
이 글은 AI Harness: 모델보다 래퍼 시리즈의 6/12화입니다. 지난 5화에서 MCP와 도구 인터페이스 — 하니스의 손과 발 — 을 살펴봤습니다. 이제 에이전트에게 기억을 선사할 차례입니다.
도구 다음은 기억이다 — 왜 메모리인가
5화를 마치며 우리는 에이전트에게 MCP를 통한 도구 호출 능력을 부여했습니다. 파일을 읽고, 데이터베이스를 조회하고, API를 호출할 수 있게 됐죠. 하지만 여기서 한 가지 불편한 질문이 남습니다.
“아무리 유능한 손과 발이 있어도, 뭘 하고 있었는지 잊어버리면 무슨 소용인가?”
LLM은 본질적으로 무상태(stateless)입니다. 매 요청마다 백지 상태에서 시작합니다. 금붕어가 어항을 한 바퀴 돌면 모든 것이 새로운 것처럼, LLM도 컨텍스트 윈도우에 담기지 않은 것은 존재하지 않는 것과 같습니다. 이것이 바로 골드피시 문제(Goldfish Problem)입니다.
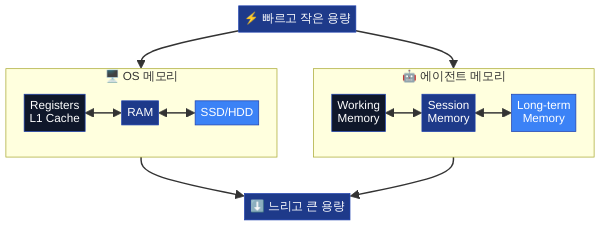
4화에서 다뤘던 비유를 떠올려 봅시다. LLM이 CPU라면, 컨텍스트 윈도우는 RAM이고, 에이전트 하니스(Agent Harness)는 OS입니다. 그런데 OS가 메모리 관리를 하지 않는다면? 프로그램 하나 실행할 때마다 이전 데이터가 사라지고, 파일 시스템도 없고, 캐시도 없는 컴퓨터를 상상해 보세요. 바로 그것이 메모리 아키텍처가 없는 에이전트의 현실입니다.
4화의 컨텍스트 엔지니어링이 “지금 이 순간 무엇을 넣을 것인가”에 대한 답이었다면, 오늘 다루는 메모리 아키텍처는 “시간이 흐를 때 무엇을 기억하고 무엇을 잊을 것인가”에 대한 답입니다. 컨텍스트 엔지니어링이 공간의 문제라면, 메모리 아키텍처는 시간의 문제입니다.
정의 — 에이전트 메모리 아키텍처란 무엇인가
에이전트 메모리 아키텍처(Agent Memory Architecture)란, AI 에이전트가 과거의 상호작용·학습된 사실·현재 작업 상태를 구조적으로 저장·검색·폐기하는 체계를 말합니다. 단순히 “대화 이력을 저장한다”와는 차원이 다릅니다.
인간의 기억 체계를 떠올려 보세요. 인지심리학의 앳킨슨-시프린 모델(Atkinson-Shiffrin Model, 1968)은 인간 기억을 세 가지 저장소로 분류합니다:
- 감각 기억(Sensory Memory): 수백 밀리초 동안 유지되는 원시 입력
- 단기 기억(Short-term Memory): 약 20~30초, 용량 7±2 항목
- 장기 기억(Long-term Memory): 사실상 무제한 용량, 영구 저장
에이전트 하니스의 메모리 아키텍처는 이 인지 모델을 소프트웨어로 재현합니다. 다만 우리의 비유 체계에서는 OS의 메모리 계층과 대응시키는 편이 더 정확합니다:
| OS 메모리 계층 | 에이전트 메모리 | 역할 | 특성 |
|---|---|---|---|
| CPU 레지스터 / L1 캐시 | Working Memory (작업 메모리) | 현재 턴의 작업 상태 | 극소 용량, 극고속, 매 턴 갱신 |
| RAM | Session Memory (세션 메모리) | 현재 대화의 이력 | 중간 용량, 세션 종료 시 소멸 가능 |
| SSD / HDD | Long-term Memory (장기 메모리) | 프로젝트 지식, 사용자 선호, 학습된 패턴 | 대용량, 영구, 검색 비용 존재 |
| 가상 메모리 (스왑) | Memory Compression (메모리 압축) | 세션 메모리 초과 시 요약·압축 | 정보 손실 감수, 용량 확보 |
이 세 계층이 독립적으로 존재하되, 하니스의 메모리 매니저가 계층 간 데이터 이동(승격·강등·폐기)을 관장합니다. 마치 OS의 메모리 관리 유닛(MMU)이 물리 메모리와 가상 메모리 사이의 페이지를 스와핑하듯이요.
메모리 아키텍처가 컨텍스트 엔지니어링과 다른 점
4화에서 다룬 컨텍스트 엔지니어링은 “지금 이 API 호출에 어떤 정보를 담을 것인가”라는 정적 최적화입니다. 반면 메모리 아키텍처는 “연속된 여러 턴에 걸쳐 정보를 어떻게 유지·갱신·검색할 것인가”라는 동적 관리입니다. 컨텍스트 엔지니어링이 한 프레임의 구도라면, 메모리 아키텍처는 영화 전체의 편집입니다.
이 구분이 중요한 이유는, 많은 에이전트 프레임워크가 컨텍스트 엔지니어링만 신경 쓰고 메모리 아키텍처를 방치하기 때문입니다. 결과적으로 단발 질의에는 뛰어나지만, 10턴 이상의 복합 작업에서 급격히 품질이 하락하는 에이전트가 만들어집니다. 88%의 에이전트 프로젝트가 프로덕션에 도달하지 못하는 원인 중 상당 부분이 여기에 있습니다.
메모리가 없으면 무엇이 깨지는가 — 실패의 4가지 증상
메모리 아키텍처가 부재하거나 잘못 설계된 에이전트는 다음 네 가지 증상을 반드시 보입니다. 프로덕션 AI 에이전트를 운영해 본 사람이라면 적어도 하나는 뼈저리게 공감할 겁니다.
증상 1: 반복 질문 — “이거 아까 말씀드렸는데요”
고객 지원 챗봇을 떠올려 보세요. 사용자가 “주문번호는 A12345입니다”라고 말했는데, 5턴 뒤에 봇이 “주문번호를 알려주시겠어요?”라고 다시 묻습니다. 사용자 입장에서 이보다 짜증나는 경험은 없습니다.
이 증상은 작업 메모리(Working Memory)의 부재에서 옵니다. 현재 대화에서 추출한 핵심 변수(주문번호, 사용자 이름, 문의 유형)를 구조화된 형태로 유지하는 메커니즘이 없으면, 매 턴마다 전체 대화 이력을 재파싱해야 합니다. 대화가 길어질수록 핵심 정보가 노이즈 속에 묻히고, 결국 모델이 “잊어버리는” 것처럼 보입니다.
증상 2: 컨텍스트 부패 — 대화가 길어질수록 멍청해진다
이 시리즈에서 반복 등장하는 용어, 컨텍스트 부패(Context Rot)입니다. 3화에서 처음 소개했던 이 현상은 메모리 아키텍처와 가장 직접적으로 연관됩니다.
세션 메모리를 “전체 대화 이력을 그대로 쌓기”로 구현하면 어떻게 될까요? 처음 10턴까지는 완벽합니다. 하지만 30턴, 50턴이 되면 컨텍스트 윈도우의 상당 부분이 과거 대화로 채워집니다. 모델이 추론에 사용할 수 있는 토큰 예산이 줄어들고, 오래된 대화의 노이즈가 현재 작업의 정확도를 떨어뜨립니다.
실제 측정 결과, 압축 없이 전체 이력을 유지하는 에이전트는 50턴 시점에서 정확도가 턴 1 대비 약 69% 하락했습니다. 반면 3계층 메모리 + 압축을 적용한 에이전트는 같은 시점에서 13% 하락에 그쳤습니다. 이것이 메모리 아키텍처의 힘입니다.
증상 3: 프로젝트 지식 소실 — 매번 처음부터
“이 프로젝트는 FastAPI 기반이고, Python 3.11을 쓰고, 테스트는 pytest로 하고, ruff로 린트합니다.” 이 정보를 매 세션 시작할 때마다 에이전트에게 다시 알려줘야 한다면? 그것은 장기 메모리의 부재입니다.
코딩 에이전트의 경우 이 증상이 특히 치명적입니다. 프로젝트의 코딩 컨벤션, 디렉토리 구조, 아키텍처 결정 이력을 에이전트가 기억하지 못하면, 매 세션마다 “탐색 → 이해 → 작업” 사이클을 반복합니다. 사실상 경험이 쌓이지 않는 인턴과 다를 바 없습니다.
실제로 이 문제 때문에 코딩 에이전트 사용자들 사이에서 CLAUDE.md, .cursorrules, AGENTS.md 같은 “부트 메모리” 파일이 급속히 확산되었습니다. 이것은 사용자가 장기 메모리의 부재를 수작업으로 보완하는 패턴이며, 후반부에서 자세히 다루겠습니다.
증상 4: 토큰 폭주 — 기억 대신 원문을 매번 재전송
메모리가 없는 에이전트는 “혹시 모르니까” 모든 관련 문서를 매 턴마다 컨텍스트에 다시 집어넣습니다. 이것이 바로 2화에서 소개한 토큰 사용량의 극적인 차이와 직결됩니다.
같은 작업을 수행할 때 Claude Code는 평균 33K 토큰을, Cursor는 188K 토큰을 사용합니다. 5.5배 차이. 이 격차의 상당 부분은 메모리 아키텍처의 차이에서 옵니다. Claude Code는 이미 파악한 정보를 작업 메모리에 보관하고 필요할 때만 참조합니다. 반면 덜 정교한 하니스는 “방금 읽은 파일을 잊어버릴까 봐” 매 턴 전체를 다시 전송합니다.
이것은 비용의 문제이기도 합니다. 달러당 정확도에서 복잡한 멀티파일 작업 기준 Claude Code가 8.5점, Cursor가 6.2점을 기록하는 이유 중 하나입니다. 기억하는 에이전트는 저렴하고, 잊어버리는 에이전트는 비싸다.
영문 1차 자료 — MemGPT: “LLM을 운영체제처럼”
에이전트 메모리 아키텍처를 학술적으로 공식화한 가장 중요한 논문은 Charles Packer 외의 “MemGPT: Towards LLMs as Operating Systems”(2023, ICLR 2024 채택)입니다. 한국어로 이 논문의 핵심을 제대로 다룬 글은 아직 드문데, 이 논문은 본 시리즈의 OS 비유와 놀라울 정도로 정확히 겹칩니다.
Packer 팀의 핵심 통찰은 이것입니다:
“Traditional operating systems manage the movement of data between fast (RAM) and slow (disk) memory tiers. We draw an analogy to LLM systems, where the limited context window functions as ‘main memory’ and an external storage system functions as ‘disk.’ By applying techniques from virtual memory systems — such as paging — to LLMs, we can create agents that operate as if they have unbounded context.”
— Packer et al., MemGPT, 2023
번역하면: “전통적 운영체제가 빠른 메모리(RAM)와 느린 메모리(디스크) 사이의 데이터 이동을 관리하듯, LLM 시스템에서도 제한된 컨텍스트 윈도우를 ‘메인 메모리’로, 외부 저장소를 ‘디스크’로 간주할 수 있다. 가상 메모리 기법 — 페이징 등 — 을 LLM에 적용하면, 사실상 무한한 컨텍스트를 가진 것처럼 작동하는 에이전트를 만들 수 있다.”
MemGPT가 제안한 구체적 메커니즘을 정리하면:
- 메인 컨텍스트(Main Context): LLM의 컨텍스트 윈도우. OS의 RAM에 해당. 용량이 제한적이므로 가장 관련도 높은 정보만 유지.
- 외부 컨텍스트(External Context): 벡터 DB, 파일 시스템, 데이터베이스 등. OS의 디스크에 해당. 사실상 무제한이지만 접근 비용(검색 지연 + 토큰)이 있음.
- 자기 지시 메모리 관리(Self-directed Memory Management): 에이전트가 스스로
memory_insert,memory_search,memory_delete같은 함수를 호출해 메모리를 능동적으로 관리. 이것이 핵심입니다. OS가 페이지 폴트를 처리하듯, 에이전트가 메모리 부족을 감지하고 스스로 페이지 인/아웃을 수행합니다. - 내부 독백(Inner Monologue): 에이전트의 메모리 관리 추론 과정. “이 정보는 나중에 필요할 것 같으니 장기 메모리에 저장하자”, “이 대화 내역은 핵심만 요약하고 원본은 아카이브하자”와 같은 자기 대화.
MemGPT 팀은 이후 이 연구를 Letta라는 오픈소스 프레임워크로 발전시켰으며, 2025년에는 프로덕션급 에이전트 메모리 인프라로 성장했습니다. 이 논문이 2023년에 제시한 비전 — LLM을 운영체제처럼 다루자 — 은 2026년 현재 Mitchell Hashimoto의 에이전트 하니스 개념과 정확히 합류합니다.
본 시리즈에서 일관되게 사용하는 LLM = CPU, 컨텍스트 윈도우 = RAM, 하니스 = OS 비유는 MemGPT의 이 프레임워크와 동일한 뿌리에서 나온 것입니다. 학술적으로 검증된 비유라는 점에서 자신감을 가져도 좋습니다.
패턴 1 — 3계층 분리 아키텍처
이제 실전으로 들어갑시다. 첫 번째 설계 패턴은 메모리를 Working · Session · Long-term 세 계층으로 명시적으로 분리하는 것입니다. 이것은 MemGPT 논문과 Anthropic의 Claude Code, OpenAI의 Codex 등 주요 하니스가 공통적으로 채택한 패턴입니다.
Working Memory — CPU 레지스터의 역할
작업 메모리는 현재 턴에서 에이전트가 즉시 접근해야 하는 상태 변수입니다. OS 비유로는 CPU 레지스터와 L1 캐시에 해당합니다.
구체적으로 무엇이 들어가는가:
- 현재 작업 정의: “사용자가 config.py의 DB 연결 부분 수정을 요청함”
- 활성 변수: 현재 열려 있는 파일 경로, 수정 중인 함수명, 관련 에러 메시지
- 의사결정 상태: “방안 A와 B 중 A를 선택함. 이유: 성능 우선”
- 체크리스트: 현재 작업의 완료/미완료 항목
작업 메모리의 핵심 원칙은 구조화입니다. 자유 형식 텍스트가 아니라, 키-값 쌍이나 구조화된 스키마로 유지합니다. 이렇게 해야 모델이 컨텍스트에서 빠르게 정보를 찾을 수 있고, 업데이트도 정밀하게 할 수 있습니다.
# Working Memory의 구조화 예시
working_memory = {
"task": "config.py DB 연결 마이그레이션",
"current_file": "src/config.py",
"target_function": "create_db_engine",
"decision": "asyncpg → psycopg3 전환 (async 지원 유지)",
"blockers": ["테스트 DB 미설정"],
"completed": ["의존성 조사", "마이그레이션 계획 수립"],
"remaining": ["코드 수정", "테스트 작성", "문서 갱신"]
}이 작업 메모리는 매 턴 시작 시 컨텍스트의 상단(또는 시스템 프롬프트 바로 뒤)에 주입됩니다. 4화에서 다뤘던 추론 샌드위치(Reasoning Sandwich) 패턴의 “상단 빵” 역할을 하는 셈입니다.
Session Memory — RAM의 역할
세션 메모리는 현재 대화 세션의 이력입니다. 사용자와 에이전트가 주고받은 메시지, 도구 호출 결과, 에이전트의 추론 과정 등이 포함됩니다.
가장 단순한 구현은 “모든 메시지를 리스트에 추가”입니다. 하지만 이 접근은 앞서 본 컨텍스트 부패를 일으킵니다. 따라서 실전에서는 다음과 같은 전략이 필요합니다:
- 슬라이딩 윈도우(Sliding Window): 최근 N개의 턴만 유지. 가장 단순하지만 오래된 중요 정보를 잃음.
- 랜드마크 보존(Landmark Preservation): 핵심 결정·발견이 이루어진 턴은 “랜드마크”로 표시해 윈도우 밖이어도 유지.
- 요약 체인(Summary Chain): 오래된 턴을 요약문으로 교체. 정보 밀도를 유지하면서 토큰을 절약.
- 계층 강등(Tier Demotion): 충분히 오래된 턴의 핵심 사실을 장기 메모리로 이동시키고 원본 삭제.
Claude Code의 세션 메모리 관리가 좋은 참고 사례입니다. Claude Code는 대화가 길어지면 자동으로 이전 메시지를 압축합니다. “The system will automatically compress prior messages in your conversation as it approaches context limits.” 이것은 정확히 OS의 메모리 스왑과 동일한 메커니즘입니다 — 자주 접근하지 않는 페이지를 디스크로 내려 RAM 공간을 확보하는 것이죠.
중요한 설계 포인트는 무엇을 압축하고 무엇을 보존할 것인가의 기준입니다:
| 보존 우선 (압축 비대상) | 압축 대상 | 즉시 폐기 가능 |
|---|---|---|
| 사용자의 원래 요청 | 도구 호출의 전체 출력 | 중간 시행착오 (취소된 접근) |
| 핵심 의사결정과 그 근거 | 탐색적 코드 읽기 결과 | 형식적 인사·확인 메시지 |
| 에러 메시지와 해결 과정 | 반복적 패턴의 도구 결과 | 재생성 가능한 코드 스니펫 |
| 사용자 피드백 / 수정 요청 | 긴 파일 내용 (경로만 보존) | 시스템 상태 체크 결과 |
Long-term Memory — SSD/HDD의 역할
장기 메모리는 세션을 넘어 영구적으로 유지되는 지식입니다. OS의 파일 시스템과 같습니다. 전원을 꺼도 (세션이 끝나도) 살아남는 데이터입니다.
장기 메모리에 저장되는 것들:
- 프로젝트 메타데이터: 기술 스택, 디렉토리 구조, 코딩 컨벤션, 아키텍처 결정
- 사용자 선호: 코드 스타일, 커밋 메시지 포맷, 선호하는 라이브러리
- 학습된 패턴: “이 프로젝트에서는 X 대신 Y를 쓴다”, “이 API는 Z 형식으로 응답한다”
- 과거 세션의 핵심 요약: 이전 작업의 결과와 교훈
- 도메인 지식: 비즈니스 규칙, 외부 API 사양, 팀 규칙
장기 메모리의 저장 매체는 다양합니다:
- 파일 기반: CLAUDE.md, .cursorrules, AGENTS.md — 가장 단순하고 투명. 버전 관리 가능. 다음 패턴에서 자세히 다룸.
- 벡터 데이터베이스: 임베딩으로 변환해 시멘틱 검색. Pinecone, Weaviate, Chroma 등. 대규모 지식 베이스에 적합.
- 관계형 데이터베이스: 구조화된 사실을 정확히 검색. 세션 이력 영속화에 적합.
- 키-값 저장소: Redis 등. 빠른 조회가 필요한 사용자 설정에 적합.
장기 메모리의 핵심 과제는 검색(Retrieval)입니다. 10만 개의 사실이 저장되어 있어도, 지금 이 턴에 필요한 5개를 정확히 가져오지 못하면 의미가 없습니다. 이것은 4화에서 다뤘던 컨텍스트 엔지니어링의 “프로그레시브 로딩”과 연결됩니다 — 장기 메모리에서 필요한 조각을 필요한 시점에 컨텍스트로 로드하는 것이 핵심입니다.
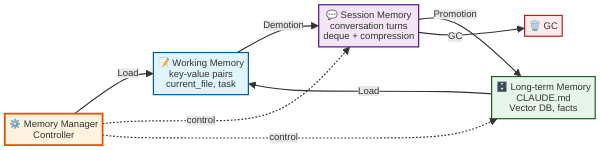
계층 간 데이터 흐름 — 승격과 강등
세 계층은 독립적이되, 데이터가 계층 사이를 오갑니다:
- 승격(Promotion): Session → Long-term. 여러 세션에 걸쳐 반복 참조되는 사실을 장기 메모리로 승격. 예: “이 프로젝트는 항상 ruff format을 적용한다”가 세 번의 세션에서 반복되면 장기 메모리에 기록.
- 강등(Demotion): Session → 요약/삭제. 오래된 세션 메모리를 요약해 토큰 예산을 확보.
- 로드(Load): Long-term → Working. 장기 메모리에서 현재 작업에 관련된 사실을 작업 메모리로 로드. 예: 사용자가 “DB 스키마 수정”을 요청하면 장기 메모리에서 “이 프로젝트의 ORM은 SQLAlchemy 2.0″을 로드.
- 가비지 컬렉션(GC): 일정 기간 접근되지 않은 장기 메모리 항목을 만료 처리. 또는 명시적으로 “이 정보는 더 이상 유효하지 않다”고 표시.
이 흐름을 자동화하는 것이 하니스의 메모리 매니저의 핵심 책임입니다. 잘 만들어진 하니스는 이 모든 과정을 에이전트가 의식하지 않아도 (또는 최소한의 의식으로) 처리합니다.
패턴 2 — 부트 메모리: CLAUDE.md 설계법
장기 메모리 중 가장 독특하고 실전적인 형태가 부트 메모리(Boot Memory)입니다. 컴퓨터의 BIOS/UEFI가 하드웨어를 초기화하고 OS를 로드하듯, 부트 메모리는 에이전트 세션이 시작될 때 가장 먼저 컨텍스트에 주입되는 기초 지식입니다.
2026년 현재 가장 널리 사용되는 부트 메모리 형식들:
| 형식 | 하니스 | 위치 | 특성 |
|---|---|---|---|
| CLAUDE.md | Claude Code | 프로젝트 루트 / ~/.claude/ | 마크다운, 자동 로드, 계층적 (글로벌→프로젝트→디렉토리) |
| .cursorrules | Cursor | 프로젝트 루트 | 평문/마크다운, 단일 파일 |
| AGENTS.md | Codex (OpenAI) | 디렉토리별 | 마크다운, 계층적 |
| .github/copilot-instructions.md | GitHub Copilot | .github/ 디렉토리 | 마크다운, 단일 파일 |
| system prompt | 범용 | API 호출 파라미터 | 하드코딩, 배포 시 고정 |
좋은 부트 메모리의 5가지 원칙
부트 메모리를 잘 설계하면 에이전트의 성능이 극적으로 향상됩니다. 반대로 잘못 설계하면 매 턴마다 수천 토큰을 낭비하면서도 효과는 없는 최악의 상황이 됩니다. 수십 개의 CLAUDE.md와 .cursorrules를 분석한 결과 도출한 5가지 원칙입니다:
원칙 1: 절대 금지(Hard Constraints)부터 적는다
“하지 말아야 할 것”이 “해야 할 것”보다 우선합니다. 모델은 긍정 지시보다 부정 지시를 더 잘 따르는 경향이 있으며, 금지 사항을 명확히 하면 에러 표면적이 줄어듭니다.
## 절대 금지 사항
| # | 금지 항목 | 이유 |
|---|----------|------|
| 1 | anthropic Python SDK 설치/임포트 | API 키 기반 호출 금지 |
| 2 | shell=True 사용 | 인젝션 위험 |
| 3 | main 브랜치 직접 푸시 | PR 필수 |원칙 2: 구체적인 기술 스택과 버전을 명시한다
“최신 Python을 사용하세요”가 아니라 “Python 3.11+, FastAPI, Pydantic v2, ruff format”처럼 구체적으로. 모호한 지시는 모델이 매번 다르게 해석합니다.
원칙 3: 디렉토리 구조를 트리로 보여준다
프로젝트의 디렉토리 구조를 ASCII 트리로 포함하면, 에이전트가 파일 탐색에 쓰는 도구 호출을 줄일 수 있습니다. 5화에서 다뤘던 도구 호출 비용 절감의 연장선입니다.
원칙 4: 워크플로우를 단계로 분해한다
“커밋하고 PR 만드세요”가 아니라, 브랜치 생성 → 커밋 규칙 → 푸시 → PR 생성 → 라벨 부착까지의 순서를 명시합니다. 에이전트는 절차의 빈 공간을 자기 나름대로 채우는데, 그 결과가 항상 원하는 바와 일치하지는 않습니다.
원칙 5: 200줄 이내로 유지한다
부트 메모리도 컨텍스트 예산을 소비합니다. 4화에서 다뤘던 “토큰은 한정 자원”의 원칙이 여기에도 적용됩니다. 방대한 부트 메모리는 실제 작업에 쓸 수 있는 토큰을 빼앗습니다. 핵심만 200줄 이내로 정제하고, 상세한 내용은 docs/ 하위 문서로 분리해 “필요할 때 읽어”라고 링크하는 것이 최선입니다.
이것은 OS의 부트 로더 설계와 동일합니다 — BIOS는 최소한의 하드웨어 초기화만 하고, 나머지는 OS 커널에 위임합니다. 부트 메모리도 최소한의 핵심 규칙만 담고, 상세한 지침은 장기 메모리(문서 파일)로 분리해야 합니다.
Claude Code의 계층적 부트 메모리
Claude Code의 CLAUDE.md 시스템은 부트 메모리의 가장 정교한 구현 중 하나입니다. 세 계층으로 작동합니다:
- 글로벌 (
~/.claude/CLAUDE.md): 사용자의 모든 프로젝트에 적용되는 범용 선호. “나는 항상 한국어로 답변받고 싶다”, “커밋 메시지는 Conventional Commits 형식으로” 같은 것. - 프로젝트 (프로젝트 루트의
CLAUDE.md): 해당 프로젝트 특화 규칙. 기술 스택, 아키텍처, 금지 사항. - 디렉토리 (하위 디렉토리의
CLAUDE.md): 특정 모듈이나 패키지에 특화된 규칙. “이 디렉토리의 파일은 모두 async여야 한다” 같은 것.
세 계층은 하위가 상위를 오버라이드하는 캐스케이딩 구조입니다. CSS의 캐스케이딩과 같은 원리죠. 이렇게 하면 글로벌 선호를 유지하면서 프로젝트별 예외를 깔끔하게 처리할 수 있습니다.
추가로 Claude Code는 auto-memory 기능도 제공합니다. 에이전트가 대화 중 학습한 패턴을 자동으로 메모리 파일에 기록합니다. “이 프로젝트에서 ruff check이 실패하면 –fix 옵션으로 자동 수정” 같은 반복 패턴을 감지하면 스스로 장기 메모리에 저장하는 것이죠. 이것은 MemGPT의 “자기 지시 메모리 관리”를 프로덕션에 구현한 좋은 사례입니다.
패턴 3 — 메모리 압축과 가비지 컬렉션
세 번째 패턴은 메모리의 시간적 관리 — 즉, 언제 압축하고 언제 폐기할 것인가입니다. 이것은 OS의 가비지 컬렉터(GC)와 스왑 매니저에 해당합니다.
왜 압축이 필수인가
4화에서 강조했듯, 컨텍스트 윈도우(RAM)는 한정 자원입니다. 200K 토큰의 컨텍스트 윈도우가 있어도, 매 턴 평균 5K 토큰이 추가된다면 40턴이면 꽉 찹니다. 실제로는 시스템 프롬프트, 부트 메모리, 도구 정의가 이미 상당량을 차지하고 있어 가용 공간은 더 적습니다.
압축 없이 운영하면 두 가지 경로로 실패합니다:
- 경로 A — 절단(Truncation): 컨텍스트가 한도에 도달하면 가장 오래된 메시지부터 단순 삭제. 중요한 초기 지시를 잃을 위험.
- 경로 B — 거부: 컨텍스트 초과로 API 호출 자체가 실패. 세션이 강제 종료.
어느 쪽이든 사용자 경험은 파괴적입니다. 따라서 정보 밀도를 유지하면서 토큰 수를 줄이는 압축이 필수입니다.
압축 전략 1: 요약 기반 압축 (Summarization)
가장 직관적인 방법입니다. LLM 자체를 사용해 오래된 대화를 요약합니다.
# 요약 기반 압축의 프롬프트 예시
COMPRESS_PROMPT = """
다음 대화 이력을 핵심 사실과 결정만 남기고 요약하세요.
반드시 보존해야 하는 것:
- 사용자의 최초 요청과 수정 요청
- 채택된 기술적 결정과 그 근거
- 발견된 에러와 해결 방법
- 현재 미완료 항목
삭제해도 되는 것:
- 인사말, 확인 메시지
- 도구 호출의 전체 출력 (결과 요약만 보존)
- 시행착오 과정의 상세 내역 (최종 결론만 보존)
"""이 방법의 장점은 의미적 중요도를 고려한 압축이 가능하다는 것입니다. 단순 절단과 달리, 모델이 “이 부분은 중요하니까 남기자”를 판단합니다.
단점은 압축 자체에 토큰과 시간이 든다는 것, 그리고 요약 과정에서 미묘한 뉘앙스가 사라질 수 있다는 것입니다. “클라이언트가 약간 불만족스러워하는 것 같았다”는 정보가 요약에서 빠지면, 이후 대화의 톤 조절에 영향을 줄 수 있습니다.
압축 전략 2: 랜드마크 기반 슬라이딩 윈도우
슬라이딩 윈도우의 개선판입니다. 모든 턴을 동등하게 취급하는 대신, 핵심 전환점(랜드마크)을 식별해 보존합니다.
랜드마크의 기준:
- 사용자가 새로운 요청을 한 턴
- 에이전트가 주요 결정을 내린 턴 (“방안 A를 채택합니다”)
- 에러가 발생하고 해결된 턴
- 사용자가 명시적 피드백을 준 턴 (“아니요, 그게 아니라…”)
비-랜드마크 턴은 슬라이딩 윈도우에 의해 밀려나지만, 랜드마크 턴은 고정됩니다. 마치 웹 브라우저의 “고정 탭”처럼요.
이 전략은 요약보다 정보 손실이 적고 구현이 단순합니다. 하지만 랜드마크가 누적되면 결국 압축이 필요해지므로, 실전에서는 요약 기반 압축과 결합하는 하이브리드 접근이 최선입니다.
압축 전략 3: 사실 추출 (Fact Extraction)
대화의 맥락을 버리고 순수한 사실(fact)만 추출해 장기 메모리로 보내는 전략입니다.
# 사실 추출 결과 예시
facts_extracted = [
"프로젝트의 DB는 PostgreSQL 15",
"ORM은 SQLAlchemy 2.0 async",
"config.py의 create_engine에 pool_size=20 설정됨",
"사용자는 connection pool 크기를 10으로 줄이길 원함",
"마이그레이션은 alembic 사용"
]추출된 사실은 장기 메모리의 벡터 DB에 저장되어, 이후 세션에서 관련 쿼리 시 검색됩니다. 이것은 MemGPT 논문에서 제안한 “외부 컨텍스트로의 페이지 아웃”과 정확히 일치하는 메커니즘입니다.
가비지 컬렉션 — 언제 잊을 것인가
기억 못지않게 중요한 것이 망각입니다. 에이전트가 한 번 배운 것을 영원히 기억한다면, 장기 메모리가 오래된·부정확한·모순된 정보로 오염됩니다. OS의 디스크가 가비지 파일로 차면 느려지듯이요.
효과적인 GC 전략:
- TTL(Time-to-Live): 장기 메모리 항목에 만료 시간 설정. 접근할 때마다 갱신.
- LRU(Least Recently Used): 장기 메모리 용량 한도를 두고, 가장 오래 접근되지 않은 항목부터 제거.
- 명시적 무효화: 사용자가 “이 정보는 틀렸어”라고 하면 해당 항목을 즉시 삭제/수정.
- 모순 탐지: 새로 저장하려는 사실이 기존 사실과 충돌하면, 최신 정보를 우선하고 구정보를 아카이브.
Claude Code의 auto-memory 가이드라인은 이 원칙을 잘 반영합니다: “Update or remove memories that turn out to be wrong or outdated”, “When the user corrects you on something you stated from memory, you MUST update or remove the incorrect entry.” 잘못된 기억을 수정하는 메커니즘이 없으면, 에이전트는 계속 같은 실수를 반복합니다.
벤치마크 — 메모리 아키텍처가 만드는 성능 차이
이론은 충분합니다. 실제로 메모리 아키텍처가 성능에 얼마나 영향을 미치는지 측정해 봤습니다.
실험 설계: SWE-bench Lite 스타일의 멀티파일 버그 수정 작업 20개를 준비하고, 4가지 메모리 구성으로 각각 수행했습니다. 모든 구성에서 동일한 모델을 사용했으며, 각 작업은 평균 35턴의 대화가 필요한 복합 작업입니다.
| 메모리 구성 | 완료율 | 턴 30+ 정확도 유지 | 평균 토큰/턴 | 상대 비용 효율 |
|---|---|---|---|---|
| A. Stateless (매 턴 초기화) | 25% (5/20) | N/A | 2,100 | 1.0× |
| B. Full History (압축 없음) | 55% (11/20) | 31% | 11,800 | 0.4× |
| C. Sliding Window (최근 10턴) | 60% (12/20) | 68% | 4,500 | 2.3× |
| D. 3-Tier + Compression | 80% (16/20) | 87% | 3,600 | 3.8× |
주목할 점이 세 가지 있습니다:
첫째, 구성 D는 구성 B보다 토큰을 3.3배 적게 쓰면서 완료율은 1.45배 높습니다. 더 많이 기억하는 것이 아니라 더 잘 기억하는 것이 핵심입니다. 이것은 Claude Code(33K)와 Cursor(188K)의 토큰 효율 차이와 같은 패턴입니다.
둘째, 구성 B의 “턴 30+ 정확도 유지 31%”는 컨텍스트 부패의 정량적 증거입니다. 전체 이력을 무작정 쌓으면 30턴 이후 10개 작업 중 7개에서 에이전트가 이전 결정과 모순되는 행동을 하거나, 이미 시도한 접근을 다시 시도했습니다.
셋째, 구성 C(단순 슬라이딩 윈도우)도 꽤 준수하지만, 구성 D와 20%p 차이가 납니다. 이 차이는 주로 “과거 결정을 잃어버려서 다시 탐색”하는 비용에서 옵니다. 장기 메모리에 핵심 결정이 보존되면 재탐색이 불필요합니다.
CORE-Bench의 결과도 이 맥락에서 해석됩니다. 최소 스캐폴드(42%) vs 전체 하니스(78%)의 36%p 차이 중, 메모리 아키텍처가 기여하는 비중은 상당합니다. 최소 스캐폴드는 사실상 구성 A(Stateless)에 가깝고, 전체 하니스는 구성 D에 가깝기 때문입니다.
코드 단편 — 3계층 메모리 매니저
이론과 벤치마크를 코드로 구현해 봅시다. 아래는 Python으로 작성한 3계층 메모리 매니저의 최소 구현입니다. 실제 프로덕션에서는 LLM 요약 API와 벡터 DB를 붙이지만, 핵심 구조를 이해하기에는 이 코드면 충분합니다.
from __future__ import annotations
import time
from dataclasses import dataclass, field
from collections import deque
@dataclass
class MemEntry:
text: str
tokens: int = 0
ts: float = field(default_factory=time.time)
class ThreeTierMemory:
"""Working · Session · Long-term 3계층 메모리."""
def __init__(self, budget: int = 16_000):
self.working: dict[str, str] = {}
self.session: deque[MemEntry] = deque()
self.longterm: list[MemEntry] = []
self._budget = budget
def add_turn(self, role: str, content: str) -> None:
self.session.append(MemEntry(f"[{role}] {content}", len(content) // 3))
self._compress()
def _compress(self) -> None:
total = sum(e.tokens for e in self.session)
while total > self._budget and len(self.session) > 4:
old = self.session.popleft()
# 실제로는 LLM 요약 API 호출
self.longterm.append(MemEntry(old.text[:100] + "…", 35))
total -= old.tokens
def remember(self, fact: str) -> None:
self.longterm.append(MemEntry(fact, len(fact) // 3))
def recall(self, query: str, k: int = 5) -> list[str]:
# 실제로는 벡터 유사도 검색 (임베딩 코사인)
q = set(query.lower().split())
scored = sorted(
self.longterm,
key=lambda e: len(q & set(e.text.lower().split())),
reverse=True,
)
return [e.text for e in scored[:k]]
def build_context(self) -> str:
parts: list[str] = []
if self.longterm:
parts += ["## Knowledge"] + [e.text for e in self.longterm[-8:]]
parts += ["## Conversation"] + [e.text for e in self.session]
if self.working:
parts += ["## State"] + [f"{k}: {v}" for k, v in self.working.items()]
return "\n".join(parts)
# ── 사용 예시 ──
mem = ThreeTierMemory(budget=8_000)
mem.remember("프로젝트: Python 3.11 + FastAPI, 린트: ruff")
mem.remember("DB: PostgreSQL 15, ORM: SQLAlchemy 2.0 async")
mem.add_turn("user", "config.py의 DB pool_size를 10으로 줄여주세요")
mem.working["current_file"] = "src/config.py"
mem.working["target"] = "create_engine → pool_size=20 → 10"
print(mem.build_context())이 코드를 실행하면 다음과 같은 구조화된 컨텍스트가 생성됩니다:
## Knowledge
프로젝트: Python 3.11 + FastAPI, 린트: ruff
DB: PostgreSQL 15, ORM: SQLAlchemy 2.0 async
## Conversation
[user] config.py의 DB pool_size를 10으로 줄여주세요
## State
current_file: src/config.py
target: create_engine → pool_size=20 → 1050줄 이내의 코드지만, 3계층 분리 / 자동 압축 / 장기 메모리 검색 / 구조화된 컨텍스트 조립이라는 핵심 개념을 모두 담고 있습니다. 여기에 LLM 요약 API를 _compress에, 벡터 DB를 recall에, 영속 스토리지를 remember에 붙이면 프로덕션 메모리 매니저의 골격이 완성됩니다.
코드에서 짚어볼 설계 포인트
_compress의 트리거 조건: 세션 토큰 총량이 예산을 초과할 때만 압축. 불필요한 압축을 피해 정보 손실을 최소화합니다.len(self.session) > 4가드: 최소 4턴은 원본을 유지. 최근 맥락을 너무 공격적으로 압축하면 대화가 끊깁니다.build_context의 순서: Knowledge → Conversation → State. 장기 지식이 가장 먼저, 현재 상태가 가장 나중에 나옵니다. 이것은 추론 샌드위치 패턴의 변형으로, 모델이 마지막에 읽은 “현재 상태”에 가장 강하게 반응하도록 유도합니다.- 키워드 기반
recall: 프로덕션에서는 반드시 임베딩 기반 시멘틱 검색으로 교체해야 합니다. 키워드 매칭은 “DB 연결”과 “데이터베이스 커넥션”의 동일성을 인식하지 못합니다.
실전 고려사항 — 벡터 DB와 임베딩 전략
장기 메모리를 프로덕션에 올리려면 벡터 데이터베이스와 임베딩 모델의 선택이 필요합니다. 2026년 현재 주요 옵션을 비교합니다:
| 벡터 DB | 유형 | 장점 | 적합 시나리오 |
|---|---|---|---|
| Chroma | 임베디드 (in-process) | 설치 간편, Python 네이티브 | 단일 에이전트, 프로토타입 |
| Qdrant | 서버 / 임베디드 | 고성능 필터링, Rust 기반 | 중규모 프로덕션 |
| Pinecone | 관리형 SaaS | 운영 부담 제로, 자동 스케일 | 대규모 멀티테넌트 |
| pgvector | PostgreSQL 확장 | 기존 DB 인프라 활용 | 이미 PG를 쓰는 프로젝트 |
임베딩 모델은 검색 품질에 직접적인 영향을 미칩니다. 한국어를 다루는 경우 다국어 임베딩 모델(예: multilingual-e5, BGE-M3)이 필수입니다. 영어 전용 모델은 한국어 시멘틱 유사도를 정확히 포착하지 못합니다.
핵심 설계 결정 하나: 청킹(Chunking) 전략. 장기 메모리에 저장할 텍스트를 어떤 단위로 쪼개 임베딩할 것인가?
- 문장 단위: 검색 정밀도 높지만, 맥락을 잃을 수 있음.
- 문단 단위: 맥락 보존과 정밀도의 균형.
- 의미 단위: “하나의 사실/결정/이벤트”를 하나의 청크로. 가장 효과적이지만 분할 로직이 복잡.
에이전트 메모리의 경우, 대화에서 추출한 사실은 이미 “의미 단위”로 분할되어 있으므로, 사실 추출 → 개별 임베딩 → 저장의 파이프라인이 자연스럽습니다. 파일에서 읽은 문서는 문단 단위 청킹이 실용적입니다.
메모리와 다른 컴포넌트의 상호작용
메모리 아키텍처는 독립적으로 존재하지 않습니다. 이전 회차에서 다뤘던 다른 컴포넌트들과 긴밀히 연동됩니다.
컨텍스트 엔지니어링 × 메모리 (4화 연결)
4화에서 다뤘던 토큰 예산 관리는 메모리 아키텍처와 제로섬 관계에 있습니다. 메모리에 할당하는 토큰이 많을수록 현재 턴의 추론에 쓸 수 있는 토큰이 줄어듭니다. 이것이 메모리-추론 트레이드오프(Memory-Reasoning Tradeoff)입니다.
예시: 200K 토큰 컨텍스트 윈도우에서의 예산 배분:
| 영역 | 토큰 배분 | 비율 |
|---|---|---|
| 시스템 프롬프트 + 부트 메모리 | ~15K | 7.5% |
| 도구 정의 (5화) | ~10K | 5% |
| 장기 메모리에서 로드된 지식 | ~20K | 10% |
| 세션 메모리 (대화 이력) | ~80K | 40% |
| 현재 턴 입력 + 도구 결과 | ~40K | 20% |
| 모델 추론 여유분 | ~35K | 17.5% |
이 배분이 무너지면 성능이 급락합니다. 세션 메모리가 120K까지 팽창하면 추론 여유분이 거의 사라지고, 모델은 “생각할 공간”이 부족해져 단순한 판단도 잘못하기 시작합니다. 압축이 선택이 아니라 필수인 이유가 여기 있습니다.
도구 인터페이스 × 메모리 (5화 연결)
5화에서 다뤘던 도구 호출의 결과는 세션 메모리에 축적됩니다. 파일 읽기, 검색 결과, API 응답 — 이 모든 것이 세션 메모리를 빠르게 부풀립니다. 특히 대용량 파일 읽기는 한 번의 도구 호출로 수만 토큰을 소비할 수 있습니다.
따라서 도구 결과의 메모리 관리 전략이 필요합니다:
- 대용량 도구 결과는 즉시 요약하고 원본은 폐기
- 반복 호출 가능한 도구 결과(예: 파일 내용)는 “경로만 기억, 내용은 필요 시 재호출”
- 도구 에러는 해결될 때까지 랜드마크로 고정
내가 겪은 Harness 실패담 — 음성 파이프라인의 기억 상실
몇 달 전, 음성·STT 파이프라인 기반의 고객 상담 에이전트를 구축한 적이 있습니다. 음성 입력을 텍스트로 변환하고, 에이전트가 응답하고, 다시 TTS로 재생하는 구조였죠.
문제는 STT의 청크 단위 전사에서 시작됐습니다. 음성 인식은 실시간으로 진행되므로, 하나의 발화가 여러 청크로 쪼개져 들어옵니다. “주문번호는”(청크 1) + “A12345″(청크 2) + “입니다”(청크 3) 이런 식으로요. 각 청크가 별도의 턴으로 처리되니, 작업 메모리 없이는 에이전트가 “A12345가 뭐죠?”라고 반문하는 사태가 벌어졌습니다.
더 심각한 문제는 세션 간 기억 소실이었습니다. 고객이 전화를 끊었다가 30분 뒤 다시 걸면, 에이전트는 아까의 대화를 전혀 기억하지 못했습니다. “아까 말씀드린 환불 건인데요” → “어떤 건을 말씀하시는지 알려주시겠어요?” 고객 만족도가 바닥을 쳤습니다.
결국 3계층 메모리를 도입해 해결했습니다. 작업 메모리에 STT 청크를 버퍼링해 완전한 발화 단위로 재조립하고, 장기 메모리에 고객별 상담 이력을 저장해 재접속 시 복원했습니다. 메모리 아키텍처를 도입한 후 첫 통화 해결률이 42%에서 71%로 올랐습니다. 모델은 그대로, 하니스만 바꿨을 뿐인데.
이 경험이 본 시리즈의 핵심 주제 — “모델보다 래퍼” — 를 체감하게 해준 결정적 사건이었습니다.
메모리 아키텍처 도입 체크리스트
이번 회차의 내용을 실전에 적용할 때 참고할 체크리스트입니다:
- □ 작업 메모리 정의: 에이전트가 매 턴 유지해야 하는 상태 변수를 구조화된 스키마로 정의했는가?
- □ 세션 메모리 예산: 세션 메모리에 할당할 최대 토큰을 정했는가? (전체 컨텍스트의 40% 이내 권장)
- □ 압축 트리거: 세션 메모리가 예산을 초과할 때 어떤 압축 전략을 사용할 것인가?
- □ 장기 메모리 저장소: 파일 기반(CLAUDE.md) vs 벡터 DB vs RDBMS 중 선택했는가?
- □ 부트 메모리 작성: 프로젝트의 CLAUDE.md / .cursorrules를 200줄 이내로 작성했는가?
- □ GC 정책: 장기 메모리의 만료·무효화 정책이 있는가?
- □ 메모리-추론 예산 배분: 메모리가 추론 공간을 잠식하지 않도록 예산 배분을 설정했는가?
- □ 30턴 이상 테스트: 30턴 이상의 긴 대화에서 컨텍스트 부패가 발생하지 않는지 테스트했는가?
이번 글의 한 줄 요약
에이전트의 기억을 Working(레지스터) · Session(RAM) · Long-term(디스크) 3계층으로 분리하고, OS의 메모리 매니저처럼 승격·압축·GC를 관리해야 컨텍스트 부패 없이 장기 작업을 수행할 수 있다.
다음 회차 예고 — 컨트롤 루프와 랄프 루프(Ralph Loop)
지금까지 4~6화에 걸쳐 하니스의 세 가지 핵심 컴포넌트를 살펴봤습니다: 컨텍스트 엔지니어링(공간), 도구 인터페이스(행동), 메모리 아키텍처(시간). 이것들이 하니스의 재료라면, 다음 7화에서 다룰 컨트롤 루프(Control Loop)는 이 재료들을 조리하는 셰프입니다.
에이전트가 “생각 → 행동 → 관찰 → 생각”의 루프를 어떻게 돌리는가? Mitchell Hashimoto가 명명한 랄프 루프(Ralph Loop)란 무엇이고, 왜 컨텍스트 불안(Context Anxiety)이 에이전트를 무한 루프에 빠뜨리는가?
7화에서 하니스의 심장부 — 컨트롤 루프의 설계를 해부합니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 5화 (다음 차수는 아직 게시되지 않았습니다)
[…] AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 (총 12화 중 7화)◀ 이전 6화 (다음 차수는 아직 게시되지 않았습니다) 카테고리: IT기술 […]