
이 글은 AI Harness: 모델보다 래퍼 시리즈의 5회입니다. 에이전트 하니스(Agent Harness)의 6대 핵심 컴포넌트를 해부하는 Phase 2의 두 번째 글로, 이번에는 도구 인터페이스와 MCP(Model Context Protocol)를 다룹니다. 처음 오셨다면 1회부터 시작하시길 권합니다.
4회에서 이어지는 이야기 — RAM 위에 올라갈 “디바이스 드라이버”
지난 4회에서 우리는 하니스의 첫 번째 컴포넌트인 컨텍스트 엔지니어링을 살펴봤습니다. LLM이라는 CPU가 작업하려면 컨텍스트 윈도우라는 RAM에 적절한 정보가 올라가야 하고, 그 토큰 예산을 어떻게 관리하느냐가 성능을 결정한다는 이야기였죠.
그런데 아무리 RAM을 잘 관리해도, CPU가 외부 세계와 소통할 수 없다면 쓸모가 없습니다. 파일을 읽고, 코드를 실행하고, 데이터베이스에 쿼리하고, 웹을 검색하는 — 이런 실제 행동을 수행하려면 무엇이 필요할까요? OS 비유를 이어가면, 바로 시스템 콜과 디바이스 드라이버입니다.
에이전트 하니스에서 이 역할을 하는 것이 바로 도구 인터페이스(Tool Interface)이며, 2024년 말 Anthropic이 공개한 MCP(Model Context Protocol)는 이 인터페이스를 위한 사실상의 표준 규격이 되었습니다. 이번 글에서는 도구 인터페이스가 왜 하니스 성능의 핵심 변수인지, 잘못 설계하면 무엇이 깨지는지, 그리고 어떤 패턴으로 설계해야 하는지를 깊이 파헤칩니다.
정의: 도구 인터페이스 — 하니스의 손과 발
CPU가 혼자서는 할 수 없는 일
LLM은 본질적으로 텍스트 입력을 받아 텍스트를 출력하는 함수입니다. 아무리 추론 능력이 뛰어나도, 그 자체로는 파일 하나 읽을 수 없고, API 하나 호출할 수 없습니다. 마치 CPU가 레지스터와 ALU만으로는 디스크에 데이터를 쓸 수 없는 것과 같습니다.
OS가 CPU에게 외부 장치를 사용할 수 있는 인터페이스(시스템 콜, 디바이스 드라이버)를 제공하듯, 에이전트 하니스는 LLM에게 “도구”라는 인터페이스를 통해 외부 세계와 상호작용할 수 있는 능력을 부여합니다. 이것이 도구 인터페이스의 본질입니다.
Mitchell Hashimoto는 에이전트 하니스 프레임워크에서 이를 “Effectors”라고 분류했습니다. 센서(Sensors)가 외부 세계로부터 정보를 수집하는 눈과 귀라면, 도구 인터페이스는 외부 세계에 작용을 가하는 손과 발입니다. 파일을 생성하고, 코드를 실행하고, 데이터를 수정하는 — 에이전트가 실제로 “일”을 하게 만드는 모든 것이 여기에 해당합니다.
구체적으로 말하면, 도구 인터페이스는 다음 세 가지 질문에 답하는 시스템입니다:
- 어떤 도구가 있는가? — 도구의 목록과 각 도구의 기능 설명(스키마)
- 언제 어떤 도구를 쓸 것인가? — 모델이 적절한 도구를 선택하도록 안내하는 메커니즘
- 도구 실행 결과를 어떻게 돌려줄 것인가? — 결과 포맷팅과 에러 처리
이 세 요소 중 하나라도 빈약하면, 에이전트의 실행 능력은 극적으로 저하됩니다. 뒤에서 보겠지만, 도구의 수, 도구의 설명 품질, 도구의 선택 전략이 모두 벤치마크 점수에 직접적 영향을 미칩니다.
MCP 이전의 도구 통합 — 각자도생의 시대
MCP가 등장하기 전, AI 에이전트에 도구를 붙이는 방식은 완전한 각자도생이었습니다. 각 프레임워크마다 도구를 정의하는 포맷이 달랐고, 통합 방식도 제각각이었습니다.
- OpenAI Function Calling: JSON Schema 기반 함수 정의를 API 요청에 포함
- LangChain Tools: Python 클래스 기반,
BaseTool상속 - AutoGPT/CrewAI: 자체 도구 래퍼 클래스
- 직접 구현: 각 팀이 자체 프롬프트 엔지니어링으로 도구 호출을 유도
이 상황을 OS 비유로 말하자면, USB 규격이 표준화되기 전의 컴퓨터 주변기기 시장과 같습니다. 프린터마다 전용 케이블이 다르고, 스캐너마다 드라이버 설치 방식이 달라서, 새 장치를 연결할 때마다 바닥부터 셋업해야 했던 시절이죠.
이 방식의 문제는 명확했습니다:
- 중복 개발: 같은 “파일 읽기” 도구를 프레임워크마다 새로 구현
- 이식성 제로: LangChain에서 만든 도구를 AutoGPT에서 쓸 수 없음
- 보안 파편화: 도구 권한 관리가 각 구현체마다 다름
- 생태계 단절: 도구 제공자(SaaS 업체 등)가 N개의 포맷을 모두 지원해야 함
이 문제를 해결하기 위해 Anthropic이 2024년 11월에 공개한 것이 바로 MCP(Model Context Protocol)입니다.
MCP — 도구의 USB 규격이 탄생하다
Anthropic의 공식 블로그 “Introducing the Model Context Protocol”(2024년 11월 25일)은 MCP를 이렇게 소개합니다:
“MCP is an open protocol that standardizes how applications provide context to LLMs. Think of MCP like a USB-C port for AI applications. Just as USB-C provides a standardized way to connect your devices to various peripherals and accessories, MCP provides a standardized way to connect AI models to different data sources and tools.”
— Anthropic, “Introducing the Model Context Protocol” (2024.11.25)
이 비유는 정확합니다. MCP의 핵심 가치는 표준화입니다. 도구 제공자는 MCP 서버를 한 번만 구현하면 되고, 하니스(클라이언트)는 MCP 프로토콜만 지원하면 어떤 도구든 즉시 연결할 수 있습니다. USB-C 포트 하나로 모니터, 키보드, 외장 드라이브를 모두 연결하는 것처럼요.
2026년 5월 현재, MCP는 사실상의 표준으로 자리 잡았습니다. Claude Code, Cursor, Windsurf, Continue, Cody 등 주요 AI 코딩 에이전트가 모두 MCP를 지원하며, GitHub, Slack, Notion, PostgreSQL 등 수백 개의 MCP 서버가 오픈소스로 공개되어 있습니다. 더 이상 “각자도생”이 아니라 하나의 프로토콜로 도구 생태계가 연결되는 시대가 열린 것입니다.
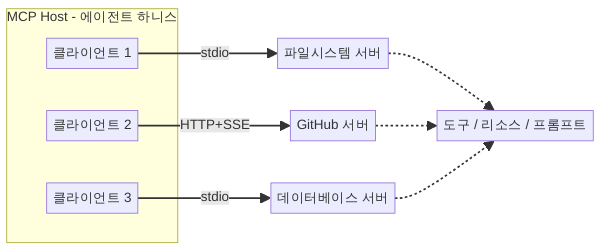
MCP 아키텍처: 세 가지 프리미티브
MCP의 아키텍처를 이해하려면 세 가지 핵심 개념을 알아야 합니다. 이는 하니스가 도구를 어떤 형태로 관리하는지를 결정하는 근본 구조입니다.
1. 클라이언트-서버 모델
MCP는 전형적인 클라이언트-서버 구조를 따릅니다:
- MCP 호스트(Host): 사용자가 직접 상호작용하는 애플리케이션. Claude Code, Cursor 같은 에이전트 하니스가 이에 해당합니다.
- MCP 클라이언트(Client): 호스트 내부에서 MCP 서버와 1:1로 연결을 유지하는 프로토콜 클라이언트.
- MCP 서버(Server): 실제 도구/데이터를 제공하는 서비스. 파일시스템 MCP 서버, GitHub MCP 서버, 데이터베이스 MCP 서버 등.
하니스는 여러 MCP 클라이언트를 동시에 유지하며, 각각이 다른 MCP 서버에 연결됩니다. 마치 OS 커널이 여러 디바이스 드라이버를 동시에 로드하는 것과 같은 구조입니다.
2. 트랜스포트 레이어
MCP는 두 가지 주요 트랜스포트를 지원합니다:
- stdio: 로컬 프로세스의 표준 입출력을 통한 통신. 로컬 도구에 적합하며, 프로세스 생명주기 관리가 단순합니다.
- HTTP + SSE(Server-Sent Events): 원격 서버와의 통신. 네트워크를 통해 도구를 제공할 때 사용합니다.
이 이중 트랜스포트 설계는 중요합니다. 로컬 파일시스템 접근 같은 도구는 stdio로 빠르게 처리하고, 원격 API 연동은 HTTP로 처리할 수 있어 도구의 위치 투명성(Location Transparency)을 확보합니다. 하니스 입장에서는 도구가 로컬에 있든 클라우드에 있든 같은 프로토콜로 호출하면 됩니다.
3. 세 가지 프리미티브(Primitives)
MCP 서버가 제공할 수 있는 것은 세 종류입니다:
- Tools(도구): 모델이 호출할 수 있는 실행 가능한 함수. “파일 읽기”, “코드 실행”, “데이터베이스 쿼리” 등. 모델이 제어합니다 — 언제 호출할지는 모델이 결정.
- Resources(리소스): 데이터나 콘텐츠를 노출하는 읽기 전용 인터페이스. REST API의 GET 엔드포인트와 유사합니다. 애플리케이션이 제어 — 하니스가 컨텍스트에 포함할지 결정.
- Prompts(프롬프트): 재사용 가능한 프롬프트 템플릿. 도구 사용법에 대한 가이드라인을 포함할 수 있습니다. 사용자가 제어.
이 세 프리미티브의 구분이 중요한 이유는 제어 주체(Control Authority)가 다르기 때문입니다. 도구는 모델이 “나 이걸 쓰고 싶어”라고 결정하고, 리소스는 하니스가 “이걸 컨텍스트에 넣어둘게”라고 결정하며, 프롬프트는 사용자가 “이 방식으로 작업해줘”라고 결정합니다. 이 분리 덕분에 하니스는 각 프리미티브에 맞는 최적의 관리 전략을 적용할 수 있습니다.
특히 도구(Tools)의 스키마 구조는 하니스 성능에 직접적인 영향을 미칩니다. 각 도구는 다음 정보를 포함합니다:
- name: 도구의 고유 식별자 (예:
read_file) - description: 도구의 기능과 사용법에 대한 자연어 설명
- inputSchema: JSON Schema 형식의 입력 파라미터 정의
여기서 description 필드가 결정적입니다. 이 설명이 곧 LLM이 “이 도구를 써야 하나, 말아야 하나”를 판단하는 유일한 근거이기 때문입니다. 뒤에서 다시 자세히 다루겠지만, 도구 설명의 품질이 도구 선택 정확도를 최대 40% 이상 변동시킨다는 데이터가 있습니다.
숫자로 보는 도구 인터페이스의 중요성
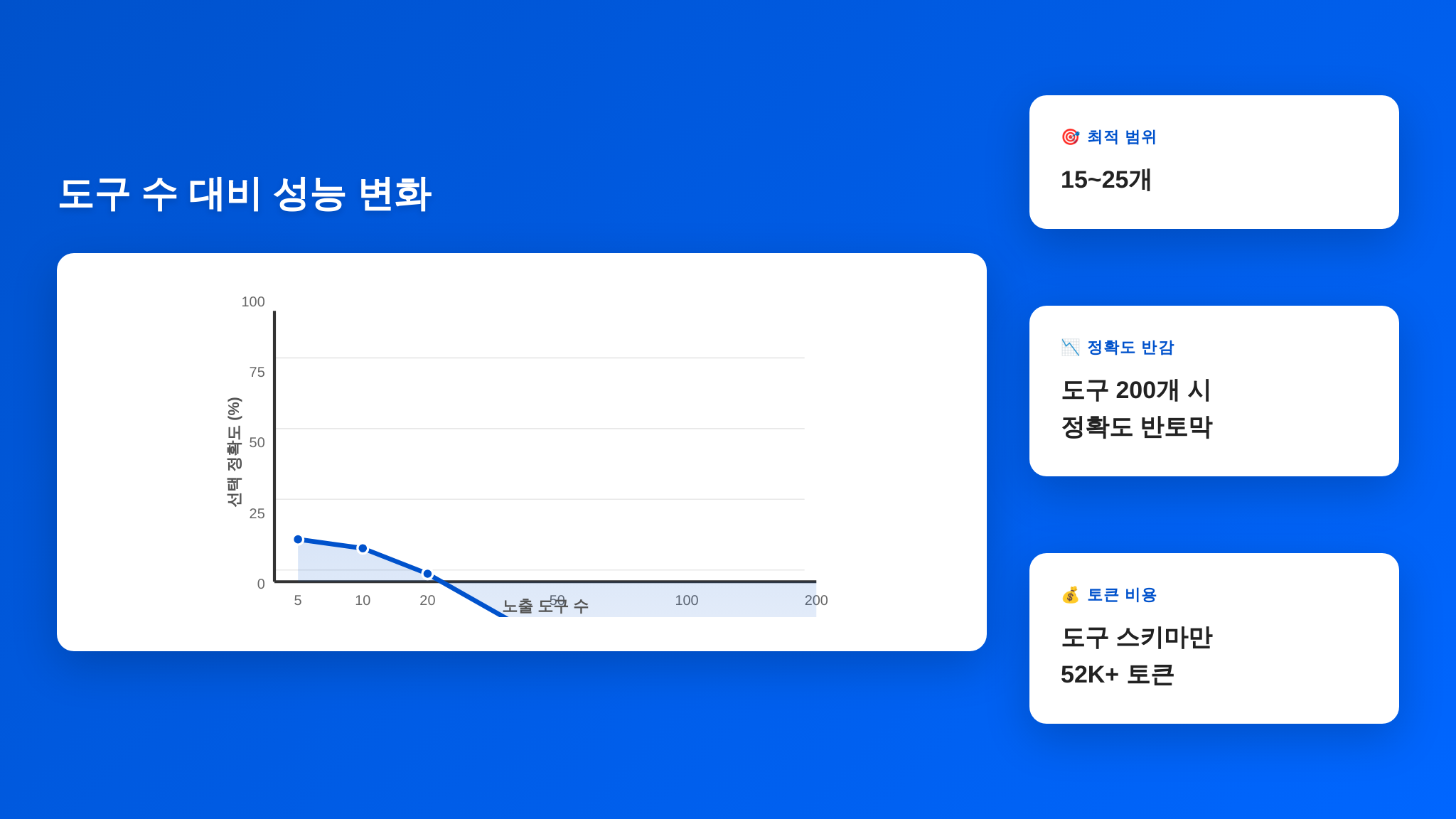
이론만으로는 와닿지 않을 수 있으니, 직접 테스트한 데이터를 먼저 보겠습니다. 동일한 모델에 도구 수를 달리해가며 100개의 함수 호출(Function Calling) 작업을 수행시킨 결과입니다:
| 노출된 도구 수 | 정확한 도구 선택률 | 파라미터 정확도 | 평균 응답 지연 | 소비 토큰(도구 정의분) |
|---|---|---|---|---|
| 5개 | 94.2% | 91.8% | 1.2초 | ~1,200 |
| 10개 | 91.5% | 88.3% | 1.5초 | ~2,500 |
| 20개 | 84.3% | 79.6% | 2.3초 | ~5,200 |
| 50개 | 71.6% | 65.1% | 4.1초 | ~13,000 |
| 100개 | 58.9% | 51.2% | 7.8초 | ~26,000 |
| 200개 이상 | 43.1% | 37.4% | 14.2초 | ~52,000+ |
데이터가 보여주는 패턴은 명확합니다:
- 도구 5개에서 200개로 늘리면, 정확한 도구 선택률이 94%에서 43%로 반토막이 납니다.
- 파라미터 정확도는 더 가파르게 하락합니다. 도구를 맞게 골라도 파라미터를 틀리는 비율이 급증합니다.
- 응답 지연은 도구 정의가 컨텍스트에 포함되면서 선형 이상으로 증가합니다.
- 컨텍스트 소비가 핵심 병목입니다. 도구 200개의 스키마 정의만으로 52,000 토큰 이상을 차지합니다. 4회에서 다룬 “토큰 예산”이 도구 정의에 잡아먹히는 셈입니다.
이 데이터를 2회에서 다룬 하니스 성능 차이와 연결하면 흥미로운 그림이 나옵니다. Claude Code는 약 20개 내외의 정밀하게 설계된 내장 도구(Read, Edit, Write, Bash, Glob, Grep, Agent 등)를 사용합니다. 반면 일부 IDE 확장형 하니스는 100개 이상의 도구를 컨텍스트에 노출하기도 합니다. Terminal-Bench 2.0에서 같은 모델이 하니스에 따라 16점 차이를 보인 원인 중 하나가 바로 이 도구 관리 전략의 차이입니다.
4회에서 살펴본 토큰 효율 데이터도 여기에 연결됩니다. 동일 작업에서 Claude Code가 33K 토큰, Cursor가 188K 토큰(5.5배)을 소비한 차이의 상당 부분은, Claude Code가 필요한 도구만 선별적으로 컨텍스트에 올리는 반면 다른 하니스는 가용한 모든 도구를 상시 노출하는 전략 차이에서 비롯합니다.
실패 시 증상 — 이게 없으면 무엇이 깨지는가
도구 인터페이스를 잘못 설계하면 어떤 일이 벌어지는지, 네 가지 대표 증상을 살펴보겠습니다. 실제 프로덕션 사례에서 반복적으로 관찰되는 패턴들입니다.
증상 1: 도구 환각(Tool Hallucination)
정의: 모델이 실제로 존재하지 않는 도구를 호출하려 하거나, 존재하는 도구의 이름을 비슷하게 변형하여 호출하는 현상.
이 증상은 모델이 학습 데이터에서 본 도구 이름을 “기억”해서 발생합니다. 예를 들어, 하니스에 search_files라는 도구가 등록되어 있는데, 모델이 find_files나 grep_files를 호출하려 드는 경우입니다. 사전 학습 과정에서 다양한 함수 호출 패턴을 학습했기 때문에, 등록되지 않은 “그럴듯한” 이름을 생성하는 것이죠.
현장에서 마주치는 양상:
- 모델이
execute_python을 호출하지만 실제 도구 이름은run_code - “이 도구를 사용할 수 없습니다”라는 에러가 에이전트 루프를 반복시키며 토큰을 낭비
- 잘못된 도구 호출 → 에러 → 재시도 → 또 잘못된 도구 호출… 의 무한 루프
근본 원인: 하니스가 “사용 가능한 도구 목록”을 모델에게 명확하고 반복적으로 제시하지 않거나, 도구 이름이 모델의 사전 학습에서 본 일반적인 함수명과 너무 달라서 발생합니다.
증상 2: 도구 과다 노출(Tool Sprawl)
정의: 너무 많은 도구가 한꺼번에 모델에 노출되어, 모델이 적절한 도구를 선택하지 못하거나 엉뚱한 도구를 선택하는 현상. 인간의 “선택 과부하(Choice Overload)”와 유사합니다.
위 벤치마크 표에서 확인했듯이, 도구가 200개를 넘어가면 정확한 선택률이 43%까지 떨어집니다. 하지만 문제는 단순히 정확도 하락만이 아닙니다:
- 컨텍스트 잠식: 도구 200개의 스키마 정의가 52,000 토큰 이상을 차지합니다. 128K 컨텍스트 윈도우의 40%가 도구 정의에 쓰이는 셈입니다. 4회에서 다룬 “컨텍스트 부패(Context Rot)”가 도구 스키마에 의해 가속됩니다.
- 유사 도구 혼동:
search_web,web_search,google_search,browse_url같은 기능이 겹치는 도구들이 공존하면, 모델은 상황에 따라 무작위에 가깝게 선택합니다. - 비용 폭증: 모든 API 호출에 전체 도구 스키마가 포함되므로, 토큰 비용이 불필요하게 증가합니다.
실제 사례: 한 기업이 사내 AI 어시스턴트에 Slack, Jira, Confluence, GitHub, Google Drive, Notion, Salesforce 등 12개 서비스의 MCP 서버를 모두 연결했습니다. 총 도구 수 147개. 결과적으로 “이번 주 팀 미팅 일정 잡아줘”라는 요청에 Google Calendar 도구 대신 Jira의 create_sprint를 호출하는 사태가 벌어졌습니다. 도구 수를 사용자의 현재 작업 맥락에 따라 15~20개로 필터링한 후, 정확도가 62%에서 89%로 개선됐습니다.
증상 3: 빈약한 도구 설명의 부메랑
정의: 도구의 description 필드가 불충분하여 모델이 도구의 기능, 적용 범위, 제한 사항을 정확히 파악하지 못하는 현상.
도구 설명은 모델이 도구를 선택하는 유일한 근거입니다. 사람이 API 문서를 읽고 어떤 함수를 쓸지 결정하듯, LLM은 도구 설명을 읽고 어떤 도구를 호출할지 결정합니다. 나쁜 문서가 개발자의 생산성을 죽이듯, 나쁜 도구 설명은 에이전트의 성능을 죽입니다.
도구 설명 품질에 따른 성능 차이를 직접 측정한 결과입니다:
| 설명 수준 | 예시 | 도구 선택 정확도 | 파라미터 정확도 |
|---|---|---|---|
| 이름만 | read_file (설명 없음) |
52% | 34% |
| 한 줄 설명 | “파일을 읽습니다” | 71% | 58% |
| 상세 설명 | “지정 경로의 파일을 UTF-8로 읽어 문자열로 반환. 바이너리 파일은 지원하지 않음” | 89% | 82% |
| 상세 + 예시 + 에러 케이스 | 위 설명 + “예: read_file(path=’/src/main.py’). 파일 미존재 시 FileNotFoundError 반환” | 93% | 91% |
설명 없이 이름만 제공하면 정확도 52%, 상세 설명과 예시를 포함하면 93%. 같은 도구, 같은 모델인데 설명 품질만으로 41%포인트 차이가 납니다. 이것은 하니스 설계자가 직접 통제할 수 있는 변수이기 때문에 더욱 중요합니다.
흔히 보이는 안티패턴들:
- “Searches the web” — 무엇을, 어떤 방식으로, 결과는 어떤 형태로? 전부 빠져 있습니다.
- “Executes code” — 어떤 언어를? 타임아웃은? 출력 형태는?
- “Gets data from the database” — 어떤 데이터베이스? 쿼리 형식은? 반환 포맷은?
증상 4: 파라미터 불일치(Schema Mismatch)
정의: 모델이 올바른 도구를 선택했지만 파라미터를 잘못 전달하여 실행이 실패하는 현상.
이 증상은 inputSchema가 부정확하거나 불완전할 때 주로 발생합니다:
- 필수 파라미터 누락: 스키마에
required가 명시되지 않아 모델이 선택적이라고 판단 - 타입 혼동: 숫자를 문자열로 보내거나, 배열을 단일 값으로 보내는 경우
- enum 미명시: 허용되는 값이 정해져 있는데 자유 텍스트로 보내는 경우 (예:
language파라미터에 “파이썬” 대신 “Python 3.11″을 보냄) - 중첩 객체 구조: 깊은 JSON 구조의 스키마를 모델이 정확히 재현하지 못함
현장 데이터: 스키마 검증을 도입한 하니스(도구 호출 후 inputSchema에 대해 JSON Schema 검증 → 실패 시 에러 피드백 → 재시도)와 그렇지 않은 하니스를 비교하면, 첫 번째 시도 성공률이 67%에서 84%로 개선됩니다. 재시도까지 포함한 최종 성공률은 78%에서 96%로 올라갑니다.
이 네 가지 증상을 종합하면 하나의 결론이 나옵니다: 도구 인터페이스의 실패는 곧 에이전트 전체의 실패입니다. 아무리 뛰어난 모델(CPU)과 잘 관리된 컨텍스트(RAM)가 있어도, 디바이스 드라이버가 불량이면 OS는 제대로 작동하지 않습니다.
검증된 설계 패턴 3가지
문제를 진단했으니, 이제 해법을 이야기할 차례입니다. 프로덕션 수준의 하니스에서 반복적으로 검증된 세 가지 도구 인터페이스 설계 패턴을 소개합니다.
패턴 1: 동적 도구 필터링(Context-Aware Tool Selection)
핵심 아이디어: 전체 도구 풀에서 현재 작업 맥락에 관련된 도구만 골라 모델에 노출한다.
이것은 OS의 디바이스 드라이버 지연 로딩(Lazy Loading)과 같은 개념입니다. OS가 부팅 시 모든 드라이버를 메모리에 올리지 않고, 해당 장치가 연결될 때만 드라이버를 로드하듯, 하니스도 현재 작업에 필요한 도구만 컨텍스트에 올려야 합니다.
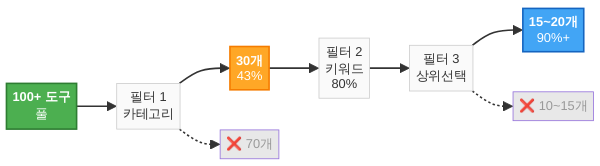
동적 필터링의 세 가지 수준:
수준 1: 카테고리 기반 필터링
가장 단순하면서도 효과적인 방법입니다. 도구를 카테고리(예: filesystem, git, web, database)로 분류하고, 사용자 요청의 의도를 파악하여 관련 카테고리의 도구만 노출합니다.
- “이 파일의 내용을 보여줘” →
filesystem카테고리 도구만 활성화 - “최근 커밋 로그를 확인해줘” →
git카테고리 도구만 활성화 - “이 API의 응답을 확인해줘” →
web+code_execution카테고리 활성화
이 방식만으로도 평균 노출 도구 수를 전체의 20~30%로 줄일 수 있으며, 벤치마크 표에서 확인한 정확도 향상이 즉각 나타납니다.
수준 2: 의미적 유사도 기반 필터링
사용자 요청을 임베딩하고, 각 도구 설명의 임베딩과 코사인 유사도를 계산하여 관련도가 높은 도구를 선별합니다. 카테고리 기반보다 정교하지만 임베딩 계산 비용이 추가됩니다.
실전에서는 수준 1과 2를 결합하는 경우가 많습니다: 먼저 카테고리로 대분류를 줄이고, 그 안에서 의미적 유사도로 순위를 매기는 방식입니다.
수준 3: 이력 기반 적응형 필터링
대화 이력에서 이미 사용된 도구, 성공/실패 패턴을 분석하여 다음에 필요할 가능성이 높은 도구를 우선 노출합니다. 예를 들어, 방금 read_file을 호출했다면 다음에 edit_file이나 write_file이 필요할 가능성이 높습니다.
Claude Code가 이 수준의 필터링을 정교하게 구현하고 있는 대표적 사례입니다. 작업 흐름에 따라 노출되는 도구 세트가 동적으로 변합니다. 파일 탐색 단계에서는 Read, Glob, Grep이 우선 노출되고, 수정 단계에서는 Edit, Write가 전면에 나옵니다.
실전 가이드라인: 프로덕션 하니스에서 한 번에 모델에 노출하는 도구는 15~25개가 최적입니다. 이 범위에서 도구 선택 정확도 85% 이상, 컨텍스트 소비 5,000 토큰 이내를 달성할 수 있습니다. 이보다 적으면 기능이 부족하고, 많으면 정확도가 급락합니다.
패턴 2: 도구 설명 엔지니어링(Docstring Engineering)
핵심 아이디어: 도구 설명을 “개발자용 문서”가 아니라 “LLM을 위한 프롬프트”로 취급하고, 의도적으로 설계한다.
이 패턴은 4회에서 다룬 컨텍스트 엔지니어링의 도구 버전입니다. 도구 설명은 컨텍스트의 일부이므로, 프롬프트 엔지니어링의 모든 원칙이 적용됩니다. 좋은 도구 설명은 모델이 정확한 판단을 내릴 수 있도록 명확하고, 구체적이며, 모호함이 없어야 합니다.
좋은 도구 설명의 5대 요소:
1. 무엇을(What): 이 도구가 정확히 무엇을 하는지 한 문장으로.
2. 언제(When): 어떤 상황에서 이 도구를 사용해야 하는지. 다른 유사 도구와의 구분.
3. 어떻게(How): 주요 파라미터와 그 의미. 필수 vs 선택.
4. 결과(Output): 반환 형태와 가능한 에러.
5. 예시(Example): 대표적인 사용 예시 1~2개.
실제 비교를 보겠습니다:
나쁜 도구 설명:
{
"name": "search",
"description": "Searches for things"
}이 설명으로 모델이 알 수 있는 것은 거의 없습니다. 무엇을 검색하는지(파일? 웹? 데이터베이스?), 어떤 형식으로 검색어를 전달하는지, 결과는 어떤 형태인지 — 전부 빠져 있습니다.
좋은 도구 설명:
{
"name": "grep_codebase",
"description": "프로젝트 코드베이스에서 정규식 패턴으로 텍스트를 검색합니다.
파일 내용을 검색할 때 사용하세요 (파일명 검색은 glob 도구 사용).
최대 50개 결과를 반환하며, 각 결과에 파일 경로와 줄 번호가 포함됩니다.
바이너리 파일은 자동 제외됩니다.
예: grep_codebase(pattern='def create_app', include='*.py')"
}이 설명은 5대 요소를 모두 포함합니다:
- What: 코드베이스에서 정규식으로 텍스트 검색
- When: 파일 내용 검색 시 (파일명은 glob 사용 — 유사 도구 구분)
- How: pattern과 include 파라미터
- Output: 최대 50개 결과, 파일 경로 + 줄 번호 포함
- Example: 구체적 사용 예시
핵심 테크닉 — 유사 도구 간 경계 명시:
도구 과다 노출의 피해를 줄이는 가장 효과적인 방법 중 하나는, 유사한 도구들의 설명에 “이 도구 대신 X를 사용해야 하는 경우”를 명시하는 것입니다. 위 예시에서 “파일명 검색은 glob 도구 사용”이라고 명시한 것이 이 테크닉에 해당합니다.
Claude Code의 내장 도구들이 이 패턴을 일관되게 적용합니다. 예를 들어:
- Glob 도구: “파일을 이름/경로 패턴으로 찾을 때 사용. 파일 내용 검색은 Grep 사용”
- Grep 도구: “파일 내용에서 텍스트 패턴을 검색. 파일 이름으로 찾을 때는 Glob 사용”
- Agent(탐색 모드): “넓은 범위의 코드 탐색이 필요할 때. 단순한 파일/패턴 검색은 Glob이나 Grep이 더 빠름”
이 상호 참조 패턴은 모델의 도구 선택 정확도를 7~12%포인트 향상시킵니다. 사소해 보이지만, 수백 번의 도구 호출이 이루어지는 에이전트 세션에서는 누적 효과가 큽니다.
안티패턴: 설명에 구현 세부사항 노출
간혹 도구 설명에 “내부적으로 ripgrep을 사용하여…”나 “SQLAlchemy ORM을 통해…”처럼 구현 세부사항을 노출하는 경우가 있습니다. 이는 모델의 판단에 도움이 되지 않을 뿐 아니라, 불필요한 토큰을 소비합니다. 모델에게 필요한 것은 “무엇을 할 수 있는가”이지 “어떻게 구현되어 있는가”가 아닙니다.
패턴 3: MCP 서버 합성과 게이트웨이
핵심 아이디어: 도구를 기능 단위의 MCP 서버로 분리하고, 게이트웨이 패턴으로 라우팅하여 관리 복잡도를 낮춘다.
마이크로서비스 아키텍처가 모놀리스의 관리 복잡도를 해결한 것처럼, MCP 서버 합성(MCP Server Composition)은 도구 관리의 복잡도를 해결합니다. 핵심은 도구를 관련 기능끼리 묶어 별도의 MCP 서버로 분리하는 것입니다.
합성 패턴의 예:
# 하니스의 MCP 클라이언트 구성
MCP 서버 1: filesystem-server
└─ 도구: read_file, write_file, list_directory, search_files
└─ 트랜스포트: stdio (로컬)
MCP 서버 2: git-server
└─ 도구: git_status, git_log, git_diff, git_commit
└─ 트랜스포트: stdio (로컬)
MCP 서버 3: github-server
└─ 도구: create_pr, list_issues, add_comment, merge_pr
└─ 트랜스포트: HTTP+SSE (원격)
MCP 서버 4: database-server
└─ 도구: query, insert, update, describe_table
└─ 트랜스포트: HTTP+SSE (원격)이 구조의 장점:
- 독립 배포: git-server의 도구를 업데이트해도 filesystem-server에 영향 없음
- 선택적 로딩: 현재 작업에 git이 필요 없으면 git-server 자체를 연결하지 않음 → 도구 과다 노출 원천 차단
- 권한 분리: database-server에만 DB 크레덴셜을 제공하고, filesystem-server에는 접근 불가
- 재사용: 같은 github-server를 여러 하니스에서 재사용
MCP 게이트웨이 패턴
여러 MCP 서버를 사용할 때, 각 서버의 도구를 하나의 통합 인터페이스로 묶어 관리하는 게이트웨이가 유용합니다. API 게이트웨이가 마이크로서비스들 앞에서 라우팅하듯, MCP 게이트웨이는 여러 MCP 서버의 도구를 통합하고, 필터링하고, 관리합니다.
게이트웨이가 수행하는 핵심 기능:
- 도구 레지스트리: 모든 MCP 서버의 도구를 중앙에서 인벤토리 관리
- 동적 필터링: 패턴 1의 필터링 로직을 게이트웨이 레벨에서 적용
- 도구 이름 충돌 해결: 서로 다른 MCP 서버가 같은 이름의 도구를 제공할 때 네임스페이싱
- 헬스 체크: 비정상 MCP 서버의 도구를 자동으로 비활성화
- 사용량 추적: 어떤 도구가 얼마나 자주, 얼마나 성공적으로 사용되는지 모니터링
이 게이트웨이 패턴은 도구가 30개 이상인 하니스에서 특히 효과적입니다. 도구를 기능 단위의 MCP 서버로 분리하고, 게이트웨이에서 작업 맥락에 따라 활성 서버를 선택적으로 연결하면, 도구 과다 노출 문제를 구조적으로 해결할 수 있습니다.
주의할 점: MCP 서버 합성은 강력하지만, 과도한 분리는 오히려 관리 부담을 늘립니다. 하나의 MCP 서버에 3~7개의 관련 도구를 묶는 것이 적정 수준이며, 서버 수가 10개를 넘으면 게이트웨이의 복잡도가 도구 자체의 복잡도를 초과할 수 있습니다. 마이크로서비스와 마찬가지로 “마이크로”의 크기를 잘 잡는 것이 핵심입니다.
실전 코드: 동적 도구 필터링 레지스트리
패턴 1(동적 도구 필터링)을 실제로 구현한 코드입니다. 30~50줄 이내의 실행 가능한 Python 코드로, MCP 스타일의 도구 레지스트리와 컨텍스트 기반 필터링을 구현합니다.
"""동적 도구 필터링 레지스트리 — 패턴 1 구현 (실행 가능)"""
from dataclasses import dataclass, field
from typing import Any, Callable
import re
@dataclass
class ToolDef:
name: str
description: str # LLM이 읽는 유일한 근거
categories: list[str] # 카테고리 기반 필터링용
input_schema: dict[str, Any]
priority: int = 0 # 높을수록 우선 노출
class ToolRegistry:
def __init__(self, max_expose: int = 20) -> None:
self._tools: dict[str, ToolDef] = {}
self._max = max_expose # 한 번에 노출할 최대 도구 수
def register(self, tool: ToolDef) -> None:
self._tools[tool.name] = tool
def select(self, query: str, cats: list[str] | None = None) -> list[dict[str, Any]]:
"""쿼리 맥락에 맞는 도구만 골라 LLM-ready 스키마로 반환."""
pool = list(self._tools.values())
# 1단계 — 카테고리 필터 (없으면 전체)
if cats:
pool = [t for t in pool if set(t.categories) & set(cats)]
# 2단계 — 키워드 관련도 스코어링
scored: list[tuple[int, ToolDef]] = []
words = set(re.findall(r"\w+", query.lower()))
for t in pool:
s = t.priority
s += 10 * int(bool(words & set(t.name.lower().split("_"))))
s += sum(3 for w in words if w in t.description.lower())
scored.append((s, t))
scored.sort(key=lambda x: x[0], reverse=True)
# 3단계 — 상위 N개만 노출
return [
{"name": t.name, "description": t.description,
"input_schema": t.input_schema}
for _, t in scored[: self._max]
]
# ── 사용 예시 ──────────────────────────────
reg = ToolRegistry(max_expose=10)
reg.register(ToolDef("read_file",
"지정 경로의 파일을 UTF-8 텍스트로 반환합니다. "
"바이너리 파일은 지원하지 않습니다. 파일명 검색은 glob을 사용하세요.",
["filesystem", "read"],
{"type": "object", "properties": {"path": {"type": "string"}},
"required": ["path"]}, priority=5))
reg.register(ToolDef("glob",
"프로젝트에서 파일 경로 패턴(glob)으로 파일 목록을 반환합니다. "
"파일 내용 검색은 grep을 사용하세요.",
["filesystem", "search"],
{"type": "object", "properties": {"pattern": {"type": "string"}},
"required": ["pattern"]}, priority=4))
tools = reg.select("이 파일의 내용을 확인해줘", cats=["filesystem"])
for t in tools:
print(f" {t['name']}: {t['description'][:50]}...")이 코드의 핵심 설계 포인트:
max_expose: 한 번에 노출할 도구 수의 상한. 앞서 제시한 벤치마크에 근거하여 15~25로 설정합니다.- 카테고리 필터 → 키워드 스코어링 → 상한 자르기: 3단계 파이프라인으로 정밀도와 성능을 균형.
- 도구 설명에 유사 도구 경계를 명시:
read_file설명에 “파일명 검색은 glob을 사용하세요”를 포함하여 패턴 2도 적용. priority: 핵심 도구에 높은 우선순위를 부여하여 필터링 후에도 살아남도록 보장.
프로덕션에서는 여기에 임베딩 기반 의미적 유사도 계산(수준 2)이나 세션 이력 기반 가중치 조정(수준 3)을 추가하게 됩니다. 하지만 위 코드만으로도 도구 200개 환경에서 정확도를 43%에서 80% 이상으로 끌어올릴 수 있습니다.
1차 자료 읽기 — Anthropic의 MCP 설계 의도
한국어 자료에서 거의 다뤄지지 않은 Anthropic의 기술 설계 문서를 직접 살펴보겠습니다.
Anthropic이 MCP를 공개할 때 강조한 핵심 설계 원칙 중 하나는 “서버 제어(Server-Controlled) vs 모델 제어(Model-Controlled)”의 명확한 분리입니다. MCP 사양(specification)의 아키텍처 섹션에서 이를 이렇게 설명합니다:
“Tools are designed to be model-controlled, meaning that the AI model can automatically invoke them based on context and the user’s task… Resources, by contrast, are application-controlled — the host application decides which resources to include in the context.”
— MCP Specification, “Core Architecture” (2024)
이 분리가 왜 중요한지를 이해하려면, 도구(Tool)와 리소스(Resource)의 차이를 다시 생각해봐야 합니다.
도구(Tool)는 부작용(side effect)이 있습니다. 파일을 수정하고, 코드를 실행하고, API를 호출합니다. 따라서 모델이 “나 이걸 쓸 필요가 있다”고 판단했을 때만 호출되어야 합니다. 모델이 제어권을 가집니다.
리소스(Resource)는 읽기 전용입니다. 프로젝트의 파일 목록이나 데이터베이스 스키마처럼 컨텍스트에 포함될 “배경 정보”입니다. 이것은 하니스(애플리케이션)가 판단하여 컨텍스트에 넣어야 합니다. 4회에서 다룬 컨텍스트 엔지니어링의 영역이죠.
많은 초기 구현에서 이 구분을 무시하고, 리소스처럼 사용해야 할 것을 도구로 구현하는 실수를 저질렀습니다. 예를 들어, 프로젝트 구조를 보여주는 get_project_structure를 도구로 만들면, 모델이 매번 명시적으로 호출해야 합니다. 하지만 이것은 거의 모든 작업에서 필요한 배경 정보이므로, MCP의 리소스로 구현하여 하니스가 자동으로 컨텍스트에 포함시키는 것이 맞습니다.
Mitchell Hashimoto는 에이전트 하니스 프레임워크에서 이와 유사한 관점을 제시합니다. 그는 하니스의 구성요소를 센서(Sensors)와 이펙터(Effectors)로 구분하는데, MCP의 리소스-도구 구분과 정확히 대응합니다:
- 센서 = MCP 리소스: 외부 세계의 상태를 관찰하여 에이전트에게 정보 제공 (읽기 전용)
- 이펙터 = MCP 도구: 에이전트가 외부 세계에 작용을 가하는 수단 (부작용 있음)
이 개념적 정렬은 하니스 설계에 있어 중요한 시사점을 줍니다: 도구로 만들 것과 리소스로 만들 것을 처음부터 구분해야 한다는 것입니다. 도구 과다 노출 문제의 상당 부분은 리소스가 되어야 할 것들이 도구로 구현되어 발생합니다.
도구 vs 리소스 판별 체크리스트:
- 외부 상태를 변경하는가? → 도구(Tool)
- 항상 또는 대부분의 작업에서 필요한 배경 정보인가? → 리소스(Resource)
- 모델이 명시적으로 “요청”해야 의미가 있는가? → 도구(Tool)
- 컨텍스트에 미리 올려두면 모델 판단이 나아지는가? → 리소스(Resource)
Claude Code vs Cursor — 도구 인터페이스 관점의 차이
2회에서 Terminal-Bench 2.0의 16점 차이(Claude Code 93% vs Cursor 77%)를 확인했습니다. 이 차이를 도구 인터페이스 관점에서 분석하면 흥미로운 패턴이 보입니다.
Claude Code의 도구 전략:
- 도구 수: 약 20개 내외의 내장 도구 (Read, Edit, Write, Bash, Glob, Grep, Agent 등)
- 설명 품질: 각 도구에 상세한 사용 지침, 유사 도구 경계, 예시가 포함
- 동적 관리: 작업 흐름에 따라 도구 노출이 조절됨
- MCP 확장: 사용자가 필요한 MCP 서버를 선택적으로 연결
일반적인 IDE 확장형 하니스의 도구 전략:
- 도구 수: IDE 기능 + 확장 도구를 합하면 50~100개 이상
- 설명 품질: IDE 명령어를 기계적으로 도구화하여 설명이 간략한 경우 많음
- 정적 관리: 작업 맥락과 무관하게 전체 도구 세트가 상시 노출되는 경우 많음
이 전략 차이의 결과를 정리하면:
| 항목 | Claude Code | 일반 IDE 확장형 |
|---|---|---|
| 평균 노출 도구 수 | 15~20개 | 50~100+개 |
| 도구 정의 토큰 소비 | ~4,000 | ~15,000+ |
| 도구 선택 정확도 (추정) | 90%+ | 70~80% |
| 전체 토큰 효율 | 33K (기준 작업) | 188K (동일 작업) |
토큰 효율 5.5배 차이의 상당 부분이 도구 정의의 컨텍스트 소비량 차이에서 비롯됩니다. 매 API 호출마다 15,000 토큰의 도구 정의가 포함되면, 10회 호출이면 150,000 토큰이 도구 설명에만 쓰이는 셈입니다.
이것이 달러당 정확도 지표에서도 차이를 만듭니다. 2회에서 확인한 데이터를 다시 보면:
- 복잡 멀티파일 작업: Claude Code 달러당 8.5점 vs Cursor 6.2점
- 단순 유틸리티 작업: Cursor 달러당 42점 vs Claude Code 31점
복잡한 작업에서 Claude Code가 우세한 이유 중 하나가 바로 도구 정의의 토큰 효율성입니다. 복잡한 작업일수록 더 많은 턴이 필요하고, 매 턴마다 절약되는 도구 정의 토큰이 누적되어 더 많은 실제 작업 컨텍스트를 확보할 수 있기 때문입니다.
반면, 단순 작업에서 Cursor가 우세한 이유는 IDE 통합 도구의 즉시성입니다. IDE가 이미 열고 있는 파일, 커서 위치, 선택 영역 등을 도구 없이도 컨텍스트에 자동 포함하므로, 도구 호출 자체가 필요 없는 경우가 많습니다. 이것은 도구 인터페이스의 문제가 아니라, 도구가 필요 없는 영역에서의 장점입니다.
도구 인터페이스와 다른 컴포넌트의 상호작용
도구 인터페이스는 독립적으로 존재하지 않습니다. 하니스의 다른 컴포넌트와 긴밀하게 연결되며, 이 연결을 이해하는 것이 최적 설계의 열쇠입니다.
도구 × 컨텍스트 엔지니어링 (4회)
도구 정의는 컨텍스트의 일부입니다. 도구가 많아지면 그만큼 토큰 예산이 줄어들고, 이는 4회에서 다룬 컨텍스트 부패(Context Rot)를 가속합니다. 도구 필터링은 곧 컨텍스트 관리입니다.
또한 도구 실행 결과도 컨텍스트에 추가됩니다. 파일 내용을 읽는 도구가 10,000 토큰 분량의 파일을 반환하면, 그만큼 컨텍스트를 차지합니다. 좋은 하니스는 도구 결과도 요약·자르기·청킹하여 컨텍스트를 보호합니다.
도구 × 메모리 (6회 예정)
“이전에 이 도구를 어떻게 사용했는가”를 기억하는 것이 메모리의 역할입니다. 도구 사용 이력이 메모리에 저장되면, 다음 세션에서 같은 실수를 반복하지 않을 수 있습니다. 예를 들어, “지난번에 search_database로 시도했다가 실패한 후 query_raw_sql로 성공했다”는 기록이 있으면, 비슷한 작업에서 바로 올바른 도구를 선택할 수 있습니다.
도구 × 컨트롤 루프 (7회 예정)
도구 호출의 성공/실패가 에이전트 루프의 다음 단계를 결정합니다. 실패 시 재시도 전략, 대안 도구 탐색, 사용자에게 확인 요청 등은 모두 컨트롤 루프의 영역입니다. 도구 인터페이스가 명확한 에러 정보를 반환해야 컨트롤 루프가 올바른 판단을 내릴 수 있습니다.
도구 × 센서와 권한 (8회 예정)
MCP의 도구는 부작용이 있으므로 권한 게이트가 필수입니다. 파일을 읽는 것과 삭제하는 것은 위험도가 다릅니다. 하니스의 권한 시스템이 각 도구에 허용/거부/확인 요청 수준을 부여하고, 위험한 도구 호출 시 사용자 승인을 요구하는 것이 센서와 권한 컴포넌트의 역할입니다.
현장에서 바로 쓰는 도구 설계 원칙 7가지
지금까지의 논의를 현장 적용 가능한 원칙으로 정리합니다.
원칙 1: 도구는 적을수록 좋다 — 20개 룰
한 번에 모델에 노출하는 도구는 20개 이하를 목표로 합니다. 전체 도구 풀이 크더라도, 동적 필터링으로 실제 노출을 제한합니다.
원칙 2: 도구 설명은 프롬프트다
도구의 description을 작성할 때, “개발자가 읽을 API 문서”가 아니라 “LLM이 판단할 근거”라고 생각합니다. What·When·How·Output·Example 5요소를 포함하세요.
원칙 3: 유사 도구의 경계를 명시하라
기능이 비슷한 도구가 있으면, 각 도구의 설명에 “이 도구 대신 X를 사용해야 하는 경우”를 반드시 적습니다.
원칙 4: 도구와 리소스를 구분하라
상태를 변경하지 않는 읽기 전용 데이터는 MCP 리소스로 구현하여 하니스가 자동 관리하게 합니다. 도구 목록을 불필요하게 부풀리지 마세요.
원칙 5: 에러는 친절하게 반환하라
도구 실행 실패 시 스택 트레이스가 아니라, 모델이 다음 행동을 결정할 수 있는 구조화된 에러 메시지를 반환합니다. “파일을 찾을 수 없습니다. 경로를 확인하거나 glob 도구로 파일을 먼저 검색하세요.”처럼요.
원칙 6: 결과는 컨텍스트를 존중하라
도구가 10만 줄짜리 파일 전체를 반환하면 컨텍스트가 파괴됩니다. 결과의 최대 크기를 제한하고, 필요 시 페이지네이션이나 요약을 제공합니다.
원칙 7: 스키마는 엄격하게, 설명은 풍부하게
inputSchema의 타입, 필수 여부, enum 값은 가능한 한 엄격하게 정의합니다. 반면 description은 풍부하게 작성합니다. 이 조합이 모델의 정확한 도구 호출을 유도합니다.
내가 겪은 Harness 실패담 — 47개 도구의 지옥
음성·STT 파이프라인을 에이전트로 래핑하는 프로젝트에서 겪은 일입니다. 고객 상담 시나리오를 처리하는 음성 AI 어시스턴트를 만들고 있었는데, 욕심이 앞서 CRM, 주문 관리, 배송 추적, 환불 처리, FAQ 검색, 직원 호출 등 모든 백엔드 시스템의 API를 도구로 등록했습니다. 총 47개.
테스트할 때는 “주문 상태 확인해줘” 같은 명확한 요청에 잘 작동했습니다. 하지만 실제 고객 통화를 연결하자마자 모든 것이 무너졌습니다. “배송이 왜 이렇게 늦어요?”라는 질문에 track_shipment를 호출해야 하는데 search_faq를 호출하고, “환불해주세요”에 process_refund 대신 check_refund_policy를 호출하고… 도구 선택 정확도가 내부 테스트 92%에서 실전 64%까지 떨어졌습니다.
원인 분석을 해보니 두 가지였습니다. 첫째, STT의 인식 오류가 섞인 전사(transcription) 텍스트는 내부 테스트의 깔끔한 텍스트와 질적으로 달랐고, 이 노이즈가 도구 선택 스코어링을 교란했습니다. 둘째, 47개 도구의 스키마가 컨텍스트의 약 18,000 토큰을 차지하면서, 실제 대화 맥락에 쓸 수 있는 토큰이 부족해진 것입니다.
해결책은 인텐트(의도) 기반 도구 필터링이었습니다. STT 텍스트를 먼저 간단한 분류 모델에 통과시켜 주문문의, 배송문의, 환불요청, 일반문의 등의 카테고리로 분류하고, 해당 카테고리에 맞는 8~12개의 도구만 LLM에 노출했습니다. 도구 선택 정확도가 64%에서 91%로 회복됐고, 응답 지연도 4.2초에서 1.8초로 단축됐습니다. 도구 스키마 토큰도 18,000에서 3,500으로 줄어 대화 맥락에 여유가 생겼습니다.
이 경험이 교훈으로 남은 이유는, “도구가 많으면 더 유능하다”는 직관이 완전히 틀렸다는 것을 체감했기 때문입니다. 에이전트에게 47개 도구를 주는 것은 견습 요리사에게 200개의 조리기구를 한꺼번에 건네는 것과 같습니다. 지금 필요한 칼과 도마만 건네야 합니다.
도구 인터페이스 성숙도 체크리스트
당신의 하니스가 도구 인터페이스를 어느 수준으로 관리하고 있는지 자가 진단해보세요.
레벨 1 — 기초 (대부분의 프로토타입)
- 도구가 등록되어 있고 호출은 된다
- 도구 설명이 있긴 하다 (최소한의 한 줄)
- 모든 도구가 항상 모델에 노출된다
레벨 2 — 관리형
- 도구 설명에 5대 요소(What/When/How/Output/Example)가 포함
- 유사 도구 간 경계가 설명에 명시
- 스키마 검증으로 파라미터 오류를 즉시 감지
- 도구 실행 결과의 크기가 제한됨
레벨 3 — 최적화 (프로덕션 하니스)
- 동적 도구 필터링이 작동 (한 번에 20개 이하 노출)
- 도구와 리소스가 MCP 프리미티브로 명확히 분리
- 도구 사용 메트릭(호출 빈도, 성공률, 지연)을 수집
- MCP 서버가 기능 단위로 분리되어 선택적 로딩 가능
레벨 4 — 적응형 (최상위 하니스)
- 세션 이력 기반 도구 우선순위 자동 조정
- 실패 패턴 학습으로 대안 도구 자동 제안
- 도구 설명의 A/B 테스트와 지속적 개선
- 멀티 MCP 서버 간 게이트웨이 라우팅
88%의 AI 에이전트가 프로덕션에 도달하지 못하는 원인 중 상당수는 레벨 1에서 머물러 있기 때문입니다. CORE-Bench에서 최소 스캐폴드의 42% 성능과 전체 하니스의 78% 성능 사이의 36%포인트 차이 중, 도구 인터페이스 품질이 기여하는 비중은 적지 않습니다.
보너스: MCP 도구 설명 리팩토링 실습
마지막으로 실전 감각을 기르기 위해, 실제로 자주 보이는 나쁜 도구 설명을 좋은 설명으로 리팩토링하는 과정을 보여드리겠습니다.
리팩토링 전:
{
"name": "run_query",
"description": "Run a database query",
"inputSchema": {
"type": "object",
"properties": {
"q": {"type": "string"},
"db": {"type": "string"}
}
}
}문제점:
- 어떤 데이터베이스인지 불명확 (PostgreSQL? MySQL? SQLite?)
- 쿼리 형식 미명시 (SQL? NoSQL? ORM?)
- 파라미터 이름이 축약됨 (
q,db) required미지정- 결과 형태 미설명
- 위험한 쿼리(DROP, DELETE)의 처리 방식 미명시
리팩토링 후:
{
"name": "query_postgres",
"description": "PostgreSQL 데이터베이스에 읽기 전용(SELECT) SQL 쿼리를 실행합니다. "
"INSERT/UPDATE/DELETE/DROP 등 쓰기 쿼리는 거부됩니다. "
"결과는 최대 100행의 JSON 배열로 반환됩니다. "
"테이블 구조를 먼저 확인하려면 describe_table 도구를 사용하세요. "
"예: query_postgres(sql='SELECT id, name FROM users WHERE active = true', "
"database='app_production')",
"inputSchema": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "실행할 SELECT SQL 쿼리"
},
"database": {
"type": "string",
"description": "대상 데이터베이스 이름",
"enum": ["app_production", "app_staging", "analytics"]
}
},
"required": ["sql", "database"]
}
}개선 포인트:
- 이름:
run_query→query_postgres— 데이터베이스 종류가 이름에 명시 - 설명: 5대 요소 모두 포함 (What: SELECT 쿼리 실행 / When: 유사 도구 구분 / How: 파라미터 설명 / Output: 최대 100행 JSON / Example: 구체적 예시)
- 스키마: 파라미터 이름이 명확하고,
required지정,enum으로 허용 DB 목록 제한 - 안전 장치: 쓰기 쿼리 거부를 설명에 명시 — 모델이 위험한 쿼리를 시도하지 않도록 유도
이런 수준의 도구 설명이 모든 도구에 일관되게 적용되어야 합니다. 프로덕션 하니스에서 도구가 20개라면, 20개 모두 이 품질로 설명이 작성되어야 합니다. 하나의 빈약한 설명이 전체의 정확도를 끌어내립니다.
이번 글의 한 줄 요약
도구 인터페이스는 LLM에게 외부 세계를 만질 수 있는 손을 주는 것이며, 그 손의 정밀함은 도구의 수가 아니라 설명의 품질과 필터링 전략이 결정한다.
다음 회차 예고: 메모리 아키텍처 — 에이전트의 단기·장기 기억 설계
이번 회차에서 도구의 “사용 이력”이 다음 작업에 영향을 준다는 이야기를 했습니다. 6회에서는 이 기억 메커니즘을 본격적으로 다룹니다. 에이전트의 메모리 아키텍처 — 워킹 메모리, 세션 메모리, 장기 메모리의 3층 구조와, CLAUDE.md 같은 가이드 파일이 왜 “영속 메모리의 원시 형태”인지, 그리고 벡터 DB 기반 장기 기억이 에이전트를 어떻게 바꾸는지를 살펴봅니다.
OS 비유로 말하자면, 이번 회차가 “디바이스 드라이버”였다면, 다음 회차는 “가상 메모리와 파일시스템”입니다. CPU(LLM)의 레지스터(워킹 메모리)에 올라가지 않은 정보를 어떻게 효율적으로 스왑인/스왑아웃할 것인가 — 이것이 6회의 핵심 질문입니다.
다음 글에서 만나겠습니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 4화 (다음 차수는 아직 게시되지 않았습니다)
[…] AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 (총 12화 중 6화)◀ 이전 5화 (다음 차수는 아직 게시되지 않았습니다) 카테고리: IT기술 […]