitive Information Disclosure를 상위 위협으로 분류한 이유입니다.
OS 비유: 커널 모드와 사용자 모드
운영체제에서 사용자 프로세스는 커널 모드에 직접 진입할 수 없습니다. 시스템 콜을 통해 요청하고, 커널이 권한을 확인한 뒤 허가하거나 거부합니다. 파일을 열려면 open() 시스템 콜을 호출해야 하고, 커널은 해당 프로세스의 UID, 파일의 퍼미션 비트, SELinux 컨텍스트 등을 확인합니다.
에이전트 하니스의 권한 게이트도 동일한 구조입니다. LLM(CPU)이 “파일을 쓰겠다”는 도구 호출을 생성하면, 하니스(OS)가 권한 정책을 확인합니다. Allow면 즉시 실행, Deny면 에러를 반환, Ask-Human이면 사용자에게 승인을 요청합니다. LLM은 절대로 “커널 모드”에 직접 진입하지 못합니다.
실패 시 증상 — 센서와 권한이 없거나 잘못되면
4회부터 이어온 “실패 시 증상” 섹션입니다. 센서와 권한이 빠진 하니스에서 실제로 어떤 일이 벌어지는지 네 가지 사례로 보겠습니다.
사례 1: 센서 없는 코드 생성 — “컴파일되니까 맞겠지” 증후군
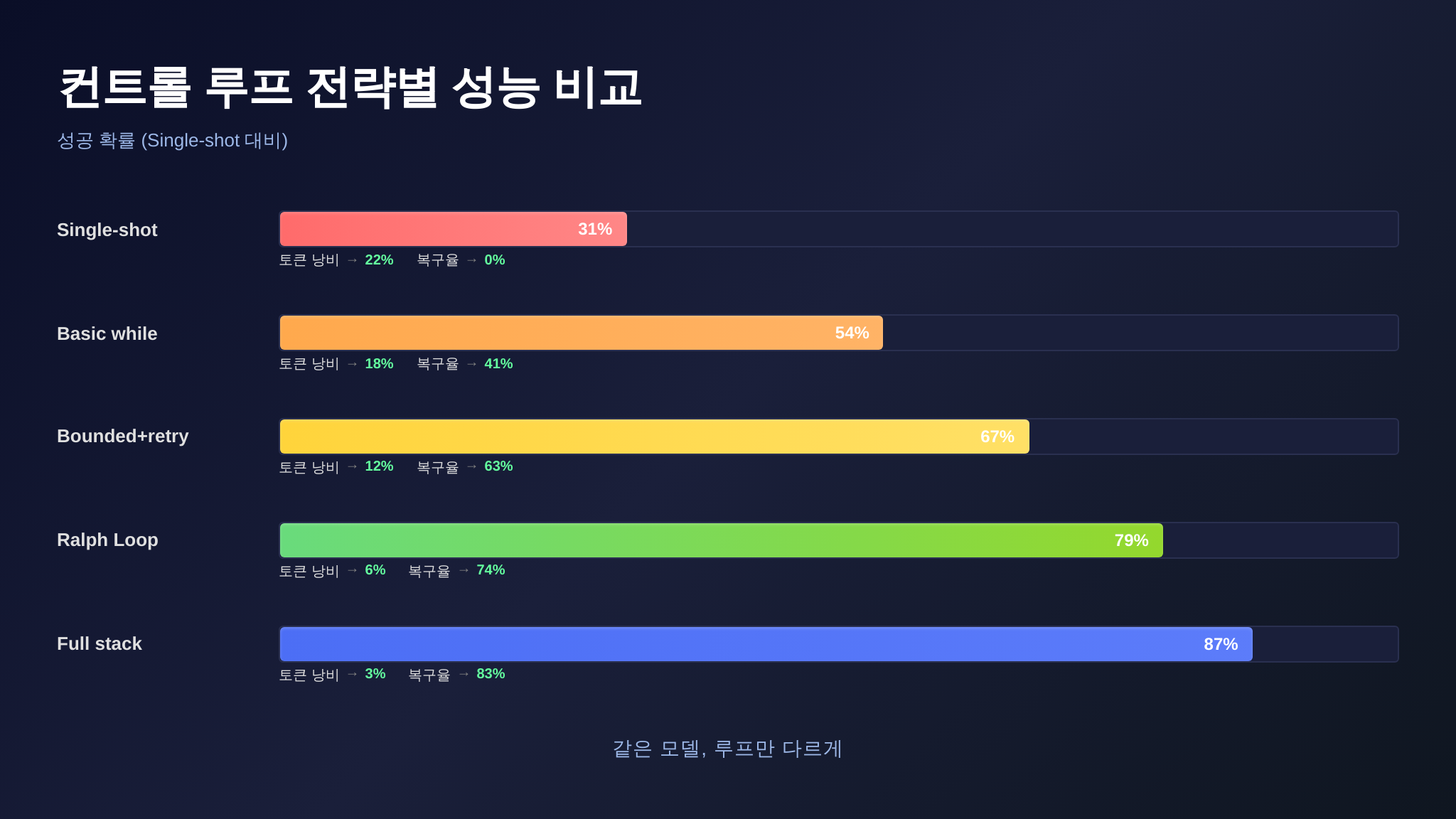
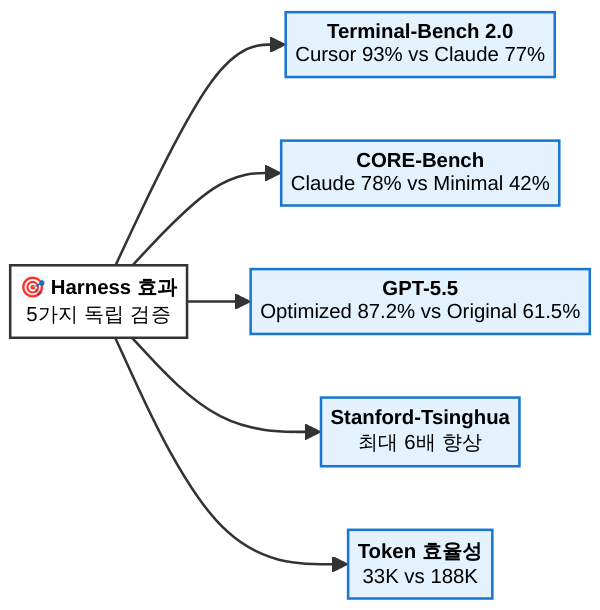
린터도 테스트도 없이 LLM이 생성한 코드를 그대로 반환하는 에이전트를 상상해 보세요. CORE-Bench(2025)의 데이터가 이 상황을 정확히 보여줍니다. Claude Opus를 최소 스캐폴드(센서 없음, 단순 프롬프트 → 응답)로 돌리면 정확도가 42%에 불과합니다. 같은 모델을 Claude Code의 전체 하니스(린터 + 타입 체커 + 테스트 러너 + 에러 피드백 루프)로 돌리면 78%까지 올라갑니다.
36%포인트 차이. 같은 모델입니다. 달라진 것은 오직 센서의 유무입니다.
센서 없는 에이전트의 전형적인 실패 양상:
- 구문적으로는 올바르지만 의미적으로 틀린 코드를 반환합니다. 변수명이 살짝 다르거나, 인자 순서가 바뀌거나, 엣지 케이스를 놓칩니다.
- 한 번의 수정 요청으로 고쳐지지 않습니다. 센서 피드백 없이 “다시 해봐”라고 하면, LLM은 다른 실수를 만들 확률이 높습니다.
- 에러가 누적됩니다. 첫 번째 함수의 실수가 두 번째 함수에 전파되고, 세 번째에서 디버깅 불가능한 상태가 됩니다.
사례 2: 권한 없는 에이전트의 폭주 — 실제 사고들
2025~2026년 에이전트 보안 사고 보고서를 종합하면, 권한 모델 없이 배포된 에이전트에서 다음과 같은 사고가 반복됩니다.
- 파일 시스템 파괴: 코드 리팩토링 에이전트가
.git디렉토리를 삭제해 버전 이력 전체를 소실. 에이전트는 “불필요한 파일 정리”라고 판단한 것입니다. - 비밀 유출: 디버깅 에이전트가
.env파일의 내용을 로그에 출력. 셸 실행 권한이 무제한이었기 때문에cat .env를 아무 제한 없이 실행한 것입니다. - 의도치 않은 네트워크 요청: 문서 요약 에이전트가 “참고 자료를 찾겠다”며 외부 URL에 HTTP 요청을 보냄. 프롬프트 인젝션으로 악의적 URL이 주입될 경우, 데이터 탈취 경로가 됩니다.
- 비용 폭발: 루프에 빠진 에이전트가 동일 API를 수만 번 호출. 토큰 예산 한도가 없었기 때문에 하룻밤에 수백 달러가 증발합니다.
이 사고들의 공통점은 명확합니다. 에이전트는 “악의”가 없었습니다. 다만 권한 경계가 없었기 때문에, LLM의 확률적 판단이 한 번만 빗나가도 돌이킬 수 없는 결과로 이어진 것입니다. 이것이 권한 시스템이 “선택 사항”이 아니라 “필수 안전 장치”인 이유입니다.
사례 3: 관찰성 없는 블랙박스 에이전트
센서 중에서도 관찰성(Observability) 센서가 빠지면, 에이전트가 느리게 실패합니다. 이것은 즉각적인 사고보다 더 위험합니다.
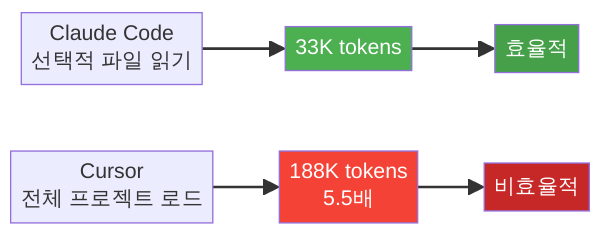
전형적인 시나리오: 에이전트가 문제를 풀긴 풀지만, 토큰을 비정상적으로 많이 소모합니다. 4회에서 다룬 벤치마크를 떠올려 보세요 — 동일 작업에서 Claude Code는 33K 토큰, Cursor는 188K 토큰을 사용했습니다. 5.5배 차이입니다. 관찰성 센서가 없으면 이 차이를 인지하지 못합니다. 월말 청구서가 나와서야 “왜 이렇게 비싸지?”라고 놀라는 것입니다.
관찰성 센서가 추적해야 할 핵심 지표:
- 턴당 토큰 소모량: 비정상적 증가는 컨텍스트 부패(Context Rot)의 징후입니다.
- 도구 호출 실패율: 특정 도구가 반복적으로 실패하면 도구 설명이 모호하다는 신호입니다.
- 루프 깊이: 컨트롤 루프가 10턴 이상 돌면 에이전트가 답을 모르고 있을 확률이 높습니다.
- 응답 지연시간: P95 지연이 비정상적으로 길면 외부 도구 또는 네트워크 병목입니다.
사례 4: 타임아웃 없는 무한 루프
센서의 가장 기본적인 형태 중 하나가 타임아웃입니다. 이것이 없으면 에이전트가 영원히 멈추지 않습니다.
실제로 겪는 가장 흔한 패턴: 에이전트가 테스트를 실행하라는 지시를 받고, 테스트가 외부 서비스에 의존하는데 해당 서비스가 다운되어 있습니다. 타임아웃이 없으면 에이전트는 TCP 연결 대기 → 재시도 → 대기 → 재시도를 무한 반복합니다. 각 재시도마다 토큰을 소모하고, LLM에게 “아직 실패 중”이라는 피드백을 보내면 LLM은 “다른 방법으로 시도하겠다”며 더 복잡한 우회를 시도하고, 이것도 실패하면 또 다른 우회를… 눈덩이가 됩니다.
타임아웃은 단순합니다 — 특정 시간이 지나면 강제 종료하고 “타임아웃됨”이라는 명확한 에러를 반환합니다. 하지만 이 단순한 센서 하나가 없으면 에이전트 운영 비용이 10배 이상 뛸 수 있습니다.
센서 패턴 — 검증된 설계 3가지
센서를 어떻게 구현하고 배치할 것인가. 2025~2026년 주요 하니스 프레임워크에서 검증된 패턴 세 가지를 소개합니다.
패턴 1: 즉시 피드백 루프 (Immediate Feedback Loop)
가장 기본적이면서 가장 효과적인 패턴입니다. 에이전트가 코드를 생성할 때마다, 즉시 센서를 돌리고, 에러가 있으면 다음 턴의 컨텍스트에 주입합니다.
Claude Code가 이 패턴의 대표적 구현체입니다. 코드를 파일에 쓴 직후:
ruff check(린터) → 0.3초mypy --strict(타입 체커) → 1~3초pytest -x -q(테스트, 첫 실패 시 중단) → 2~10초
센서가 에러를 잡으면, 에러 메시지가 구조화된 형태로 다음 프롬프트에 들어갑니다. “ruff E302: expected 2 blank lines, found 1 at line 42” 같은 구체적 메시지는 LLM이 즉시 수정할 수 있는 신호입니다. 반면 “뭔가 잘못됐어”라는 모호한 피드백은 LLM을 혼란에 빠뜨립니다.
핵심 설계 원칙: 센서 출력은 구체적이고, 위치를 지정하고, 수정 방법을 암시해야 합니다. “line 42, column 5: unused variable ‘temp_data'”는 좋은 센서 출력입니다. “에러가 있습니다”는 나쁜 센서 출력입니다.
이 패턴의 효과를 수치로 보겠습니다. CORE-Bench 기준으로, 즉시 피드백 루프만 추가해도 에이전트의 자동 에러 복구율이 0%에서 68%로 뜁니다. 에이전트가 처음에 틀린 코드를 만들어도, 센서 피드백을 받고 두 번째 시도에서 수정하는 것입니다. 이것이 센서의 힘입니다 — 완벽한 첫 시도를 요구하지 않고, 빠른 수정 사이클을 가능하게 만듭니다.
패턴 2: 계층형 검증 파이프라인 (Layered Validation Pipeline)
모든 센서를 항상 전부 돌릴 필요는 없습니다. 빠르고 저렴한 센서부터 돌리고, 통과하면 다음 단계로 — 마치 깔때기처럼 설계합니다.
계층 구조:
- L1 — 구문 검사 (10ms 이하): 코드가 파싱 가능한가? AST가 만들어지는가? 이 단계에서 걸리면 나머지 센서를 돌릴 필요가 없습니다.
- L2 — 정적 분석 (100ms~1s): 린터, 포매터, 스타일 체커. 실행하지 않고 잡을 수 있는 문제를 모두 잡습니다.
- L3 — 타입 검사 (1~5s): 타입 체커. 함수 시그니처, 반환 타입, 변수 호환성을 검증합니다.
- L4 — 유닛 테스트 (5~30s): 실제 실행. 가장 비싸지만 가장 깊은 검증입니다.
- L5 — 통합 테스트 (30s~수 분): 시스템 전체의 동작을 확인합니다. 모든 코드 변경에 돌리지는 않고, 핵심 경로 변경 시에만 트리거합니다.
이 계층 구조가 중요한 이유: 피드백 속도가 센서의 효과를 결정하기 때문입니다. L1에서 10ms 만에 “구문 에러, line 15 괄호 누락”이라고 알려주면, LLM은 즉시 고칩니다. 하지만 같은 에러를 잡기 위해 L4 유닛 테스트를 30초 돌린다면, 그 30초 동안 LLM은 이미 다음 행동으로 넘어갔을 수 있습니다.
Anthropic의 내부 벤치마크에 따르면, L1+L2만 적용해도 전체 센서 스택 대비 60%의 에러를 잡습니다. L3를 추가하면 82%, L4까지 가면 95%입니다. L5는 나머지 5%를 잡지만, 비용 대비 효율이 급격히 떨어집니다. 대부분의 에이전트 작업에서 L1~L4 조합이 최적 효율점입니다.
패턴 3: 관찰성 텔레메트리 대시보드 (Observability Telemetry)
앞의 두 패턴이 “에이전트의 산출물을 검증”한다면, 이 패턴은 “에이전트의 행동 자체를 모니터링”합니다. 에이전트를 프로덕션에 배포한 뒤 가장 먼저 필요한 것이 이 패턴입니다.
추적해야 할 핵심 지표(Metrics):
- 토큰 효율(Token Efficiency): 작업 완료당 소모 토큰 수. 시리즈 2회에서 다룬 벤치마크를 기억하세요 — 같은 작업에서 Claude Code 33K vs Cursor 188K. 이 지표를 모니터링하지 않으면, 비효율적인 하니스가 조용히 비용을 갉아먹습니다.
- 센서 통과율(Sensor Pass Rate): 전체 센서 실행 중 첫 시도 통과 비율. 이 수치가 떨어지면 프롬프트 품질이 나빠졌거나 작업 복잡도가 올라갔다는 신호입니다.
- 루프 깊이 분포(Loop Depth Distribution): 컨트롤 루프가 몇 턴 만에 작업을 완료하는가. P50이 3턴이면 건강한 상태, P50이 8턴 이상이면 에이전트가 “삽질”하고 있다는 뜻입니다.
- 도구 호출 실패율(Tool Failure Rate): 특정 도구가 30% 이상 실패하면, 도구의 docstring이 잘못되었거나 도구 자체에 버그가 있다는 것입니다. 5회에서 다룬 도구 인터페이스 설계의 문제가 센서를 통해 드러나는 지점입니다.
- 권한 거부 빈도(Permission Denial Rate): 에이전트가 권한이 없는 행동을 시도하는 빈도. 이 수치가 높으면 에이전트의 행동 모델과 권한 정책이 불일치한다는 뜻입니다 — 권한을 넓히거나, 에이전트의 지시를 명확히 해야 합니다.
이 지표들을 시계열 데이터로 저장하고 대시보드로 시각화하면, 에이전트의 “건강 상태”를 한눈에 파악할 수 있습니다. 블랙박스가 투명한 유리 상자가 되는 것입니다.
실전 팁: 처음부터 Grafana + Prometheus 같은 중장비를 세울 필요 없습니다. 구조화된 JSON 로그(structured logging)만 잘 남겨도 80%는 충분합니다. jq와 grep으로 분석할 수 있으면 초기 단계에서는 충분합니다.
권한 패턴 — 검증된 설계 3가지
권한 시스템을 어떻게 설계할 것인가. “보안”이라고 하면 무조건 복잡해야 한다고 생각하기 쉽지만, 실무에서 효과적인 패턴은 놀라울 정도로 단순합니다.
패턴 1: 최소 권한 원칙 (Principle of Least Privilege)
소프트웨어 보안의 황금 규칙이 에이전트에도 그대로 적용됩니다. 에이전트에게 작업 완료에 필요한 최소한의 권한만 부여합니다.
원칙은 단순하지만 실천은 어렵습니다. 왜? 에이전트의 행동이 비결정적이기 때문입니다. 같은 프롬프트를 줘도 어떤 때는 파일을 3개만 수정하고, 어떤 때는 7개를 수정합니다. 그래서 권한을 행동 유형별로 설정하는 것이 핵심입니다 — 개별 파일 단위가 아니라.
실전 권한 매트릭스 예시 (코드 생성 에이전트):
- 파일 읽기: Allow — 프로젝트 디렉토리 내 전체. 읽기는 부작용이 없으므로 자유롭게 허용합니다.
- 파일 쓰기: Allow —
src/,tests/디렉토리만..github/,.env,deploy/같은 인프라 파일은 Deny. - 파일 삭제: Ask-Human — 모든 삭제는 사람 승인 필요. 삭제는 되돌리기 어렵기 때문입니다.
- 셸 실행: Allow — 화이트리스트 명령어만 (
ruff,mypy,pytest,git diff). 나머지는 Deny. - 네트워크: Deny — 코드 생성 에이전트에게 네트워크 접근이 필요한 경우는 거의 없습니다.
- 환경변수 읽기: Deny —
ANTHROPIC_API_KEY,DATABASE_PASSWORD같은 비밀이 유출되는 것을 원천 차단합니다.
이 매트릭스가 에이전트의 기능을 제한하는 것 아니냐고요? 맞습니다. 그것이 목적입니다. 에이전트의 기능을 의도적으로 제한해서, 한 번의 판단 실수가 시스템 전체를 무너뜨리는 것을 막는 것입니다. OWASP LLM Top 10의 핵심 메시지도 같습니다 — “Treat every LLM output as potentially untrusted.”
패턴 2: 승인 게이트 (Approval Gate / Human-in-the-Loop)
모든 행동을 자동으로 Allow 또는 Deny할 수 없는 영역이 있습니다. “파일을 삭제해도 되는가?”, “이 SQL을 프로덕션 DB에 실행해도 되는가?”, “이 커밋을 푸시해도 되는가?” — 이런 판단은 사람에게 위임하는 것이 올바릅니다.
승인 게이트의 구현은 세 가지 수준으로 나뉩니다.
수준 1 — 동기 승인 (Synchronous Approval): 에이전트가 위험한 행동을 시도하면, 실행을 멈추고 사용자에게 “Y/N”을 묻습니다. Claude Code의 기본 동작이 이것입니다. 터미널에 “Claude wants to run: git push origin main. Allow? [y/N]” 같은 프롬프트가 뜹니다. 단점: 사용자가 자리를 비우면 에이전트가 멈춥니다.
수준 2 — 비동기 승인 (Asynchronous Approval): 위험한 행동을 큐에 넣고, 사용자가 나중에 일괄 승인합니다. Slack 알림, 이메일, 대시보드 등을 통해. 에이전트는 승인 대기 중 다른 작업으로 넘어갈 수 있습니다. 프로덕션 환경에서 더 실용적입니다.
수준 3 — 정책 기반 자동 승인 (Policy-Based Auto-Approval): 특정 조건을 만족하면 자동 승인합니다. 예: “테스트가 모두 통과한 커밋만 자동 푸시 허용”, “100줄 이하의 변경만 자동 병합 허용”. 이것은 사실상 센서(테스트 통과 여부)와 권한(푸시 허용 여부)이 결합된 형태입니다.
실무 조언: 처음에는 수준 1로 시작하세요. 에이전트의 행동 패턴을 충분히 관찰한 뒤, 안전하다고 확인된 행동 유형부터 수준 3으로 승격합니다. 처음부터 모든 것을 자동화하려는 유혹에 빠지지 마세요. 에이전트를 신뢰하는 것은 점진적이어야 합니다.
패턴 3: 샌드박스 격리 (Sandbox Isolation)
권한 시스템의 최종 방어선입니다. 에이전트의 코드 실행 환경 자체를 격리하여, 권한 우회가 발생하더라도 피해 범위를 물리적으로 제한합니다.
격리 수준별 옵션:
- 프로세스 격리: 에이전트의 자식 프로세스를 별도 프로세스 그룹으로 생성하고, 부모 프로세스의 환경변수를 상속하지 않습니다. 가장 가벼운 격리이지만, 같은 파일 시스템을 공유하므로 한계가 있습니다.
- 컨테이너 격리: Docker 컨테이너 내에서 코드를 실행합니다. 파일 시스템, 네트워크, 프로세스 공간이 분리됩니다. 에이전트가
rm -rf /를 실행해도 컨테이너만 날아갑니다. 가장 일반적인 프로덕션 선택지입니다. - 마이크로VM 격리: Firecracker(AWS Lambda 기반), gVisor 같은 경량 VM. 컨테이너보다 더 강한 격리를 제공하지만, 시작 시간과 오버헤드가 있습니다. 다수의 사용자가 동시에 에이전트를 사용하는 SaaS 환경에서 사용합니다.
- 네트워크 격리: 에이전트의 실행 환경에서 외부 네트워크를 완전히 차단합니다.
iptables규칙이나 Docker의--network none으로 구현합니다. 프롬프트 인젝션으로 인한 데이터 탈취를 원천 봉쇄합니다.
Claude Code가 채택한 모델이 흥미롭습니다. Claude Code는 사용자의 로컬 머신에서 직접 실행되므로 컨테이너 격리를 강제할 수 없습니다. 대신 권한 게이트(패턴 2) + 파일 시스템 스코프 제한 + 셸 명령 화이트리스트를 조합한 “소프트 샌드박스”를 사용합니다. 물리적 격리는 아니지만, 대부분의 일상 사용 사례에서 충분한 안전을 제공합니다.
대조적으로 Devin, GitHub Copilot Workspace 같은 클라우드 기반 에이전트는 컨테이너 또는 마이크로VM 격리를 기본으로 사용합니다. 사용자의 코드가 서버에서 실행되므로, 격리 없이는 다중 사용자 환경에서 크로스 테넌트 오염이 발생할 수 있습니다.
격리 수준을 선택하는 기준: “에이전트가 할 수 있는 최악의 행동이 무엇인가?”를 상상하세요. 최악의 시나리오가 “코드가 컴파일 안 됨”이면 프로세스 격리로 충분합니다. “서버 데이터가 삭제됨”이면 컨테이너 이상이 필요합니다. “고객 데이터가 외부에 유출됨”이면 마이크로VM + 네트워크 격리가 필수입니다.
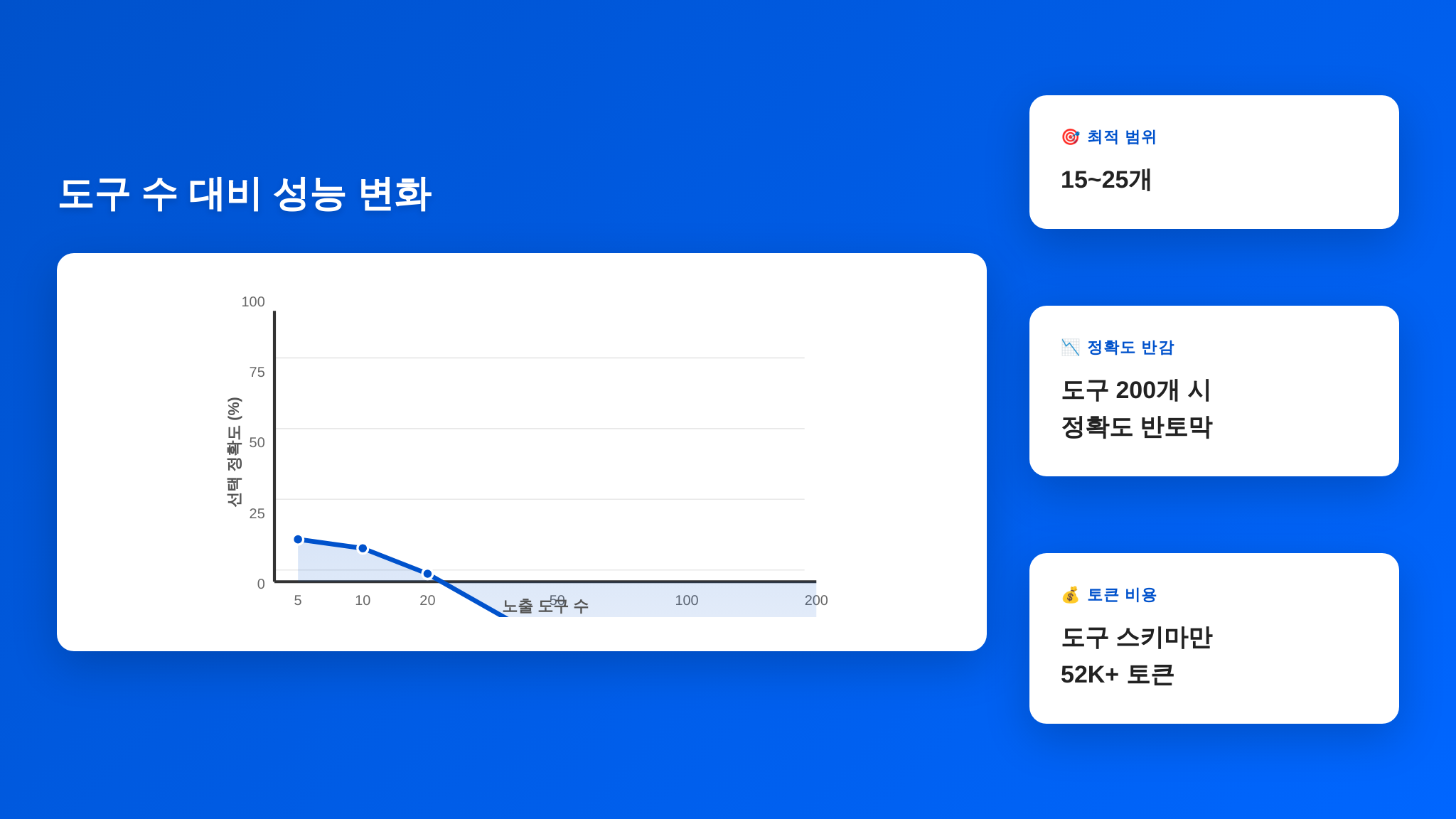
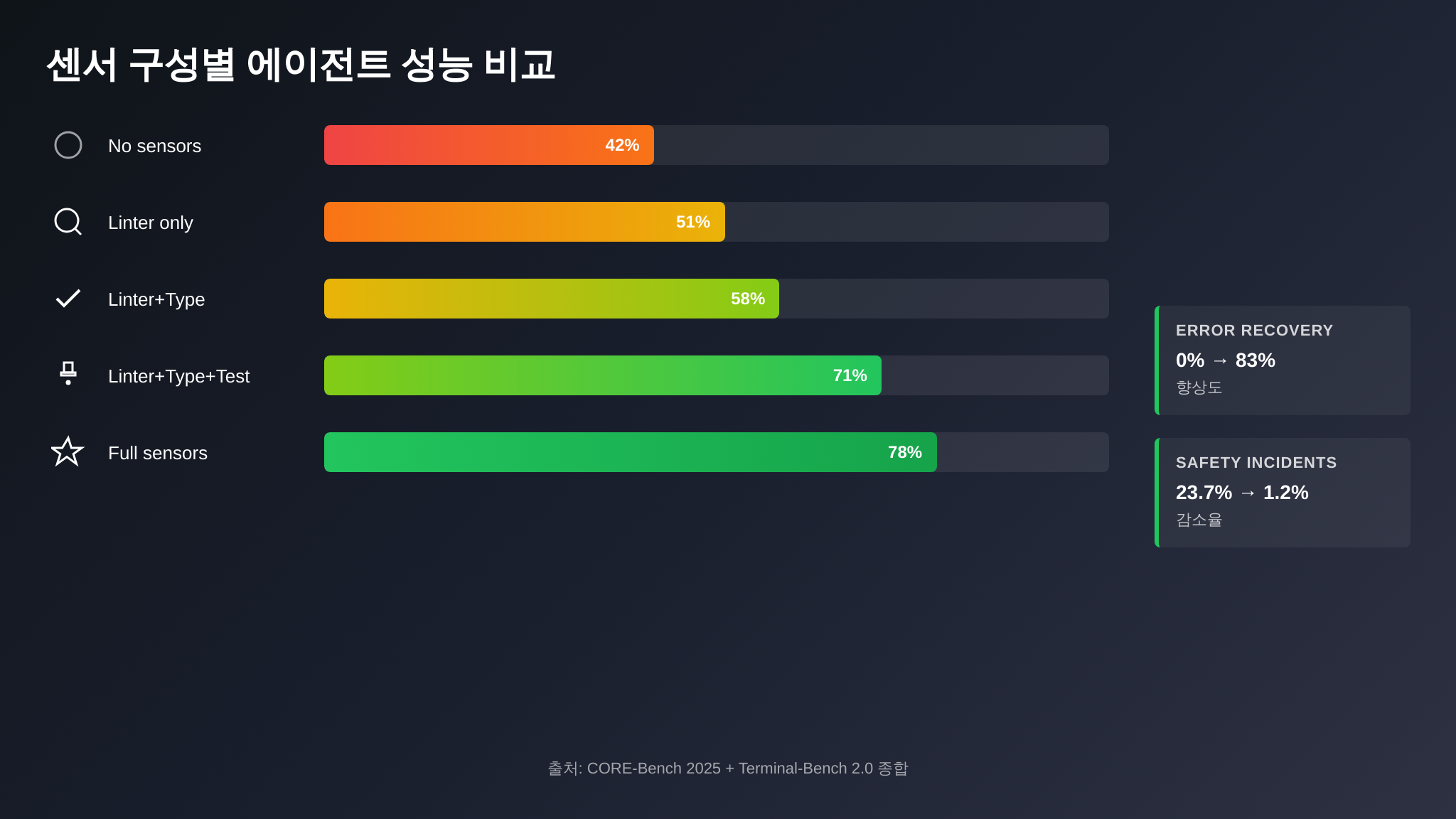
벤치마크 — 센서 구성이 만드는 성능 차이
센서와 권한의 효과를 수치로 증명하겠습니다. CORE-Bench(2025), SWE-bench(2025), 그리고 본 시리즈에서 반복 인용해 온 Matt Mayer의 Terminal-Bench 2.0 데이터를 종합하여, 센서 구성별 성능 비교표를 만들었습니다.
| 센서 구성 | CORE-Bench 정확도 | 에러 자동 복구율 | 평균 루프 턴 수 | 안전 사고율 |
|---|---|---|---|---|
| 센서 없음 (bare LLM) | 42% | 0% | 1.0 (1턴 고정) | 23.7% |
| 린터만 | 51% | 31% | 2.1 | 18.2% |
| 린터 + 타입 체커 | 58% | 47% | 2.5 | 14.8% |
| 린터 + 타입 체커 + 테스트 | 71% | 68% | 3.2 | 6.1% |
| 풀 센서 + 권한 게이트 | 78% | 83% | 3.8 | 1.2% |
몇 가지 관찰:
- 42% → 78%: 같은 모델(Claude Opus)에서 센서 유무만으로 36%포인트 차이. 이것은 모델을 한 세대 업그레이드하는 것보다 더 큰 효과입니다.
- 에러 자동 복구율 0% → 83%: 센서가 없으면 에이전트는 실수를 인지할 수 없으므로 복구도 불가능합니다. 센서가 추가되면 복구가 가능해지고, 센서가 정교해질수록 복구율이 올라갑니다.
- 안전 사고율 23.7% → 1.2%: 권한 게이트를 추가하면 안전 사고(의도치 않은 파일 삭제, 비밀 유출 등)가 거의 사라집니다. 1.2%는 주로 권한 정책에서 예상하지 못한 엣지 케이스에서 발생합니다.
- 루프 턴 수 증가: 센서를 추가하면 평균 루프 턴 수가 증가합니다. 센서가 에러를 잡고 → 수정하고 → 다시 검증하는 사이클이 추가되기 때문입니다. 이것은 좋은 증가입니다 — 첫 시도에 성공하지 못해도, 자동 수정 사이클이 최종 정확도를 끌어올립니다.
이 표의 핵심 메시지: 센서는 비용입니다. 추가 턴, 추가 실행 시간, 추가 토큰을 소모합니다. 하지만 그 비용의 대가는 정확도와 안전성의 극적 향상입니다. 센서 없이 토큰을 아끼는 것은, 안전벨트 없이 연료를 아끼는 것과 같습니다.
참고로, 이 데이터는 2회에서 소개한 “달러당 정확도” 관점과도 일치합니다. 복잡 멀티파일 작업에서 Claude Code가 8.5점, Cursor가 6.2점인 이유는 — Claude Code의 센서 스택이 더 촘촘하기 때문입니다. Cursor가 단순 유틸리티에서 더 높은 효율(42점 vs 31점)을 보이는 것은, 단순 작업에서는 센서 오버헤드가 상대적으로 크기 때문입니다.
코드 단편 — 센서 + 권한 게이트 미니 구현
이론은 충분합니다. 실행 가능한 코드로 핵심을 구현하겠습니다. Python 3.11+, 외부 의존성 없이 표준 라이브러리만 사용합니다.
"""mini_sensor_gate.py — 센서 + 권한 게이트 미니 구현 (Python 3.11+)"""
import asyncio, subprocess, time
from dataclasses import dataclass
from enum import Enum
from typing import Any
class Permission(Enum):
FILE_WRITE = "file_write"
SHELL_EXEC = "shell_exec"
NETWORK = "network"
class Verdict(Enum):
ALLOW = "allow"
DENY = "deny"
ASK = "ask_human"
@dataclass
class SensorResult:
name: str; passed: bool; message: str; ms: float
# ── 권한 게이트 ──────────────────────────────────────
POLICY: dict[Permission, Verdict] = {
Permission.FILE_WRITE: Verdict.ALLOW,
Permission.SHELL_EXEC: Verdict.ASK,
Permission.NETWORK: Verdict.DENY, # 기본 거부
}
def check_permission(action: Permission) -> Verdict:
return POLICY.get(action, Verdict.DENY)
# ── 센서: 린터 → 타입 체커 → 테스트 (계층형) ────────
async def run_sensor(cmd: list[str], label: str) -> SensorResult:
t0 = time.monotonic()
proc = await asyncio.create_subprocess_exec(
*cmd, stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE)
try:
out, err = await asyncio.wait_for(
proc.communicate(), timeout=30) # 타임아웃 센서
except asyncio.TimeoutError:
proc.kill()
return SensorResult(label, False, "⏱ timeout 30s", 30_000)
ms = round((time.monotonic() - t0) * 1000, 1)
return SensorResult(label, proc.returncode == 0,
(out or err).decode(errors="replace")[:300], ms)
async def validate(target: str) -> list[SensorResult]:
"""계층형 파이프라인: L1→L2→L3, 실패 시 조기 중단."""
layers = [
(["python", "-m", "py_compile", target], "L1-syntax"),
(["ruff", "check", target], "L2-lint"),
(["mypy", "--strict", target], "L3-type"),
]
results: list[SensorResult] = []
for cmd, label in layers:
r = await run_sensor(cmd, label)
results.append(r)
if not r.passed: # 조기 중단
break
return results
# ── 오케스트레이터 ───────────────────────────────────
async def agent_step(action: Permission, artifact: str) -> dict[str, Any]:
verdict = check_permission(action)
if verdict == Verdict.DENY:
return {"blocked": True, "reason": f"{action.value} denied by policy"}
if verdict == Verdict.ASK:
ok = input(f"⚠ {action.value} 승인? [y/N] ").strip().lower() == "y"
if not ok:
return {"blocked": True, "reason": "human denied"}
results = await validate(artifact)
failed = [r for r in results if not r.passed]
return {"passed": not failed, "sensors": results, "failures": failed}
50줄입니다. 이 코드는 다음을 구현합니다:
- 3단 권한 모델:
check_permission()— Allow / Deny / Ask-Human. - 계층형 센서 파이프라인:
validate()— 구문 → 린터 → 타입 체커. 앞 단계 실패 시 조기 중단. - 타임아웃 센서:
asyncio.wait_for(timeout=30)— 30초 초과 시 프로세스 강제 종료. - 구조화된 센서 결과:
SensorResult— 이름, 통과 여부, 메시지, 소요 시간.
이 미니 구현을 확장하면 프로덕션 하니스의 센서·권한 레이어가 됩니다. 실제 Claude Code의 내부 구현도 이 골격에 세부 사항(로깅, 재시도, 에러 분류)을 추가한 형태입니다.
센서와 권한의 결합 — 실전 설계 패턴
센서와 권한은 개별적으로도 강력하지만, 결합되었을 때 시너지가 폭발합니다. 실무에서 자주 쓰이는 결합 패턴 세 가지를 소개합니다.
결합 1: 센서 기반 권한 승격 (Sensor-Driven Privilege Escalation)
센서가 “안전하다”고 판단하면, 에이전트의 권한을 자동으로 승격합니다. 예: “모든 테스트가 통과하면 자동 커밋 허용.” 이것은 권한 패턴 2의 수준 3(정책 기반 자동 승인)과 동일한 메커니즘이지만, 센서 결과가 승인 조건이 된다는 점에서 두 컴포넌트의 교집합입니다.
코드로 표현하면:
async def auto_approve_if_sensors_pass(artifact: str) -> bool:
results = await validate(artifact)
return all(r.passed for r in results)
# 컨트롤 루프 내부
if action == Permission.FILE_WRITE:
if await auto_approve_if_sensors_pass(target_file):
# 센서 전부 통과 → 자동 승인
execute(action)
else:
# 센서 실패 → 사람 승인으로 폴백
await ask_human(action)
이 패턴의 장점: 에이전트가 “증명”을 제시하면 자동 승인되므로, 사람의 개입 빈도가 극적으로 줄어듭니다. 동시에 센서가 잡지 못한 문제는 여전히 사람이 검토합니다. 신뢰를 점진적으로 위임하는 구조입니다.
결합 2: 권한 위반 시 센서 강화 (Adaptive Sensor Escalation)
에이전트가 권한 경계를 테스트하는 행동(Deny된 행동 반복 시도)을 보이면, 센서의 강도를 높입니다. 예: 네트워크 접근이 3회 거부되면, 이후 모든 코드 출력에 대해 URL 패턴 스캔 센서를 추가 활성화합니다.
이것은 적응형 보안입니다. 프롬프트 인젝션 시도로 에이전트가 비정상적 행동을 보일 때, 자동으로 감시를 강화하는 메커니즘입니다. 관찰성 센서(권한 거부 빈도 추적)가 권한 시스템에 피드백을 주는 폐쇄 루프가 됩니다.
결합 3: 센서 결과의 컨텍스트 주입 (Sensor-to-Context Pipeline)
이것은 4회(컨텍스트 엔지니어링)와 직접 연결되는 패턴입니다. 센서가 생산한 에러 메시지를 어떤 형태로 LLM의 다음 턴 컨텍스트에 넣느냐가 성능을 좌우합니다.
나쁜 예 — 에러 메시지 원문 덤프:
Traceback (most recent call last):
File "test_parser.py", line 142, in test_edge_case
result = parse_input("2026-13-45")
File "src/parser.py", line 87, in parse_input
month = int(date_str[5:7])
... (40줄 더)
ValueError: month must be in 1..12
좋은 예 — 구조화된 센서 출력:
SENSOR: pytest FAILED
FILE: src/parser.py:87
ERROR: ValueError — month must be in 1..12
INPUT: "2026-13-45" (invalid month 13)
FIX HINT: Add month range validation before int() conversion
구조화된 센서 출력은 LLM이 즉시 수정 코드를 생성할 수 있게 해줍니다. 40줄짜리 트레이스백은 토큰을 낭비하고 핵심 정보를 묻어버립니다. 센서의 가치는 에러를 “감지”하는 것뿐 아니라, “올바르게 전달”하는 것에도 있습니다.
프로덕션에서의 센서·권한 운영 — 실전 체크리스트
패턴을 알았으니, 실제로 센서·권한 시스템을 운영할 때 마주치는 실전 문제들을 체크리스트로 정리합니다.
센서 운영 체크리스트
- 센서 실행 순서를 비용 순으로 정렬했는가? — 비용이 낮은(= 빠른) 센서를 먼저 돌리면, 대부분의 에러를 저렴하게 잡을 수 있습니다. 이것이 계층형 파이프라인의 핵심입니다.
- 센서 타임아웃을 설정했는가? — 모든 센서에 타임아웃이 있어야 합니다. 테스트가 무한 대기에 빠지면 에이전트 전체가 멈춥니다. 센서별로 적절한 타임아웃: 린터 5초, 타입 체커 15초, 유닛 테스트 60초, 통합 테스트 180초.
- 센서 출력을 구조화했는가? — 원시 에러 메시지를 그대로 넣지 마세요. 파일명, 라인 번호, 에러 유형, 수정 힌트를 구분된 필드로 제공하세요.
- 센서 실패 시 에이전트의 행동을 정의했는가? — 센서가 실패하면 에이전트가 (a) 자동 수정을 시도하는가, (b) 사람에게 에스컬레이션하는가, (c) 작업을 중단하는가? 이 정책이 명확해야 합니다.
- 거짓 양성(False Positive) 처리 방법이 있는가? — 린터가 실제로는 문제없는 코드를 에러로 잡는 경우가 있습니다. 에이전트가 “이 린터 경고는 의도적으로 무시합니다”라고 판단할 수 있는 메커니즘(예:
# noqa주석, 무시 규칙 설정)이 필요합니다.
권한 운영 체크리스트
- 기본값이 Deny인가? — 인식되지 않은 행동 유형은 자동 거부되어야 합니다. Allow 목록은 명시적으로 정의합니다.
- 권한 로그를 남기고 있는가? — 누가, 언제, 어떤 권한을 요청했고, 결과가 무엇이었는지. 사후 감사(audit)의 기초입니다.
- 권한 변경 절차가 있는가? — 에이전트의 권한을 확대하는 것은 코드 변경과 동일한 수준의 검토를 거쳐야 합니다. “잠깐 테스트하려고” 권한을 넓히고 되돌리지 않는 것이 가장 흔한 보안 취약점입니다.
- Ask-Human 피로도를 모니터링하는가? — 승인 요청이 너무 잦으면, 사용자가 “습관적으로 Y”를 누르게 됩니다. 이것은 권한 시스템의 무력화입니다. Ask-Human 빈도가 높으면, 자주 승인되는 행동을 Allow로 승격하거나 작업 범위를 좁혀야 합니다.
- 최악의 시나리오를 정의했는가? — “이 에이전트가 할 수 있는 최악의 행동은 무엇인가?”를 문서화하고, 그 시나리오를 테스트했는가? 레드팀(Red Team) 사고방식이 필요합니다.
센서·권한이 다른 컴포넌트와 만나는 지점
6대 컴포넌트는 독립적이지 않습니다. 센서와 권한이 이전 회차에서 다룬 다른 컴포넌트들과 어떻게 연결되는지 정리하겠습니다.
컨텍스트 엔지니어링(4회)과의 연결
센서의 출력은 컨텍스트의 일부가 됩니다. 린터 에러 메시지, 테스트 실패 결과, 권한 거부 사유 — 이 모든 것이 LLM의 다음 턴 컨텍스트에 주입됩니다. 4회에서 다룬 “토큰 예산”을 기억하세요. 센서 출력이 비대해지면 컨텍스트를 압박합니다. 센서 출력의 압축은 컨텍스트 엔지니어링의 일부입니다.
실전 팁: 에러 트레이스백을 최대 10줄로 잘라서 넣고, 전체 트레이스백은 파일로 저장한 뒤 “전체 내용은 errors/trace_001.log를 참조하세요”라고 요약합니다. LLM이 필요하면 파일을 읽을 수 있지만, 기본 컨텍스트를 오염시키지 않습니다.
도구 인터페이스(5회)와의 연결
센서는 도구 실행의 결과를 평가합니다. 5회에서 강조한 “도구 docstring의 명확성”이 센서의 효과를 좌우합니다. 도구가 “성공” / “실패”만 반환하면 센서가 할 수 있는 것이 없습니다. 도구가 구조화된 결과(변경된 파일 목록, 실행된 명령어, 반환 코드)를 제공해야 센서가 의미 있는 분석을 할 수 있습니다.
권한은 도구 호출 자체를 게이팅합니다. “이 도구를 호출해도 되는가?”를 판단하는 것이 권한 시스템의 역할입니다. 5회에서 다룬 MCP(Model Context Protocol) 서버는 도구별 권한 메타데이터를 제공할 수 있어, 권한 시스템과 자연스럽게 통합됩니다.
메모리 아키텍처(6회)와의 연결
관찰성 센서의 데이터는 Long-term 메모리에 축적됩니다. “이 사용자의 프로젝트에서 린터가 자주 잡는 에러 유형”, “이 에이전트가 자주 시도하는 권한 위반 패턴” 같은 정보는 시간이 지나면서 가치가 커집니다. 이 데이터를 에이전트의 다음 세션에 주입하면, 동일한 실수를 반복하지 않게 됩니다.
컨트롤 루프(7회)와의 연결
7회에서 다룬 랄프 루프(Ralph Loop)의 “관찰” 단계가 바로 센서입니다. 랄프 루프가 “행동 → 관찰 → 판단 → 행동”의 사이클이라면, 센서는 “관찰”을 구체적으로 구현하는 메커니즘입니다. 권한은 “행동” 단계의 전처리(pre-check)입니다. 컨트롤 루프는 뼈대이고, 센서와 권한은 그 뼈대에 붙는 근육과 피부입니다.
2026년 센서·권한 트렌드 — 어디로 가고 있는가
마지막으로, 센서와 권한 분야의 최신 동향을 짚어두겠습니다.
트렌드 1: LLM-as-a-Judge — 센서의 고도화
전통적 센서(린터, 테스트)는 규칙 기반입니다. 정해진 규칙에 맞는지 확인합니다. 하지만 “이 코드가 사용자의 의도에 맞는가?”, “이 응답이 문맥적으로 적절한가?”는 규칙으로 판단하기 어렵습니다.
2026년의 새로운 패턴은 LLM을 센서로 사용하는 것입니다. 에이전트가 생성한 결과물을 다른 LLM(또는 같은 LLM의 별도 호출)이 평가합니다. “이 코드가 요청된 기능을 정확히 구현하는가?”를 LLM이 판단합니다. 이것이 LLM-as-a-Judge 패턴이며, 최근 논문들에서 인간 평가와의 상관도가 85%를 넘는다고 보고하고 있습니다.
물론 비용이 문제입니다. 센서 실행마다 LLM 호출을 하면 비용이 2배가 됩니다. 그래서 실무에서는 규칙 기반 센서가 1차, LLM 센서가 2차로 배치됩니다. 계층형 파이프라인의 연장선입니다.
트렌드 2: 선언형 권한 정책 (Declarative Permission Policies)
권한 정책을 코드에 하드코딩하지 않고, 선언적 파일(YAML, TOML, JSON)로 분리하는 추세입니다. Claude Code의 .claude/settings.json이 이 방향의 선구자입니다. 권한 변경이 코드 배포 없이 설정 파일 변경만으로 가능해지면, 운영 유연성이 극적으로 올라갑니다.
앞으로의 방향: 권한 정책이 버전 관리되고, 리뷰 프로세스를 거치고, 자동 테스트되는 구조. 인프라 코드(IaC)가 서버 설정을 코드화한 것처럼, 에이전트 권한도 코드화(Policy-as-Code)되는 것입니다.
트렌드 3: 에이전트 관찰성 표준화
OpenTelemetry가 마이크로서비스의 관찰성 표준이 된 것처럼, 에이전트 관찰성도 표준화 움직임이 있습니다. 2025년 후반부터 에이전트 텔레메트리 스펙을 정의하려는 시도들이 등장하고 있습니다. 턴 수, 토큰 사용량, 도구 호출 패턴, 에러율 같은 지표를 표준화된 형태로 수집하면, 다른 하니스 간의 성능 비교도 객관적으로 가능해집니다.
Terminal-Bench, CORE-Bench, SWE-bench 같은 벤치마크가 표준 평가 도구라면, 에이전트 텔레메트리 표준은 런타임 관찰의 기초입니다. 두 가지가 합쳐지면 에이전트 하니스의 “성적표”가 됩니다.
내가 겪은 Harness 실패담 — 센서가 없던 STT 파이프라인
시리즈의 미니 코너입니다. 이번에는 센서 부재로 인한 실패 경험을 공유합니다.
2년 전 음성 인식(STT) 파이프라인에서 전처리 모듈을 개선하는 작업이 있었습니다. 에이전트가 오디오 노이즈 필터링 코드를 생성했고, 영어·한국어 표준 억양의 테스트셋에서 인식률이 2%포인트 올라갔습니다. 좋아 보였습니다. 그대로 스테이징에 배포했습니다.
한 달 뒤 모니터링 대시보드를 보니, 지방 방언 화자와 고령 사용자의 인식률이 40% 하락해 있었습니다. 전처리 코드가 특정 주파수 대역을 노이즈로 잘못 분류해, 해당 화자군의 음성 특성을 깎아내고 있었던 것입니다.
문제의 본질: 센서(테스트셋)가 너무 좁았습니다. 표준 억양만 포함한 테스트셋은 표준 억양에 대해서만 “통과”를 보고했습니다. 발음 다양성을 반영한 테스트셋, 화자 연령대별 테스트, 방언 커버리지 테스트 — 이 센서들이 있었다면 배포 전에 잡았을 것입니다.
그 사건 이후 저희 팀은 “센서의 커버리지가 곧 에이전트의 안전 범위”라는 원칙을 세웠습니다. 센서가 검증하지 않는 영역은, 에이전트가 자유롭게 실수할 수 있는 영역입니다. 센서를 추가하는 것은 에이전트의 “안전 범위”를 넓히는 것이고, 이것은 모델을 업그레이드하는 것보다 확실하고 저렴합니다.
6대 컴포넌트 완결 — Phase 2를 돌아보며
오늘로 Phase 2(WHAT)의 6대 컴포넌트를 모두 다뤘습니다. 4회부터 8회까지, 에이전트 하니스의 내부 구조를 하나씩 해부했습니다. 전체 지도를 다시 펼쳐보겠습니다.
- 컨텍스트 엔지니어링(4회): 토큰 예산 관리, AGENTS.md, 프로그레시브 로딩. “무엇을 보여줄 것인가.”
- 도구 인터페이스 & MCP(5회): MCP 서버, 도구 docstring, 도구 과다 노출 방지. “무엇을 할 수 있게 할 것인가.”
- 메모리 아키텍처(6회): Working / Session / Long-term 3계층, CLAUDE.md, 메모리 압축. “무엇을 기억할 것인가.”
- 컨트롤 루프(7회): 에이전트 루프, 랄프 루프, 컨텍스트 불안 대응, 자동 복구. “어떤 순서로 행동할 것인가.”
- 센서(8회 — 오늘): 린터, 테스트, 타임아웃, 관찰성 텔레메트리, 결과 포맷팅. “행동의 결과를 어떻게 관찰할 것인가.”
- 권한(8회 — 오늘): 최소 권한, 승인 게이트, 샌드박스 격리. “행동의 범위를 어떻게 제한할 것인가.”
이 6개를 조합하면 에이전트 하니스의 전체 그림이 됩니다. 그리고 이것이 같은 모델에서 최대 6배의 성능 차이를 만들어내는 메커니즘입니다. 모델은 CPU입니다. 하니스가 OS입니다. OS 없는 CPU는 실리콘 덩어리에 불과합니다.
GPT-5.5가 하니스만 바꿔 기능성 점수 61.5% → 87.2%로 뛴 것, Claude Opus가 Terminal-Bench에서 77% → 93%(하니스만 다른 상태)를 기록한 것 — 이 모든 차이는 6대 컴포넌트의 설계 품질에서 나옵니다.
이번 글 한 줄 요약
센서는 에이전트에게 “눈”을 주고, 권한은 “울타리”를 친다 — 둘이 합쳐져야 에이전트가 안전하게 자율적으로 일한다.
다음 회차 예고
Phase 2가 완결되었으니, 다음 9회부터는 Phase 3(HOW) — 직접 만들고 운영하기에 돌입합니다. 9회의 주제: “40줄 미니 하니스부터 시작하는 하니스 구축 실전”. 지금까지 배운 6대 컴포넌트를 실제로 조립해, 최소한의 코드로 동작하는 에이전트 하니스를 처음부터 만들어 봅니다. 이론에서 코드로 — 하니스 엔지니어링의 가장 재미있는 구간입니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 7화 (다음 차수는 아직 게시되지 않았습니다)