
로그를 꼼꼼히 수집하고, 메트릭 대시보드를 예쁘게 꾸며 놓고, 분산 트레이싱까지 연결했는데도 여전히 같은 질문 앞에서 멈추는 순간이 있습니다. “이 API가 왜 느린 거지?” 트레이스를 열어보면 특정 스팬이 800ms를 잡아먹고 있다는 건 알겠는데, 그 안에서 정확히 어떤 함수가 CPU를 점유하고 있는지, 어느 코드 라인이 메모리를 과도하게 할당하는지까지는 보이지 않습니다.
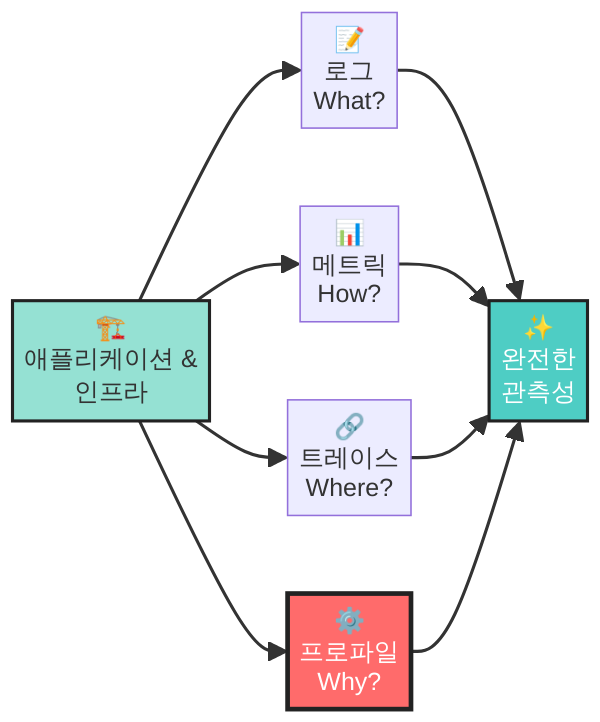
로그·메트릭·트레이스라는 관측성의 세 가지 축(Three Pillars)은 “무엇이 일어났는가”와 “어디서 느려졌는가”를 알려줍니다. 하지만 “왜 그 코드가 느린가”라는 질문에 답하려면, 한 단계 더 깊은 시야가 필요합니다. 바로 컨티뉴어스 프로파일링(Continuous Profiling)입니다. 2025년 이후 CNCF 생태계에서 급부상하며 관측성의 네 번째 신호로 자리 잡고 있는 이 기술을, 오늘 실전 관점에서 자세히 살펴보겠습니다.
컨티뉴어스 프로파일링이란 무엇인가
프로파일링의 기본 개념
프로파일링(Profiling)이란 프로그램이 실행되는 동안 CPU 사용 시간, 메모리 할당량, I/O 대기 시간 등 자원 소비 패턴을 함수 단위로 기록하는 기술입니다. 개발자라면 한 번쯤 cProfile(Python), pprof(Go), async-profiler(Java) 같은 도구를 로컬 환경에서 돌려 본 경험이 있을 것입니다. 특정 함수가 전체 실행 시간의 몇 퍼센트를 차지하는지, 호출 스택 깊이가 어디까지 이어지는지를 시각화해 주기 때문에, 성능 최적화의 출발점으로 오래전부터 활용되어 왔습니다.
전통적 프로파일링의 한계
그런데 전통적 프로파일링에는 근본적인 한계가 있습니다. 대부분 개발자의 로컬 머신이나 스테이징 환경에서 일회성으로 수행됩니다. 프로덕션 환경의 실제 트래픽 패턴, 동시 접속 부하, 특정 시간대에만 발생하는 핫 패스(hot path)를 포착하지 못합니다. 게다가 프로파일러를 켜는 순간 오버헤드가 커서 프로덕션 서버에서 상시 실행하기엔 부담스럽다는 인식도 강합니다.
“재현이 안 돼요.” 성능 이슈 대응 과정에서 이 말을 들어 본 적이 있다면, 전통적 프로파일링의 한계를 체감한 것입니다. 프로덕션에서만 발생하는 문제를 로컬에서 재현하려다 시간을 낭비하는 일이 반복됩니다.
컨티뉴어스 프로파일링의 정의
컨티뉴어스 프로파일링은 이 문제를 정면으로 해결합니다. 프로덕션 환경에서 항상(continuous) 프로파일링 데이터를 수집하되, 샘플링 기반으로 오버헤드를 극도로 낮추어(일반적으로 CPU 1~3% 미만) 서비스 품질에 영향을 주지 않습니다. 수집된 프로파일 데이터는 중앙 서버로 전송되어 시계열로 저장되므로, 과거 특정 시점의 CPU·메모리 사용 패턴을 함수 레벨까지 되감아 분석할 수 있습니다.
핵심 차이를 정리하면 이렇습니다.
- 실행 환경: 로컬/스테이징 → 프로덕션 상시
- 수집 방식: 일회성 → 시계열 연속 수집
- 오버헤드: 높음(10~30%) → 극히 낮음(1~3%)
- 분석 대상: 단일 프로세스 → 분산 시스템 전체 서비스
- 활용 시점: 개발 중 → 장애 발생 후 사후 분석, 일상적 최적화
왜 지금 컨티뉴어스 프로파일링이 필요한가
클라우드 비용이라는 현실적 압박
2025~2026년 IT 업계의 화두 중 하나는 FinOps, 즉 클라우드 비용 최적화입니다. 특히 여름은 이커머스, 여행, 배달 플랫폼의 트래픽이 급증하는 시기로, 오토스케일링으로 인스턴스가 늘어나면 비용도 함께 뜁니다. 그런데 만약 코드 레벨의 비효율 때문에 CPU 사용률이 불필요하게 높다면 어떨까요? 하나의 핫 함수를 최적화하는 것만으로 인스턴스 수를 20% 줄일 수 있다면, 그 절감 효과는 인프라 비용에 곧바로 반영됩니다.
컨티뉴어스 프로파일링은 이런 최적화 포인트를 데이터로 정확히 짚어 줍니다. “어떤 서비스의 어떤 함수가 전체 클러스터 CPU의 몇 퍼센트를 소비하는가”를 실시간으로 보여 주기 때문에, 투자 대비 효과가 큰 최적화 대상을 과학적으로 선별할 수 있습니다.
마이크로서비스 아키텍처의 복잡성
모놀리스 시절에는 프로파일러 하나를 띄우면 전체 시스템의 성능을 한눈에 파악할 수 있었습니다. 하지만 수십, 수백 개의 마이크로서비스가 서로 호출하는 환경에서는 “병목이 어느 서비스의 어느 함수에 있는가”를 특정하기가 극도로 어렵습니다. 분산 트레이싱으로 서비스 간 호출 체인은 보이지만, 각 서비스 내부의 함수 레벨 소비까지는 보이지 않습니다.
컨티뉴어스 프로파일링은 이 빈틈을 채웁니다. 트레이스가 “A 서비스 → B 서비스 호출에서 500ms가 소비됐다”고 알려준다면, 프로파일은 “B 서비스의 parseJSON() 함수가 그중 320ms를 차지했다”까지 알려줍니다. 두 신호를 연결하면 문제의 근본 원인을 코드 라인 단위로 좁힐 수 있습니다.
기존 세 가지 신호의 사각지대
관측성의 세 축이 놓치는 영역을 구체적으로 짚어 보겠습니다.
- 로그: “무엇이 발생했는가”를 알려 주지만, 코드 경로별 자원 소비량은 기록하지 않습니다.
- 메트릭: CPU 사용률, 메모리 사용량 같은 집계값을 보여 주지만, 어떤 함수가 그 수치를 만드는지는 알려주지 않습니다.
node_cpu_seconds_total이 80%라는 건 알겠는데, 그 80% 중 얼마나가 비즈니스 로직이고 얼마나가 JSON 직렬화인지는 메트릭만으로 구분 불가합니다. - 트레이스: 서비스 간 호출 지연을 시각화하지만, 각 스팬 내부의 함수 호출 트리까지는 내려가지 않습니다. 스팬의 세분화를 높이면 오버헤드가 급격히 증가합니다.
컨티뉴어스 프로파일링은 이 세 축이 남기는 빈 공간 — “코드 레벨의 자원 소비 패턴” — 을 정확히 채워 주는 네 번째 퍼즐 조각입니다.
주요 도구 비교와 선택 기준
컨티뉴어스 프로파일링 도구는 2024~2026년 사이에 빠르게 성숙했습니다. 대표적인 오픈소스와 상용 솔루션을 비교해 보겠습니다.
Grafana Pyroscope
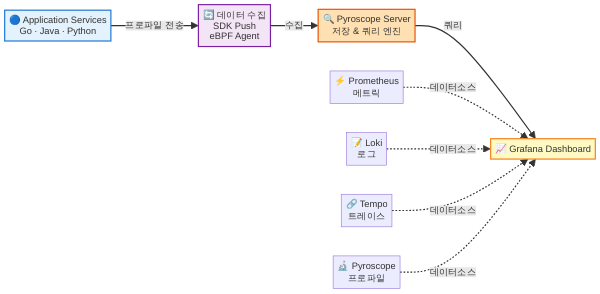
2023년 Grafana Labs에 인수된 Pyroscope는 현재 CNCF 관측성 생태계에서 가장 활발하게 사용되는 오픈소스 컨티뉴어스 프로파일링 도구입니다. 핵심 강점은 Grafana 스택과의 네이티브 통합입니다. 이미 Grafana + Prometheus + Loki + Tempo 조합을 사용 중이라면, Pyroscope를 추가하는 것만으로 메트릭·로그·트레이스·프로파일을 하나의 대시보드에서 연결해 볼 수 있습니다.
- 지원 언어: Go, Java, Python, Ruby, Rust, Node.js, .NET, eBPF(언어 무관)
- 데이터 포맷: pprof 호환, JFR 수집 지원
- 저장 백엔드: 자체 스토리지(블록 기반) 또는 오브젝트 스토리지(S3, GCS)
- 배포 방식: 단일 바이너리(모노리식) 또는 마이크로서비스 모드(대규모 클러스터용)
- 라이선스: AGPLv3
Pyroscope는 두 가지 수집 모드를 제공합니다. SDK를 애플리케이션 코드에 삽입하는 Pull/Push 모드와, eBPF를 활용해 코드 변경 없이 커널 레벨에서 수집하는 에이전트 모드입니다. 후자는 레거시 서비스나 코드 수정이 어려운 서드파티 애플리케이션에 특히 유용합니다.
Parca
Polar Signals가 개발한 Parca는 eBPF 우선(eBPF-first) 철학을 내세우는 오픈소스 프로파일러입니다. parca-agent를 노드에 배포하면 코드 변경 없이 해당 노드의 모든 프로세스를 자동으로 프로파일링합니다. Kubernetes DaemonSet으로 배포하기 매우 편리합니다.
- 핵심 강점: 제로 인스트루멘테이션(zero-instrumentation). 바이너리 디버그 정보(DWARF)에서 심볼을 추출하므로, 애플리케이션에 SDK를 넣을 필요가 없습니다.
- 지원 범위: Linux 커널 기반 eBPF이므로 Linux 노드에서만 동작합니다. 언어에 관계없이 네이티브 바이너리라면 프로파일링 가능합니다.
- UI: 자체 웹 UI를 제공하며, Grafana 데이터소스 플러그인도 지원합니다.
- 라이선스: Apache 2.0
Parca는 특히 Go와 C/C++로 작성된 인프라 컴포넌트(데이터베이스, 프록시, 미들웨어)의 프로파일링에 강합니다. 인터프리터 언어(Python, Ruby)의 경우 런타임 심볼 해석이 제한적일 수 있어, 이런 스택에서는 SDK 기반 Pyroscope가 유리할 수 있습니다.
Datadog Continuous Profiler
상용 관측성 플랫폼인 Datadog은 자체 Continuous Profiler를 제공합니다. Datadog APM을 이미 사용 중이라면 에이전트 설정 한 줄로 활성화할 수 있어 도입 장벽이 매우 낮습니다. 가장 큰 강점은 프로파일과 트레이스의 자동 연결입니다. 특정 트레이스 스팬을 클릭하면 해당 시점의 프로파일 데이터로 바로 넘어갈 수 있어, “느린 요청 → 원인 함수”까지 원클릭으로 추적됩니다.
- 지원 언어: Java, Python, Go, Ruby, .NET, Node.js, PHP
- 차별점: Code Hotspots(트레이스-프로파일 연결), Endpoint Profiling(엔드포인트별 집계)
- 비용: APM 요금에 포함되거나 호스트당 추가 과금
Elastic Universal Profiling
Elastic은 2023년 Prodfiler 인수 후 eBPF 기반 Universal Profiling을 제공합니다. Elastic Stack(ELK)을 이미 운영 중인 팀에게 자연스러운 선택지입니다. 전체 시스템의 CO₂ 배출 추정치까지 보여 주는 독특한 지속 가능성 대시보드가 특징입니다.
도구 선택 의사결정 트리
어떤 도구를 선택할지 고민된다면, 다음 기준으로 좁혀 보세요.
- 이미 Grafana 스택 사용 중 → Pyroscope (네이티브 통합)
- 코드 수정 불가, Linux 환경 → Parca (eBPF 에이전트)
- Datadog APM 사용 중 → Datadog Continuous Profiler (원클릭 활성화)
- Elastic Stack 사용 중 → Elastic Universal Profiling
- 멀티 클라우드, 대규모 클러스터 → Pyroscope 마이크로서비스 모드 또는 Grafana Cloud Profiles
이 글에서는 오픈소스이면서 생태계가 가장 넓은 Grafana Pyroscope를 기준으로 실전 구축 과정을 살펴보겠습니다.
Grafana Pyroscope 실전 구축
실제로 프로젝트에 컨티뉴어스 프로파일링을 도입하는 과정을 단계별로 따라가 보겠습니다. Docker Compose 환경을 기준으로 설명하되, Kubernetes Helm 차트로의 확장도 언급합니다.
1단계: Pyroscope 서버 실행
Pyroscope 서버는 프로파일 데이터를 수신·저장·조회하는 백엔드입니다. 가장 간단한 방법은 Docker로 단일 인스턴스를 띄우는 것입니다.
Docker Compose 파일에 다음과 같은 서비스를 추가합니다. Pyroscope 서버는 기본적으로 4040 포트에서 HTTP API와 웹 UI를 함께 제공합니다. PYROSCOPE_STORAGE_PATH 환경변수로 데이터 저장 경로를 지정하고, 볼륨으로 마운트하면 컨테이너 재시작 시에도 데이터가 보존됩니다.
프로덕션 환경에서는 리텐션 정책을 반드시 설정해야 합니다. 프로파일 데이터는 고해상도일수록 저장 용량을 많이 차지하므로, 일반적으로 최근 7~14일은 원본 해상도로, 이후 90일은 다운샘플링하여 보관하는 전략이 효과적입니다.
2단계: 애플리케이션에 SDK 연동 (Push 모드)
SDK 연동은 애플리케이션 코드에 프로파일링 라이브러리를 추가하는 방식입니다. 언어별로 살펴보겠습니다.
Go 애플리케이션의 경우, Pyroscope Go SDK를 임포트하고 main() 함수 초반에 pyroscope.Start()를 호출합니다. 서버 주소, 애플리케이션 이름, 프로파일 타입(CPU, 힙 메모리, goroutine 등)을 설정합니다. Go는 런타임에 pprof 엔드포인트가 내장되어 있어 연동이 가장 매끄럽습니다.
Java/Kotlin(JVM) 애플리케이션은 pyroscope-java 에이전트를 JVM 인자(-javaagent)로 붙이는 방식이 권장됩니다. async-profiler 기반이라 JIT 컴파일된 코드의 CPU·메모리 프로파일을 정확하게 캡처합니다. Spring Boot라면 환경변수 몇 개 추가만으로 연동이 끝납니다.
Python 애플리케이션은 pyroscope-io 패키지를 설치하고, pyroscope.configure()를 호출합니다. CPython의 GIL 특성상 CPU 프로파일링은 스레드 단위의 제약이 있지만, 메모리 할당과 락 경합 분석에는 매우 유용합니다. Django, FastAPI, Flask 모두 미들웨어 형태로 자동 연동할 수 있습니다.
모든 언어에서 공통적으로 중요한 설정 두 가지가 있습니다.
- 애플리케이션 이름(
application_name): 서비스를 식별하는 고유 이름입니다.service.name.profile_type형식(예:order-api.cpu)으로 지정하면 Pyroscope UI에서 서비스별로 깔끔하게 분류됩니다. - 태그(labels/tags):
region,env,instance같은 메타데이터를 태그로 부착하면, 특정 인스턴스나 특정 리전에서만 발생하는 성능 차이를 필터링해 비교할 수 있습니다. 동적 태그도 지원되어, 예를 들어 HTTP 엔드포인트별(/api/ordersvs/api/users)로 프로파일을 분리할 수 있습니다.
3단계: eBPF 에이전트 모드 (코드 수정 불가 시)
코드를 수정할 수 없는 서드파티 애플리케이션이나 레거시 서비스에는 eBPF 에이전트를 사용합니다. Pyroscope의 eBPF 에이전트(grafana/agent의 프로파일링 컴포넌트 또는 pyroscope-ebpf)를 호스트나 Kubernetes DaemonSet으로 배포하면, 해당 노드의 모든 프로세스를 커널 레벨에서 프로파일링합니다.
eBPF 모드의 장점은 명확합니다. 애플리케이션 재시작 없이, 코드 한 줄 건드리지 않고, 새로운 서비스가 배포되면 자동으로 프로파일링이 시작됩니다. 단, Linux 커널 4.9 이상이 필요하고(권장 5.8+), 컨테이너 환경에서는 SYS_ADMIN 또는 BPF 캐퍼빌리티가 필요합니다.
4단계: Grafana 대시보드 연동
Pyroscope 서버가 데이터를 수집하기 시작했다면, Grafana에서 시각화합니다. Grafana 10.x 이상에서는 Pyroscope 데이터소스가 기본 플러그인으로 포함되어 있으므로, 데이터소스 추가에서 Pyroscope를 선택하고 서버 URL만 입력하면 됩니다.
Grafana의 Explore 뷰에서 Pyroscope 데이터소스를 선택하면 다음 기능을 사용할 수 있습니다.
- 시계열 뷰: 시간 축을 따라 CPU·메모리 사용량이 어떤 함수에 집중되어 있는지를 스택 영역 차트로 보여 줍니다.
- 플레임 그래프: 특정 시간 구간을 선택하면 해당 구간의 집계된 플레임 그래프를 렌더링합니다.
- 비교(Diff) 뷰: 두 시간 구간의 프로파일을 겹쳐 비교합니다. 배포 전후의 성능 변화를 시각적으로 확인할 때 매우 유용합니다.
- 트레이스 연결: Tempo(분산 트레이싱)와 Pyroscope를 함께 설정하면, 특정 트레이스 스팬에서 프로파일 데이터로 점프할 수 있습니다. Grafana의 Profiles for span 패널이 이를 지원합니다.
실무에서 가장 효과적인 대시보드 구성은 상단에 Prometheus의 CPU·메모리 메트릭(시계열 그래프)을 배치하고, 하단에 Pyroscope의 플레임 그래프를 연동하여, 메트릭이 급증하는 구간을 클릭하면 자동으로 해당 시간대의 플레임 그래프가 로드되도록 만드는 것입니다. “CPU 급등 → 원인 함수”를 한 화면에서 추적할 수 있습니다.
플레임 그래프 제대로 읽고 활용하기
컨티뉴어스 프로파일링의 핵심 출력물은 플레임 그래프(Flame Graph)입니다. 2011년 Brendan Gregg가 고안한 이 시각화 형식은, 직관적이면서도 처음 접하면 읽는 법이 헷갈릴 수 있습니다. 정확하게 읽는 법을 익혀 두면 실전 분석 속도가 극적으로 빨라집니다.
플레임 그래프의 기본 구조
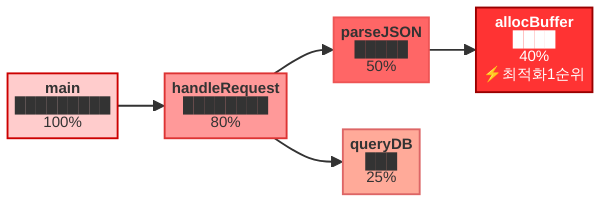
플레임 그래프는 가로축과 세로축으로 구성됩니다.
- 세로축(Y축): 호출 스택의 깊이입니다. 맨 아래가 루트 함수(예:
main())이고, 위로 올라갈수록 더 깊은 호출입니다. - 가로축(X축): 시간 순서가 아닙니다. 이것이 가장 흔한 오해입니다. 가로 너비는 해당 함수가 전체 샘플에서 차지하는 비율을 나타냅니다. 같은 레벨의 함수들은 알파벳순으로 정렬됩니다.
따라서 가로로 넓은 블록이 CPU(또는 메모리)를 가장 많이 소비하는 함수입니다. 플레임 그래프를 볼 때는 “넓은 평탄 지대(plateau)”를 먼저 찾으세요. 그것이 최적화의 1순위 타깃입니다.
Self Time vs Total Time
함수의 자원 소비를 해석할 때 두 가지 관점을 구분해야 합니다.
- Total Time(총 시간): 해당 함수와 그 함수가 호출한 모든 하위 함수의 소비 합계입니다. 블록의 전체 너비에 해당합니다.
- Self Time(자체 시간): 해당 함수 자체에서 소비된 시간, 즉 하위 호출을 제외한 순수 시간입니다. 블록에서 자식 블록을 뺀 나머지 영역입니다.
최적화 대상을 찾을 때는 Self Time이 큰 함수를 우선 봅니다. Total Time이 크더라도 Self Time이 거의 없다면, 그 함수 자체가 아니라 하위 함수에 문제가 있는 것입니다. Pyroscope의 테이블 뷰에서 Self 열로 정렬하면 한눈에 파악됩니다.
프로파일 타입별 분석 포인트
프로파일 데이터는 수집 대상에 따라 여러 타입으로 나뉩니다. 각 타입별로 어떤 문제를 진단할 수 있는지 알아보겠습니다.
CPU 프로파일은 가장 기본적인 타입입니다. 어떤 함수가 CPU 시간을 가장 많이 소비하는지를 보여 줍니다. 비효율적인 알고리즘, 불필요한 반복 계산, 과도한 직렬화/역직렬화를 찾아내는 데 적합합니다.
힙(Heap) 메모리 프로파일은 메모리 할당 패턴을 보여 줍니다. Alloc Objects(할당 횟수)와 Alloc Space(할당 크기) 두 관점으로 나뉩니다. GC 압박이 심하다면 Alloc Objects가 비정상적으로 높은 함수를 찾아야 하고, OOM(Out of Memory) 위험이 있다면 Alloc Space가 큰 함수를 추적해야 합니다.
Goroutine/Thread 프로파일(Go의 경우)은 동시성 문제를 진단합니다. goroutine 수가 비정상적으로 많다면 리소스 누수(leak)를 의심할 수 있습니다. 뮤텍스 경합 프로파일은 동시 접근으로 인한 락 대기 시간을 보여 줍니다.
Wall-clock 프로파일은 CPU 시간이 아니라 실제 경과 시간을 측정합니다. I/O 대기, 네트워크 대기, 슬립 등 CPU를 소비하지 않지만 응답 지연을 유발하는 구간을 포착하는 데 유용합니다.
실전 최적화 사례 세 가지
컨티뉴어스 프로파일링으로 실제 발견되는 대표적인 패턴을 소개합니다.
사례 1: JSON 직렬화 병목
한 주문 처리 서비스에서 CPU 프로파일을 확인하니, json.Marshal() 함수가 전체 CPU의 28%를 차지하고 있었습니다. 큰 구조체를 매 요청마다 JSON으로 변환하고 있었는데, 응답 필드 중 실제로 클라이언트가 사용하는 필드는 전체의 30%에 불과했습니다. DTO(Data Transfer Object)를 분리하고 필요한 필드만 직렬화하도록 수정한 결과, CPU 사용률이 22% 감소했고 인스턴스 2대를 줄일 수 있었습니다.
사례 2: 숨겨진 정규표현식 컴파일
인증 미들웨어에서 매 요청마다 정규표현식을 새로 컴파일하고 있었습니다. 메트릭으로는 인증 미들웨어의 지연이 5ms 이내라 큰 문제로 보이지 않았지만, 프로파일에서는 이 함수가 CPU의 12%를 먹고 있었습니다. 초당 수천 건의 요청이 곱해지니 절대값은 작아도 총량은 상당했습니다. 정규표현식을 사전 컴파일(pre-compile)하도록 수정하여 CPU 사용량을 11%포인트 줄였습니다.
사례 3: 메모리 할당 폭풍
Go로 작성된 로그 수집기에서 GC(가비지 컬렉션)가 비정상적으로 자주 발생해 P99 지연이 튀고 있었습니다. 힙 프로파일을 확인하니, 로그 라인을 파싱하는 과정에서 임시 []byte 슬라이스를 매번 새로 할당하고 있었습니다. sync.Pool로 버퍼를 재활용하도록 수정한 결과, GC 빈도가 60% 감소하고 P99 지연이 45ms에서 18ms로 개선되었습니다.
도입 로드맵과 조직 설득 전략
단계별 도입 전략
컨티뉴어스 프로파일링을 조직에 도입할 때는 점진적 접근이 효과적입니다.
1주차 — 파일럿: 가장 성능이 민감한 서비스 1~2개를 선택합니다. SDK 연동(또는 eBPF 에이전트 배포)을 적용하고, Pyroscope 서버와 Grafana 대시보드를 구성합니다. 이 단계의 목표는 “프로파일이 수집되어 플레임 그래프가 보인다”는 것을 확인하는 것입니다.
2주차 — 첫 최적화: 파일럿 서비스의 CPU·메모리 프로파일을 분석해 최소 1개의 최적화 포인트를 찾습니다. 앞서 소개한 사례처럼, 불필요한 직렬화나 반복 할당 같은 “빠른 승리(quick win)”를 달성합니다. 이 결과를 수치(CPU 절감률, 인스턴스 축소 수, 비용 절감 금액)로 정리합니다.
3~4주차 — 확산: 첫 최적화 결과를 팀에 공유합니다. “프로파일링으로 월 X만 원의 클라우드 비용을 절감했다”는 구체적 숫자가 조직을 설득하는 가장 강력한 무기입니다. 나머지 핵심 서비스로 확대 적용하고, CI/CD 파이프라인에 프로파일 비교를 포함하는 것도 고려합니다(배포 전후 프로파일 diff 자동화).
1~3개월 — 성숙: 프로파일 데이터를 메트릭·트레이스와 연결하여 통합 관측성 대시보드를 완성합니다. 알림 규칙도 추가합니다. 예를 들어 “특정 함수의 CPU 점유율이 평소 대비 200% 이상 증가하면 알림”같은 조건입니다. 이 단계가 되면 컨티뉴어스 프로파일링이 일상적인 운영 도구로 자리 잡습니다.
오버헤드에 대한 팀의 우려 해소
“프로덕션에서 프로파일러를 켜도 괜찮은가?”는 도입 과정에서 반드시 나오는 질문입니다. 데이터로 답하세요.
- Pyroscope SDK의 CPU 프로파일링은 기본 100Hz 샘플링(초당 100번 스택 스냅샷)으로, 오버헤드가 1~2% 수준입니다.
- eBPF 기반 프로파일링은 커널 레벨에서 동작하므로 사용자 공간 오버헤드가 더 낮습니다.
- Google은 전사 프로파일링 시스템(Google-Wide Profiling)을 2010년부터 모든 프로덕션 서비스에 상시 적용해 왔으며, 이를 바탕으로 발표한 논문에서 오버헤드를 무시할 수 있는 수준이라고 보고했습니다.
- LinkedIn, Uber, Netflix 등 대규모 서비스 기업이 프로덕션에서 컨티뉴어스 프로파일링을 일상적으로 운용하고 있습니다.
확신이 서지 않는다면, 파일럿 단계에서 프로파일링 전후의 P50/P99 지연과 CPU 사용률을 A/B 비교해 보세요. 차이가 통계적으로 유의미하지 않다는 것을 직접 확인하는 것이 가장 효과적인 설득입니다.
컨티뉴어스 프로파일링과 개발 문화
기술 도입 못지않게 중요한 것은 조직의 개발 문화와 연결하는 것입니다. 프로파일 데이터를 코드 리뷰 과정에 통합하면, “이 PR이 기존 대비 CPU 사용량을 얼마나 바꿨는가”를 객관적으로 평가할 수 있습니다. Pyroscope와 Grafana는 특정 커밋이나 태그 기준으로 프로파일을 비교하는 기능을 제공하므로, CI/CD 파이프라인에서 배포 후보 빌드의 프로파일을 자동으로 생성하고 현재 프로덕션 프로파일과 비교하는 워크플로를 구성할 수 있습니다.
이렇게 하면 성능 회귀(performance regression)가 코드 리뷰 단계에서 조기에 발견되고, 프로덕션에 나가기 전에 차단됩니다. “성능은 기능이다”라는 인식을 팀에 심을 수 있는 강력한 방법입니다.
마무리: 관측성의 완성을 향해
로그는 “무슨 일이 일어났는가”를, 메트릭은 “지금 상태가 어떤가”를, 트레이스는 “요청이 어디를 거쳐갔는가”를 알려줍니다. 그리고 컨티뉴어스 프로파일링은 “왜 그 코드가 자원을 소비하는가“를 알려줍니다. 이 네 가지가 갖추어질 때 비로소 관측성은 완성됩니다.
특히 클라우드 비용이 민감한 지금, 코드 레벨의 자원 소비를 가시화하는 컨티뉴어스 프로파일링의 가치는 더욱 커지고 있습니다. 여름철 트래픽 증가를 앞두고 있다면, 지금이 파일럿을 시작하기에 최적의 시점입니다. 가장 느린 서비스 하나를 골라, SDK 한 줄 추가하고, 첫 플레임 그래프를 열어 보세요. 그 안에서 분명 지금까지 보이지 않았던 최적화 포인트가 기다리고 있을 것입니다.
“측정할 수 없으면 개선할 수 없다”는 피터 드러커의 말은 관측성에서도 그대로 적용됩니다. 컨티뉴어스 프로파일링으로, 코드의 자원 소비를 마침내 측정하고 개선하세요.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.