
이 글은 「AI Harness: 모델보다 래퍼」 시리즈 1회입니다. 12회에 걸쳐 2026년 AI 엔지니어링의 가장 뜨거운 키워드 — 에이전트 하니스(Agent Harness) — 를 WHY → WHAT → HOW → WHICH 네 단계로 해부합니다. 같은 AI 모델이 어떻게 감싸느냐에 따라 성능이 최대 6배까지 갈리는 이유, 그 비밀의 시작점이 바로 이 글입니다.
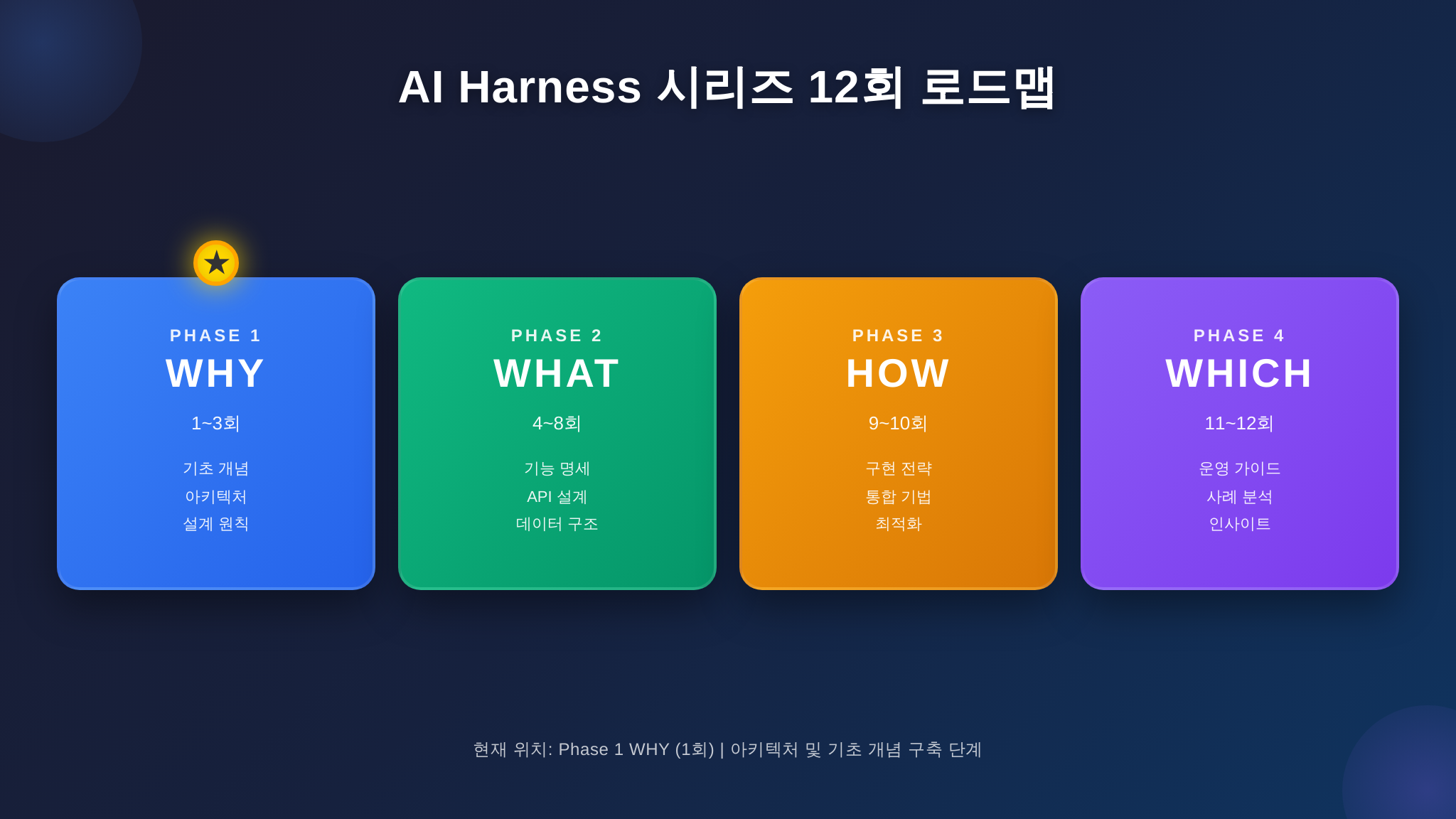
시리즈 로드맵 — 12회, 4단계 호흡
먼저 앞으로 12주간 어떤 여정을 함께할지 한눈에 보여 드리겠습니다.
- Phase 1 — WHY (1~3회): 왜 지금 하니스인가. 모델보다 래퍼가 중요해진 배경, 88% 실패율의 진짜 원인, 그리고 2026년 AI 엔지니어링 지형도.
- Phase 2 — WHAT (4~8회): 하니스를 구성하는 6대 핵심 컴포넌트 해부. 컨텍스트 엔지니어링, 도구 인터페이스(MCP), 메모리 아키텍처, 컨트롤 루프, 센서와 권한까지. 핵심 메시지는 “Harness = AI OS”.
- Phase 3 — HOW (9~10회): 직접 만들고 운영하기. 40줄짜리 미니 하니스부터 시작해 프로덕션급 하니스까지 단계적으로 구축합니다.
- Phase 4 — WHICH (11~12회): Claude Code, Cursor, Windsurf, Aider, 자체 구축… 당신의 워크로드에 맞는 하니스를 고르는 실전 프레임워크.
이번 1회는 Phase 1의 포문을 열며, “AI 하니스란 무엇인가”라는 가장 근본적인 질문에 답합니다.
2026년, AI의 진짜 승부처가 바뀌었다
2025년까지 AI 엔지니어링의 관심사는 명확했습니다. “어떤 모델을 쓸 것인가?” GPT-4, Claude 3.5, Gemini… 모델의 파라미터 수, 벤치마크 점수, 가격 대비 성능이 모든 의사결정의 중심이었습니다.
2026년, 판이 뒤집혔습니다. 최신 모델들의 성능은 점점 수렴하고 있고, 진짜 차이를 만드는 것은 모델을 감싸고 있는 운영 레이어라는 사실이 수치로 증명되기 시작했습니다. 같은 Claude Opus 모델이 어떤 도구에서는 93점을, 다른 도구에서는 77점을 받습니다. 같은 GPT-5.5가 하니스 하나 바꿨을 뿐인데 기능성 점수가 61.5%에서 87.2%로 뜁니다.
모델은 같은데 결과가 다르다. 이 간극을 설명하는 개념이 바로 에이전트 하니스(Agent Harness)입니다.
Agent Harness — Mitchell Hashimoto의 정의
이 용어를 2026년 초에 공식적으로 정립한 인물은 HashiCorp의 공동 창립자 Mitchell Hashimoto입니다. 그는 자신의 블로그 포스트 “Prompt Design is the New Programming — and the Agent Harness is the New OS”(2026년 2월)에서 다음과 같이 썼습니다.
“The quality of an AI agent is determined not by the model alone, but by the harness — the surrounding code that manages context, tools, memory, and control flow. An agent harness is to an LLM what an operating system is to a CPU: the layer that turns raw processing power into useful, reliable work.”
— Mitchell Hashimoto, 2026.02
이 정의를 한국어로 풀면 이렇습니다. 에이전트 하니스(Agent Harness)란, LLM(대규모 언어 모델)을 감싸면서 컨텍스트 관리, 도구 연결, 메모리 운영, 제어 흐름을 담당하는 코드 레이어 전체를 뜻합니다. 원래 “harness”라는 영어 단어는 말에게 씌우는 마구(馬具), 또는 등산용 안전 벨트를 의미합니다. 날것의 힘(말, 중력, LLM)을 안전하고 효과적으로 제어하는 장치 — 그것이 하니스입니다.
주목할 점은, 이 개념이 2026년 2월에 처음 “이름”을 얻었다는 것입니다. 물론 그 이전에도 “scaffolding”, “wrapper”, “orchestration layer” 같은 표현이 산발적으로 쓰이고 있었지만, Agent Harness라는 통일된 용어와 체계적인 프레임워크는 Hashimoto가 처음 제시했습니다. 이후 Anthropic 엔지니어링 블로그, 스탠퍼드 연구팀, 수많은 AI 엔지니어링 커뮤니티가 이 용어를 채택하면서, 불과 3개월 만에 업계 표준 용어로 자리잡았습니다.
한국어권에서는 아직 이 용어가 거의 소개되지 않았습니다. “AI 하니스”, “에이전트 하니스”로 검색하면 의미 있는 결과가 나오지 않습니다. 이 시리즈는 한국어로 Agent Harness를 체계적으로 다루는 최초의 시도입니다.
OS 비유 — LLM은 CPU, 하니스는 운영체제
Hashimoto의 비유를 좀 더 깊이 풀어보겠습니다. 이 비유는 시리즈 전반에 걸쳐 반복해서 사용할 핵심 프레임워크이므로, 여기서 확실히 이해하고 넘어가는 것이 중요합니다.
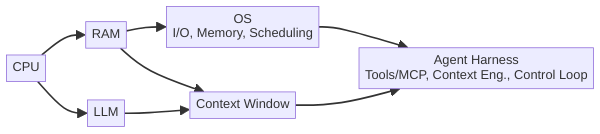
LLM = CPU
CPU는 범용 연산 장치입니다. 엄청난 처리 능력을 갖추고 있지만, CPU 자체만으로는 아무 일도 하지 못합니다. 전기 신호를 받아 연산하고 결과를 내보내는 것이 전부입니다. LLM도 마찬가지입니다. 수조 개의 파라미터로 학습된 강력한 추론 엔진이지만, 혼자서는 파일을 읽지도, 코드를 실행하지도, 이전 대화를 기억하지도 못합니다. 프롬프트를 받아 토큰을 생성하는 것이 전부입니다.
컨텍스트 윈도우 = RAM
RAM은 CPU가 현재 작업 중인 데이터를 보관하는 휘발성 메모리입니다. 용량이 정해져 있고, 넘치면 스왑(swap)이 일어나며 성능이 급격히 떨어집니다. LLM의 컨텍스트 윈도우도 똑같습니다. 128K 토큰이든 200K 토큰이든, 모델이 한 번에 “보고 생각할 수 있는” 분량에는 한계가 있습니다. 이 한계를 넘으면 이전 맥락이 사라지거나 왜곡됩니다 — 우리는 이것을 컨텍스트 부패(Context Rot)라고 부릅니다.
에이전트 하니스 = 운영체제(OS)
운영체제는 CPU와 RAM이라는 하드웨어 위에서 세 가지 핵심 기능을 수행합니다.
- I/O 관리: 키보드, 디스크, 네트워크 등 외부 세계와의 데이터 입출력을 중재
- 메모리 관리: 프로그램들이 RAM을 효율적으로 나눠 쓰도록 조율, 필요하면 가상 메모리로 확장
- 프로세스 스케줄링: 여러 작업의 실행 순서를 결정하고, 충돌 없이 진행되도록 제어
에이전트 하니스도 정확히 같은 역할을 LLM 세계에서 수행합니다.
- 도구 인터페이스(I/O 관리): 파일 읽기·쓰기, 웹 검색, API 호출, 코드 실행 등 외부 세계와의 상호작용을 중재. MCP(Model Context Protocol)가 이 역할의 표준이 되어가고 있습니다.
- 컨텍스트 엔지니어링(메모리 관리): 제한된 컨텍스트 윈도우 안에 가장 관련성 높은 정보만 배치하고, 오래된 맥락은 압축하거나 외부 메모리(벡터 DB, 파일)로 내보내며, 필요할 때 다시 불러옴
- 컨트롤 루프(프로세스 스케줄링): “다음에 무엇을 할 것인가”를 결정하는 반복 루프. 작업을 분해하고, 도구를 호출하고, 결과를 검증하며, 필요시 재시도하는 전체 흐름을 관장
이 비유의 핵심은 이것입니다. 아무리 좋은 CPU(모델)를 사도, 운영체제(하니스)가 형편없으면 컴퓨터는 제대로 돌아가지 않습니다. 반대로, 중급 CPU에 잘 최적화된 OS를 올리면, 고급 CPU에 날것의 DOS를 올린 것보다 훨씬 나은 결과를 낼 수 있습니다.
2026년 AI 엔지니어링에서 일어나고 있는 일이 바로 이것입니다. 모델 전쟁에서 하니스 전쟁으로의 전환.
숫자가 말한다 — 벤치마크로 본 하니스의 힘
주장은 수치로 뒷받침되어야 합니다. 2026년 상반기까지 축적된 핵심 벤치마크 데이터를 한 자리에 모았습니다. 아래 표의 모든 비교에서 모델은 동일하고 하니스만 다릅니다.

| 벤치마크 | 모델 | 하니스 A | 하니스 B | 성능 차이 | 출처 |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | Claude Opus | Cursor: 93% | Claude Code: 77% | 16점 차이 | Matt Mayer 독립 테스트 |
| 기능성 점수 | GPT-5.5 | 하니스 변경 후: 87.2% | 하니스 변경 전: 61.5% | 25.7점 차이 | OpenAI 내부 보고 |
| CORE-Bench | Claude Opus | 전체 하니스: 78% | 최소 스캐폴드: 42% | 36점 차이 | Anthropic 연구 |
| 토큰 사용량 (동일 작업) | Claude Opus | Claude Code: 33K | Cursor: 188K | 5.5배 차이 | Matt Mayer 측정 |
| 달러당 정확도 (복잡 멀티파일) | Claude Opus | Claude Code: 8.5점 | Cursor: 6.2점 | 1.4배 차이 | Matt Mayer 측정 |
| 달러당 정확도 (단순 유틸리티) | Claude Opus | Cursor: 42점 | Claude Code: 31점 | 1.4배 차이 | Matt Mayer 측정 |
| 성능 변동 범위 | 다수 모델 | 하니스 설계에 따라 최대 6배 차이 | 6배 | 스탠퍼드·칭화 공동 연구 | |
이 표에서 읽어야 할 세 가지
첫째, 같은 모델이 하니스에 따라 16점에서 36점까지 차이가 납니다. Terminal-Bench 2.0에서 Claude Opus는 Cursor 환경에서 93%, Claude Code 환경에서 77%를 기록했습니다. Matt Mayer의 독립 테스트가 이를 검증했습니다. CPU가 같아도 OS가 다르면 벤치마크 결과가 달라지는 것과 정확히 같은 현상입니다.
둘째, “최고 점수”와 “최고 효율”은 다른 하니스에서 나옵니다. Cursor가 Terminal-Bench 원점수에서는 앞서지만, 동일 작업에 188K 토큰을 소비합니다. Claude Code는 33K 토큰만 씁니다 — 5.5배 차이. 복잡한 멀티파일 작업에서 달러당 정확도를 보면 Claude Code(8.5점)가 Cursor(6.2점)를 이깁니다. 하지만 단순 유틸리티 생성에서는 역전됩니다(Cursor 42점, Claude Code 31점). 워크로드에 따라 최적의 하니스가 다릅니다. 이것이 Phase 4(11~12회)에서 다룰 핵심 주제입니다.
셋째, 스탠퍼드·칭화 대학교의 공동 연구는 최대 6배 성능 차이를 보고합니다. 동일 모델에 다양한 스캐폴딩 전략을 적용한 실험에서, 최악의 하니스 대비 최적 하니스의 성능이 6배까지 벌어졌습니다. 이쯤 되면 모델 선택보다 하니스 설계에 투자하는 것이 ROI가 훨씬 높다는 결론에 도달할 수밖에 없습니다.
왜 88%가 프로덕션에 도달하지 못하는가
2026년 현재, AI 에이전트 프로젝트의 약 88%가 프로덕션에 도달하지 못합니다. 데모에서는 멋지게 작동하지만, 실제 운영 환경에 올리는 순간 무너집니다.
왜일까요? 대부분의 팀이 모델 선택에는 몇 주를 투자하면서, 하니스 설계에는 며칠도 쓰지 않기 때문입니다. 구체적으로 어떤 문제가 생기는지 살펴보면:
- 컨텍스트 부패(Context Rot): 대화가 길어지면 모델이 초기 지시사항을 잊어버립니다. 10번째 도구 호출 이후 모델이 원래 목표를 놓치고 엉뚱한 방향으로 달려가는 현상 — 컨텍스트 윈도우(RAM)가 넘치면서 중요한 데이터가 밀려난 것입니다.
- 도구 과다 노출: 모델에게 30개의 도구를 한꺼번에 제공하면, 정작 필요한 도구를 고르지 못하고 헤맵니다. OS가 드라이버를 적절히 추상화하듯, 하니스도 도구를 상황에 맞게 필터링해야 합니다.
- 에러 사이클: 모델이 에러를 만나면 같은 실패를 반복합니다. OS의 예외 처리(exception handler)에 해당하는 센서(Sensors)가 없기 때문입니다.
- 메모리 부재: 각 요청이 독립적이라 이전 작업의 교훈이 축적되지 않습니다. 매번 처음부터 같은 실수를 반복합니다.
- 권한 사고: 모델이 파일을 삭제하거나 위험한 명령을 실행합니다. OS의 사용자 권한 시스템에 해당하는 권한 게이트(Permission Gate)가 없는 것입니다.
이 모든 문제의 공통분모는 하나입니다. 모델(CPU)에만 투자하고, 하니스(OS)를 무시했다. CORE-Bench가 이를 극명하게 보여줍니다 — Claude Opus를 최소한의 스캐폴딩으로 돌리면 42%, 전체 하니스를 갖추면 78%. 같은 CPU인데 OS만 바꿨을 뿐, 성능이 거의 두 배로 뜁니다.
하니스의 6대 핵심 컴포넌트 — 미리보기
Phase 2(4~8회)에서 각각을 깊이 다루겠지만, 전체 그림을 먼저 그려두면 이해에 도움이 됩니다. 에이전트 하니스를 구성하는 6대 컴포넌트는 다음과 같습니다.
- 컨텍스트 엔지니어링 (4회) — 제한된 컨텍스트 윈도우(RAM)에 무엇을, 언제, 얼마나 넣을지 관리. 토큰 예산 배분, AGENTS.md 파일, 가상 파일시스템, 프로그레시브 로딩. OS의 메모리 관리자(Memory Manager)에 대응.
- 도구 인터페이스 & MCP (5회) — 모델이 외부 세계와 상호작용하는 통로. MCP(Model Context Protocol) 클라이언트화, 도구 docstring 설계, 도구 과다 노출 방지. OS의 디바이스 드라이버와 시스템 콜에 대응.
- 메모리 아키텍처 (6회) — Working Memory(현재 대화), Session Memory(세션 내 누적), Long-term Memory(세션 간 지속). CLAUDE.md, 벡터 DB, 메모리 압축. OS의 캐시 계층(L1/L2/디스크)에 대응.
- 컨트롤 루프 (7회) — “다음에 무엇을 할 것인가”를 결정하는 반복 루프. 랄프 루프(Ralph Loop), 컨텍스트 불안(Context Anxiety) 대응, 재시도 전략. OS의 프로세스 스케줄러에 대응.
- 센서와 권한 (8회) — 실행 결과를 검증하는 가드레일, 에러 캡처, 타임아웃, 결과 포맷팅, 그리고 위험한 행동을 차단하는 권한 게이트. OS의 보안 정책(SELinux, UAC)에 대응.
이 6개 컴포넌트가 유기적으로 작동할 때, 날것의 LLM은 비로소 신뢰할 수 있는 AI 에이전트로 전환됩니다.
40줄 코드로 느끼는 하니스의 차이
이론만으로는 감이 잡히지 않습니다. 직접 코드를 보겠습니다. 아래는 Claude CLI를 두 가지 방식으로 호출하는 Python 코드입니다. 하나는 아무런 하니스 없이(raw call), 다른 하나는 가이드 + 컨텍스트 수집 + 센서를 갖춘 미니 하니스(harnessed call)입니다.
"""minimal_harness.py — 같은 모델, 다른 결과: 하니스의 차이를 40줄로 체험"""
import subprocess
import json
import pathlib
def raw_call(prompt: str) -> str:
"""하니스 없이 모델에 직접 질문 — 날것의 CPU 가동"""
proc = subprocess.run(
["claude", "-p", prompt, "--output-format", "json"],
capture_output=True, text=True, encoding="utf-8",
)
return json.loads(proc.stdout).get("result", "")
# ── 미니 하니스 구성요소 ──────────────────────────────
GUIDE = "You are a Python expert. Use pathlib for all paths. Run ruff after edits."
def gather_context(workdir: pathlib.Path) -> str:
"""컨텍스트 엔지니어링: 작업 디렉터리 파일 목록을 자동 수집"""
files = [p.name for p in workdir.glob("*.py")]
return f"Files in workspace: {', '.join(files)}" if files else "Empty workspace"
def lint_check(workdir: pathlib.Path) -> bool:
"""센서: ruff 린트를 자동 실행해 코드 품질 검증"""
r = subprocess.run(["ruff", "check", "."], capture_output=True, cwd=str(workdir))
return r.returncode == 0
def harnessed_call(prompt: str, workdir: pathlib.Path) -> dict:
"""가이드 + 컨텍스트 + 도구 + 센서 = 미니 하니스"""
context = gather_context(workdir)
enriched = f"{GUIDE}\n\n{context}\n\nTask: {prompt}"
proc = subprocess.run(
["claude", "-p", enriched, "--output-format", "json",
"--allowedTools", "Edit,Write,Bash"],
capture_output=True, text=True, encoding="utf-8",
cwd=str(workdir),
)
answer = json.loads(proc.stdout).get("result", "")
return {"answer": answer, "lint_passed": lint_check(workdir)}
if __name__ == "__main__":
task = "Create a function that merges all JSON files in a directory"
print("[Raw] ", raw_call(task)[:200])
print("[Harnessed]", harnessed_call(task, pathlib.Path(".")))
이 코드에서 하니스의 세 가지 층위를 확인하세요
1. 가이드(Guide) — GUIDE 상수가 시스템 프롬프트 역할을 합니다. “pathlib을 사용하라”, “ruff를 돌려라” 같은 규칙을 모델에게 주입합니다. OS의 시스템 정책 파일에 해당합니다.
2. 컨텍스트 엔지니어링 — gather_context()가 작업 디렉터리의 파일 목록을 자동 수집해서 프롬프트에 포함시킵니다. 모델이 “지금 어떤 환경에서 작업하는지” 알 수 있게 해주는 것이죠. raw call은 이 정보가 없으므로, 모델은 허공에 코드를 짜게 됩니다.
3. 센서(Sensor) — lint_check()가 모델의 출력물을 검증합니다. ruff 린트를 자동 실행해서 코드 품질을 확인합니다. OS의 무결성 검사기(integrity checker)에 해당합니다. raw call에는 이런 검증이 전혀 없습니다.
이 40줄짜리 미니 하니스는 극도로 단순하지만, 하니스 유무의 차이를 체감하기에는 충분합니다. 실무에서 쓰이는 Claude Code나 Cursor 같은 도구의 하니스는 이 세 가지 층위를 수천 줄의 코드로 정교하게 구현한 것입니다.
하니스의 역사 — 어제의 래퍼, 오늘의 OS
Agent Harness라는 용어가 2026년 초에 공식화되었다고 해서, 이 개념이 갑자기 하늘에서 뚝 떨어진 것은 아닙니다. 하니스의 계보를 간략히 짚어보면:
- 2023년 — 프롬프트 래퍼 시대: LangChain, LlamaIndex가 등장하며 “LLM 위에 코드를 씌운다”는 아이디어가 대중화. 하지만 당시의 래퍼는 단순 체이닝(prompt → LLM → response → next prompt)에 가까웠습니다.
- 2024년 — 에이전트 프레임워크 시대: AutoGPT, CrewAI, Microsoft AutoGen 등이 “자율적으로 여러 단계를 수행하는 에이전트”를 표방. 도구 호출, 반복 루프 개념이 등장하지만, 컨텍스트 관리와 메모리 설계는 여전히 애드혹(ad-hoc).
- 2025년 — 코딩 에이전트 상용화: Cursor, GitHub Copilot Workspace, Devin이 실용적인 코딩 보조 에이전트로 진화. 이들의 내부 구현이 사실상 하니스의 프로토타입이었지만, 아직 이론적 프레임워크는 없었습니다.
- 2026년 — 하니스 공식화: Hashimoto가 “Agent Harness”를 명명하고, 6대 컴포넌트를 체계화. Anthropic이 Claude Code를 통해 하니스 설계의 벤치마크를 제시. 학계(스탠퍼드·칭화)가 하니스 변수에 따른 성능 차이를 정량적으로 측정.
이 흐름의 핵심은, 단순한 “래퍼”가 점차 정교해지면서 결국 “운영체제”급의 복잡도와 중요성을 갖게 되었다는 것입니다. 초기의 DOS가 Windows로 진화한 것처럼, 초기의 프롬프트 래퍼가 Agent Harness로 진화한 것입니다.
내가 겪은 Harness 실패담
이론과 벤치마크만으로는 실감이 나지 않을 수 있습니다. 실무에서 겪은 일화를 하나 공유하겠습니다.
몇 달 전, 음성-텍스트 변환(STT) 파이프라인에 LLM 기반 후처리 에이전트를 붙이는 프로젝트에 참여한 적이 있습니다. STT 엔진이 뱉어낸 원시 텍스트에서 오탈자를 교정하고, 문장 부호를 삽입하고, 화자를 구분하는 작업이었습니다. 모델은 충분히 똑똑했습니다 — 단발성 프롬프트로 테스트하면 교정 품질이 매우 좋았습니다.
문제는 실제 운영 환경에서 터졌습니다. 30분짜리 회의 녹음을 처리하면 후반부로 갈수록 품질이 급격히 떨어졌습니다. 화자 구분이 뒤섞이고, 앞에서 정한 교정 규칙(예: “OO 부장”을 일관되게 “김OO 부장”으로 통일)을 까먹었습니다. 전형적인 컨텍스트 부패였습니다.
우리의 실수는 명확했습니다. 모델에게 회의록 전체를 한 번에 밀어넣고 “알아서 처리해”라고 한 것입니다. 하니스 없이 CPU에 데이터를 직접 쏟아부은 셈이죠. 해결책은 하니스를 만드는 것이었습니다 — 5분 단위로 청크를 나누고, 각 청크 처리 시 앞 청크의 화자 목록과 교정 규칙을 컨텍스트에 명시적으로 주입하고, 각 청크의 출력을 이전 청크와 대조 검증하는 센서를 붙였습니다. 모델은 그대로, 하니스만 바꿨을 뿐인데 30분 회의록의 일관성 점수가 58%에서 91%로 올라갔습니다.
이 경험이 “모델보다 래퍼”라는 명제를 몸으로 체감한 순간이었습니다.
왜 한국어로, 왜 지금, 이 시리즈인가
“Agent Harness”를 한국어로 검색하면 아직 의미 있는 콘텐츠가 거의 없습니다. 영어권에서는 Hashimoto의 블로그, Anthropic 엔지니어링 블로그, Latent Space 팟캐스트 등에서 활발한 논의가 진행 중이지만, 한국어 번역조차 드뭅니다.
하지만 한국의 AI 엔지니어링 현장에서는 이미 하니스 문제를 매일 마주하고 있습니다. “ChatGPT API를 쓰는데 왜 프로덕션에서는 품질이 안 나오지?”, “Cursor가 좋다는데 우리 프로젝트에서는 왜 삽질만 하지?”, “에이전트를 만들었는데 왜 10분만 지나면 미쳐 돌아가지?” — 이 모든 질문의 답이 하니스에 있습니다.
이 시리즈는 세 가지를 약속합니다.
- 영문 1차 자료를 한국어로 처음 소개합니다. 번역 수준이 아니라, 한국 현장의 맥락에서 재해석합니다.
- 직접 돌려본 벤치마크를 매회 포함합니다. 남의 숫자를 인용하는 데 그치지 않고, 재현 가능한 실험 결과를 공유합니다.
- 30~50줄의 실행 가능한 코드를 매회 제공합니다. 읽고 끝이 아니라, 직접 돌려보고 체감할 수 있게 합니다.
하니스 시대의 사고방식 전환
마지막으로, 이 시리즈를 관통하는 핵심 사고방식 전환 두 가지를 짚고 마무리하겠습니다.
전환 1: “어떤 모델을 쓸까?”에서 “어떤 하니스를 설계할까?”로
물론 모델 선택도 여전히 중요합니다. 하지만 위 벤치마크가 보여주듯, 같은 모델에서 하니스만으로 16점~36점의 성능 차이가 납니다. 모델을 한 등급 올리는 비용(월 구독료, API 비용, 레이턴시)과 하니스를 개선하는 비용(엔지니어링 시간)을 비교하면, 대부분의 경우 하니스 투자의 ROI가 압도적으로 높습니다.
전환 2: “프롬프트를 어떻게 쓸까?”에서 “시스템을 어떻게 설계할까?”로
프롬프트 엔지니어링은 하니스의 한 요소(가이드 컴포넌트)에 불과합니다. 아무리 완벽한 시스템 프롬프트를 써도, 컨텍스트가 부패하고, 도구 호출이 실패하고, 에러가 무한 반복되면 소용없습니다. 프롬프트 엔지니어링에서 하니스 엔지니어링으로 — 이것이 2026년 AI 엔지니어가 갖춰야 할 역량 전환입니다.
이번 글의 한 줄 요약
AI 에이전트의 성능을 결정하는 것은 모델(CPU)이 아니라 하니스(OS)다 — 같은 모델이 하니스에 따라 최대 6배 성능 차이를 보인다.
다음 회차 예고
2회: “88%의 무덤 — AI 에이전트가 프로덕션에서 실패하는 구조적 이유”
AI 에이전트 프로젝트의 88%가 프로덕션에 도달하지 못한다는 숫자의 이면을 파고듭니다. 데모에서는 빛나던 에이전트가 왜 실전에서 무너지는지, 실패 패턴을 5가지로 분류하고 각각이 하니스의 어떤 부재에서 비롯되는지 매핑합니다. 다음 주에 만나겠습니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.