이 글은 AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 시리즈의 7/12화입니다. 지난 6화에서 에이전트의 기억을 Working·Session·Long-term 세 계층으로 쪼개는 메모리 아키텍처를 다뤘습니다. 오늘은 그 기억을 실제로 활용하며 쉬지 않고 돌아가는 심장 — 컨트롤 루프(Control Loop)를 해부합니다.
4화에서 컨텍스트 엔지니어링(RAM 관리), 5화에서 도구 인터페이스(I/O 드라이버), 6화에서 메모리 아키텍처(스토리지)를 다뤘으니, 이제 이 모든 것을 하나로 묶어 “언제 실행하고, 언제 반성하고, 언제 멈출 것인가”를 결정하는 스케줄러를 만날 차례입니다. 컨트롤 루프가 없는 에이전트는 CPU가 있지만 OS가 없는 컴퓨터 — 전원은 켜져 있어도 아무 일도 제대로 끝나지 않습니다.
에이전트의 심장박동 — 컨트롤 루프란 무엇인가
운영체제의 스케줄러를 떠올려 보세요
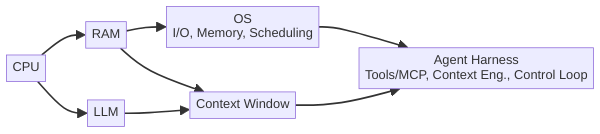
시리즈 내내 쓰고 있는 비유를 되새겨 봅시다. LLM은 CPU, 컨텍스트 윈도우는 RAM, 에이전트 하니스(Agent Harness)는 OS입니다. 그렇다면 컨트롤 루프는 OS의 어떤 부분에 해당할까요? 바로 커널 스케줄러(Kernel Scheduler)입니다.
운영체제의 커널 스케줄러가 하는 일을 떠올려 보면, 그 구조가 놀랍도록 에이전트 컨트롤 루프와 닮아 있습니다:
- 인터럽트 확인 — 새로운 이벤트(사용자 입력, 타이머, 하드웨어 신호)가 있는지 검사
- 프로세스 스케줄링 — 어떤 작업에 CPU 시간을 줄지 결정
- 메모리 관리 — 페이지 폴트 처리, 스와핑, 가비지 컬렉션
- 에러 핸들링 — 세그폴트, 데드락 감지, 프로세스 재시작
- 제어 반환 — 선택된 프로세스에 CPU를 넘겨줌
에이전트 컨트롤 루프도 정확히 같은 다섯 가지를 수행합니다:
- 상태 확인 — 현재 작업이 어디까지 진행됐는지, 새로운 정보가 들어왔는지 검사
- 행동 결정 — 다음에 어떤 도구를 호출할지, 어떤 방향으로 진행할지 판단
- 컨텍스트 관리 — 토큰 예산 확인, 필요하면 압축·요약·정리
- 에러 복구 — 도구 실패, 예상 밖 결과, 시간 초과 대응
- 모델 호출 — LLM(CPU)에 다음 추론을 맡기고 결과를 받아옴
이 다섯 단계를 한 번이 아니라 반복적으로 수행하기 때문에 “루프”라고 부릅니다. 한 번의 API 호출로 끝나는 건 챗봇이지, 에이전트가 아닙니다.
가장 단순한 에이전트 루프(Agent Loop)
에이전트 루프의 기본 형태는 Anthropic의 엔지니어링 블로그 “Building Effective Agents”(2024)에서 명확하게 정의한 바 있습니다:
“Agents begin their work with either a command from, or interactive discussion with, the human user. Once the task is clear, agents plan and operate independently, potentially returning to the human for further information or judgement. During execution, it’s important for the agent to gain ‘ground truth’ from the environment at each step.”
— Anthropic, Building Effective Agents, December 2024
이 정의를 코드 구조로 바꾸면 다음과 같습니다:
while not done:
plan = model.think(task, context) # 모델에 다음 행동 질의
result = tools.execute(plan.actions) # 도구 실행
context.append(result) # 결과를 컨텍스트에 추가
done = plan.is_complete # 완료 여부 판단
return plan.final_answer4줄. 이것이 모든 에이전트 시스템의 골격입니다. Claude Code, Cursor, Devin, OpenAI Codex — 겉모습은 달라도 내부에는 이 루프가 돌고 있습니다. 차이는 이 루프 주변에 어떤 안전장치, 반성 메커니즘, 복구 전략을 붙이느냐에서 생깁니다.
그런데 이 4줄짜리 루프를 그대로 프로덕션에 올리면 어떻게 될까요?
“루프가 없는 에이전트”가 부서지는 세 가지 방식
Phase 2의 다른 회차들처럼, 이 컴포넌트가 없거나 잘못됐을 때 실제로 무엇이 깨지는지부터 봅시다. 컨트롤 루프 설계의 결함은 세 가지 전형적 증상으로 나타납니다.
증상 1: 끝나지 않는 에이전트 — 무한 루프
가장 흔하고, 가장 비용이 큰 실패입니다. 에이전트가 “완료”를 선언하지 못한 채 같은 작업을 반복하거나, 서로 모순되는 행동을 번갈아 수행하며 토큰을 소진합니다.
실제로 이런 일이 벌어집니다:
- 파일 A를 수정 → 테스트 실패 → 파일 B를 수정 → 다른 테스트 실패 → 파일 A를 원래대로 되돌림 → 최초 테스트 다시 실패 → … (무한 순환)
- 에이전트가 “이 파일을 읽어야 합니다”라고 말하며 같은 파일을 30번 연속 읽음
- 도구 호출 결과에 에러가 포함됐지만, 에러를 인식하지 못하고 동일 호출 반복
이 증상의 근본 원인은 종료 조건(termination condition)의 부재 또는 불완전함입니다. 앞서 본 4줄 루프에서 done = plan.is_complete이라고 썼지만, “complete”의 정의를 모델에게만 맡기면 모델은 영원히 “조금 더 해보겠습니다”라고 대답할 수 있습니다.
비용 관점에서 보면 이 증상은 치명적입니다. 무한 루프에 빠진 에이전트는 컨텍스트 윈도우가 가득 찰 때까지 — 또는 API 요금이 폭발할 때까지 — 멈추지 않습니다. Claude Code에서 동일 작업에 33K 토큰을 쓰는 것과 Cursor에서 188K 토큰(5.5배)을 쓰는 것의 차이가 바로 여기서 시작됩니다. 루프를 얼마나 빨리, 얼마나 정확하게 멈추느냐가 토큰 효율성을 좌우합니다.
증상 2: 한 번의 실패에 전체가 멈춤 — 프래자일 루프
무한 루프의 정반대 증상입니다. 도구 하나가 에러를 반환하면 에이전트 전체가 Exception을 올리고 죽어 버립니다. 사용자는 “Internal Server Error”를 받고, 진행 중이던 모든 작업이 날아갑니다.
이 증상이 특히 위험한 이유는 에이전트가 아닌 도구가 문제인 경우가 대부분이기 때문입니다:
- 네트워크 일시 중단으로 MCP 서버 호출 실패
- 파일 시스템 권한 문제로 파일 쓰기 실패
- 외부 API의 레이트 리밋 초과
- 도구의 JSON 파싱 에러 (도구가 예상과 다른 형식을 반환)
이런 일시적 오류에 에이전트가 즉사하면, 88%의 에이전트가 프로덕션에 도달하지 못하는 현실의 한 축을 설명할 수 있습니다. 프로토타입에서는 모든 게 잘 되지만, 실제 환경은 네트워크 지터, 파일 락, 서드파티 장애가 상수입니다.
증상 3: 컨텍스트 절벽(Context Cliff) — 조용한 성능 붕괴
이 증상은 가장 교활합니다. 에이전트가 루프를 돌면서 컨텍스트 윈도우(RAM)에 결과를 계속 쌓다 보면, 어느 순간 성능이 절벽처럼 떨어집니다. 에러가 나지 않기 때문에 로그에는 정상으로 보이지만, 출력 품질이 급격히 나빠집니다.
4화에서 다뤘던 컨텍스트 부패(Context Rot)와 직접 연결되는 현상입니다. 루프의 각 반복이 컨텍스트에 수백~수천 토큰을 추가하므로, 10회 반복이면 수만 토큰이 쌓입니다. 이때:
- 초기에 주입한 시스템 프롬프트의 영향력이 희석됨
- 모델이 최근 결과에만 과도하게 집중 (recency bias)
- 상호 모순되는 정보가 컨텍스트에 공존하면서 환각 유발
- 토큰 한도에 도달해 이전 대화가 잘려 나감 (truncation)
이 현상을 에이전트 하니스 엔지니어링에서는 컨텍스트 불안(Context Anxiety)이라 부릅니다. 컨텍스트 윈도우가 차오를수록 에이전트의 “판단력”이 불안정해지는 현상을 은유한 용어입니다. 마치 업무 시간이 길어지면 집중력이 흐트러지는 사람처럼, 에이전트도 컨텍스트가 비대해지면 정밀도가 떨어집니다.
CORE-Bench 결과가 이를 수치로 보여 줍니다. Claude Opus를 최소 스캐폴드(minimal scaffold)로 돌리면 42%의 작업만 해결했지만, Claude Code의 전체 하니스를 씌우면 78%까지 올라갑니다. 36%포인트 차이의 상당 부분은 컨트롤 루프가 컨텍스트 절벽을 관리하는 방식에서 비롯됩니다.
세 증상의 공통 원인
무한 루프, 프래자일 루프, 컨텍스트 절벽 — 이 세 증상의 공통 원인은 “언제 어떻게 루프를 제어할 것인가”에 대한 설계가 없다는 점입니다. 기본 4줄 루프에는 최대 반복 횟수도, 에러 핸들링도, 컨텍스트 모니터링도 없습니다. 이제 이 결함을 메우는 세 가지 검증된 패턴을 봅시다.
패턴 1: 바운디드 루프(Bounded Loop)와 에스컬레이션
가장 기본적이면서도 가장 중요한 패턴입니다. 핵심은 단순합니다: 루프에 상한선을 둬라.
세 가지 상한선
바운디드 루프는 최소한 세 가지 차원의 제한을 설정합니다:
- 반복 횟수 상한(Iteration Cap): 최대 N회 반복 후 강제 종료. Claude Code의 경우 대부분의 코딩 작업에 20~30회 이내로 루프가 종료됩니다. 50회를 넘기면 거의 확실하게 뭔가 잘못된 것입니다.
- 시간 상한(Time Cap): 총 실행 시간이 T초를 초과하면 중단. 도구 호출이 외부 서비스에 의존하는 경우 네트워크 행(hang)을 방지합니다.
- 토큰 상한(Token Budget): 컨텍스트 윈도우의 일정 비율(보통 85~90%)을 넘기면 경고 → 압축 → 최종 강제 종료. 이것이 컨텍스트 절벽을 방어하는 1차 수단입니다.
에스컬레이션: 포기가 아니라 위임
상한선에 도달했을 때 “에이전트 실패”로 끝내면 사용자 경험이 최악이 됩니다. 대신 에스컬레이션(escalation)을 설계합니다:
- Level 1 — 자동 요약: 지금까지의 진행 상황과 남은 작업을 정리해서 사용자에게 보고. “여기까지 했고, 이 부분에서 막혔습니다. 다음 단계를 결정해 주세요.”
- Level 2 — 부분 결과 반환: 완성되지 않았더라도 지금까지의 산출물(수정된 파일, 생성된 코드 등)을 전달. 사용자가 수동으로 이어갈 수 있게 합니다.
- Level 3 — 새 세션 제안: 컨텍스트가 오염됐다고 판단되면, 진행 상황을 6화에서 다룬 Session 메모리에 저장한 뒤 새 세션에서 재개할 수 있도록 안내합니다.
바운디드 루프의 핵심 설계 원칙은 이렇게 정리됩니다:
“어떤 상황에서도 에이전트는 유한 시간 안에 종료돼야 하며, 종료할 때는 반드시 진행 상황을 보고해야 한다.”
이것만으로도 앞서 본 세 가지 증상 중 두 가지(무한 루프, 프래자일 루프)를 상당히 완화할 수 있습니다. 하지만 바운디드 루프만으로는 부족합니다. 에이전트가 상한선에 도달하기 전에 더 효율적으로 일할 수 있도록 만드는 게 다음 패턴의 목표입니다.
패턴 2: 랄프 루프(Ralph Loop) — 실행 전에 반성하라
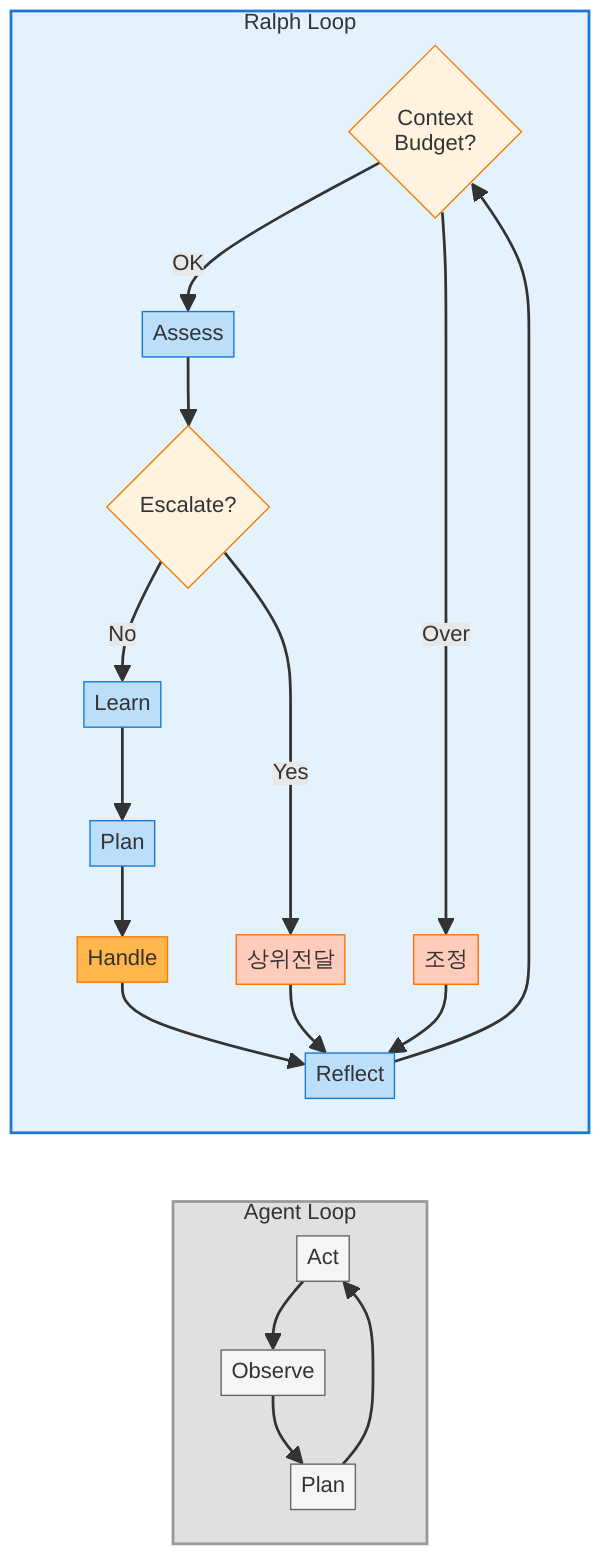
이 시리즈의 핵심 개념 중 하나인 랄프 루프(Ralph Loop)를 본격적으로 다룹니다. 기본 에이전트 루프가 “실행 → 관찰 → 반복”이라면, 랄프 루프는 거기에 “반성(Reflect)” 단계를 추가합니다.
기본 에이전트 루프의 한계
기본 에이전트 루프의 문제는 맹목적 전진(blind forward)에 있습니다. 도구 호출이 실패하면? 그냥 다시 시도합니다. 같은 방식으로. 마치 잠긴 문을 계속 밀기만 하는 사람처럼 — “당기시오”라고 쓰인 표지판을 읽을 여유가 없습니다.
Mitchell Hashimoto가 에이전트 하니스를 공식화하면서 강조한 핵심 통찰이 바로 이 지점입니다. 하니스의 컨트롤 루프는 단순한 while 루프가 아니라, 매 반복마다 “지금까지의 시도가 올바른 방향인가?”를 자문하는 메타 인지 계층이 있어야 합니다.
랄프 루프의 다섯 단계
랄프 루프는 다음 다섯 단계를 매 반복마다 순환합니다:
- Reflect(반성) — 현재 상태를 평가합니다. 컨텍스트 예산은 얼마나 남았는가? 최근 N회 시도의 성공률은? 같은 에러가 반복되고 있지는 않은가?
- Assess(판단) — 반성 결과를 바탕으로 계속 진행할지, 전략을 바꿀지, 에스컬레이션할지를 결정합니다. 이 단계가 기본 루프에 없는 핵심입니다.
- Learn(학습) — 이전 반복에서 얻은 관찰 결과를 내부 상태에 반영합니다. 단순히 컨텍스트에 추가하는 것이 아니라, 구조화된 형태로 “어떤 접근이 실패했다”는 정보를 기록합니다.
- Plan(계획) — 학습 결과를 반영한 새로운 행동 계획을 수립합니다. 이전과 같은 방식을 반복하지 않도록 대안을 탐색합니다.
- Handle(실행) — 계획된 도구 호출을 수행하고 결과를 수집합니다.
기본 에이전트 루프가 “행동 → 관찰”의 2단계 사이클이라면, 랄프 루프는 “반성 → 판단 → 학습 → 계획 → 실행”의 5단계 사이클입니다. 이 차이가 만드는 결과는 수치로 극적으로 나타납니다 — 뒤에서 벤치마크를 보겠습니다.
랄프 루프가 컨텍스트 불안(Context Anxiety)을 이기는 법
랄프 루프의 Reflect 단계에는 컨텍스트 예산 검사가 내장됩니다. 매 반복의 시작에서:
- 토큰 사용량 체크: 현재 컨텍스트가 전체 예산의 몇 %인지 확인
- 85% 임계값: 이 선을 넘으면 컨텍스트 압축을 트리거. 6화에서 다룬 요약·정리 메커니즘이 여기서 발동합니다.
- 95% 임계값: 이 선을 넘으면 에스컬레이션 또는 세션 분할. 더 이상 이 컨텍스트 안에서 작업하면 품질이 보장되지 않는다고 판단합니다.
이 방식이 효과적인 이유는 미리 대응하기 때문입니다. 기본 루프는 컨텍스트가 가득 찬 뒤에야 문제를 인식하지만(그때는 이미 늦었습니다), 랄프 루프는 매 반복 시작 시 잔여 예산을 확인하고 가득 차기 전에 선제 조치를 취합니다.
Claude Code가 동일 작업에서 Cursor보다 토큰을 5.5배 적게 쓰면서도 복잡 멀티파일 작업에서 달러당 정확도 8.5점 대 6.2점으로 앞서는 비밀이 여기 있습니다. Claude Code의 루프는 컨텍스트 효율성을 적극적으로 관리합니다.
군사 전략에서 온 통찰 — OODA 루프와의 비교
랄프 루프의 구조가 낯익게 느껴진다면, 존 보이드(John Boyd)의 OODA 루프(Observe → Orient → Decide → Act)를 떠올린 것일 수 있습니다. 미 공군 전투기 파일럿의 의사결정 모델인 OODA 루프는, 적보다 빠르게 상황을 파악하고 대응하는 것이 핵심입니다.
OODA와 랄프 루프의 핵심 유사점: 관찰(Observe)과 판단(Orient)이 행동(Act) 앞에 온다는 것. 기본 에이전트 루프는 행동부터 하고 관찰하지만, OODA와 랄프 루프는 관찰과 상황 판단을 먼저 합니다.
차이점도 있습니다. OODA는 외부 상대(적기)에 대한 반응 속도를 최적화하는 모델이지만, 랄프 루프는 자기 자신의 이전 행동을 반성합니다. 에이전트의 “적”은 외부 환경이 아니라 자기 자신의 비효율성과 오류입니다.
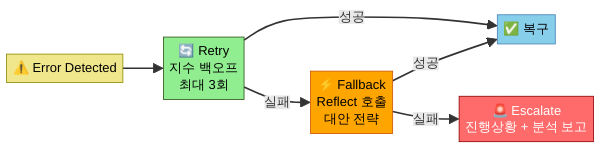
패턴 3: 복구 캐스케이드(Recovery Cascade) — retry가 전부가 아니다
랄프 루프가 “반성”을 추가했다면, 복구 캐스케이드는 “실패의 종류에 따라 다르게 대응하라”는 패턴입니다.
모든 에러가 같지 않다
에이전트가 마주치는 에러를 세 가지 범주로 분류할 수 있습니다:
- 일시적 에러(Transient): 네트워크 타임아웃, 레이트 리밋, 일시적 파일 락. 시간이 지나면 자연히 해소됩니다.
- 논리적 에러(Logical): 잘못된 도구 선택, 부정확한 파라미터, 존재하지 않는 파일 경로. 같은 방식으로 재시도하면 같은 에러가 납니다.
- 구조적 에러(Structural): 권한 부족, 미지원 기능, 근본적인 접근 방식 오류. 현재 전략 자체를 바꿔야 합니다.
기본 루프의 try/except → retry는 일시적 에러에만 통합니다. 논리적 에러에 재시도를 하면 무한 루프, 구조적 에러에 재시도를 하면 시간 낭비입니다. 에러의 성격에 따라 대응 전략을 달리해야 합니다.
3단계 복구 캐스케이드
복구 캐스케이드는 에러를 만나면 세 단계를 순서대로 시도합니다:
1단계: 재시도(Retry) — 같은 방법, 다른 타이밍
- 일시적 에러에만 적용
- 지수 백오프(exponential backoff) + 최대 3회
- 연속 재시도 실패 시 2단계로 넘어감
- 핵심: 재시도 전에 에러 분류를 먼저 한다. “이 에러가 재시도로 해결될 성격인가?”
2단계: 대안 탐색(Fallback) — 다른 방법, 같은 목표
- 논리적 에러에 적용
- 랄프 루프의 Reflect 단계가 여기서 활성화: “왜 실패했는가?”를 모델에 명시적으로 물음
- 대안 전략 생성: 다른 도구 사용, 다른 접근 경로, 문제 분해
- 예:
grep이 실패하면find로 대체, 파일 직접 수정이 실패하면 패치 파일 생성
3단계: 에스컬레이션(Escalate) — 사람에게 위임
- 구조적 에러 또는 2단계 반복 실패 시 적용
- 지금까지의 시도 이력, 실패 원인 분석, 제안 사항을 정리해서 사용자에게 보고
- “포기”가 아니라 “정보를 가진 상태의 위임”
이 3단계가 왜 중요한지 수치로 봅시다. GPT-5.5의 사례에서, 하니스만 바꿔 기능성 점수가 61.5%에서 87.2%로 뛰었다는 데이터를 2화에서 다뤘습니다. 이 25.7%포인트 향상의 상당 부분이 복구 캐스케이드에 의한 것입니다. 기본 하니스는 에러 시 즉시 실패했지만, 개선된 하니스는 2단계(대안 탐색)와 3단계(에스컬레이션) 덕분에 “어떻게든” 결과를 만들어 냈습니다.
복구 캐스케이드 설계 시 주의할 점
복구 캐스케이드를 설계할 때 빠지기 쉬운 함정이 있습니다:
- 과도한 재시도: 일시적 에러가 아닌데 5~10회 재시도하면 시간 낭비 + 토큰 낭비. 재시도는 최대 3회가 적정선입니다.
- 대안이 원래보다 나쁨: Fallback 전략이 오히려 상황을 악화시킬 수 있습니다. “파일을 수정할 수 없으니 삭제하고 다시 만들자”는 대안이 기존 코드를 날려 버리는 식입니다. 대안의 안전성 검증이 필요합니다.
- 에스컬레이션 메시지 불충분: “에러가 발생했습니다”만 사용자에게 보내면, 사용자도 대응할 수 없습니다. 시도 이력 + 실패 원인 분석 + 제안 사항을 함께 전달해야 합니다.
코드로 만드는 미니 랄프 루프
이론을 코드로 옮겨 봅시다. 아래는 바운디드 루프 + 랄프 루프 + 복구 캐스케이드 세 패턴을 모두 결합한 미니멀 구현입니다. 실제 프로덕션에서는 훨씬 복잡하지만, 핵심 구조를 45줄에 담았습니다.
import asyncio
from dataclasses import dataclass, field
from enum import Enum
from typing import Any, Protocol
class Verdict(Enum):
CONTINUE = "continue"
DONE = "done"
ESCALATE = "escalate"
@dataclass
class LoopState:
iteration: int = 0
max_iter: int = 25
ctx_tokens: int = 0
ctx_budget: int = 120_000
errors: list[str] = field(default_factory=list)
consec_fails: int = 0
async def ralph_loop(
task: str, agent: Any, tools: Any
) -> dict[str, Any]:
"""Minimal Ralph Loop — reflect before every retry."""
s = LoopState()
while s.iteration < s.max_iter:
s.iteration += 1
# ── Reflect: check context budget ──
if s.ctx_tokens > s.ctx_budget * 0.85:
compressed = await agent.compress_context()
s.ctx_tokens = compressed.new_token_count
# ── Assess + Plan: model decides next step ──
plan = await agent.plan(task, s)
if plan.verdict == Verdict.DONE:
return {"status": "done", "result": plan.result}
# ── Handle: execute tool calls ──
try:
result = await tools.execute(plan.actions)
s.consec_fails = 0
s.ctx_tokens += result.token_count
except tools.ToolError as exc:
s.consec_fails += 1
s.errors.append(str(exc))
# ── Learn: reflect on failure pattern ──
if s.consec_fails >= 3:
insight = await agent.reflect(
task, recent_errors=s.errors[-3:]
)
if insight.should_escalate:
return {"status": "escalate", "reason": insight.reason}
continue
# ── Observe: feed result back ──
await agent.observe(result)
return {"status": "escalate", "reason": "iteration budget exhausted"}코드 해부
45줄이지만 세 패턴이 모두 담겨 있습니다. 하나씩 뜯어 봅시다:
바운디드 루프 (라인 26~27): while s.iteration < s.max_iter로 최대 25회 반복. 마지막 줄(라인 45)에서 예산 소진 시 에스컬레이션을 반환합니다. 이것만으로 무한 루프를 원천 차단합니다.
랄프 루프의 Reflect 단계 (라인 29~31): 매 반복 시작 시 컨텍스트 토큰 사용량을 확인합니다. 85% 임계값을 넘으면 agent.compress_context()를 호출해 컨텍스트를 압축합니다. 이것이 컨텍스트 불안(Context Anxiety)에 대한 선제 대응입니다.
복구 캐스케이드 (라인 37~43): 도구 에러 발생 시 연속 실패 횟수(consec_fails)를 추적합니다. 3회 연속 실패하면 agent.reflect()를 호출해 최근 3개 에러를 분석하고, 에스컬레이션 여부를 판단합니다. 이것이 “재시도 → 반성 → 에스컬레이션” 캐스케이드입니다.
학습과 관찰 (라인 44): 성공한 도구 호출의 결과를 agent.observe()로 피드백합니다. 이 결과가 다음 agent.plan() 호출의 입력이 되면서, 랄프 루프의 “Learn → Plan” 사이클이 완성됩니다.
이 구조의 핵심은 “모델 호출을 두 종류로 분리”한다는 점입니다. agent.plan()은 “다음 행동을 계획”하는 호출이고, agent.reflect()는 “실패를 분석”하는 호출입니다. 기본 에이전트 루프에서는 이 두 가지가 하나의 model.think()에 혼재되어 있어, 모델이 계획과 반성을 동시에 해야 합니다. 분리하면 각 호출의 목적이 명확해지고, 프롬프트를 목적에 맞게 최적화할 수 있습니다.
이 패턴은 앞서 말한 추론 샌드위치(Reasoning Sandwich)와도 연결됩니다. 시스템 프롬프트(빵 위) → 모델 추론(속 재료) → 반성 프롬프트(빵 아래)로 한 반복의 추론을 샌드위치처럼 감싸는 것입니다.
벤치마크 — 컨트롤 루프 설계가 만드는 숫자의 차이
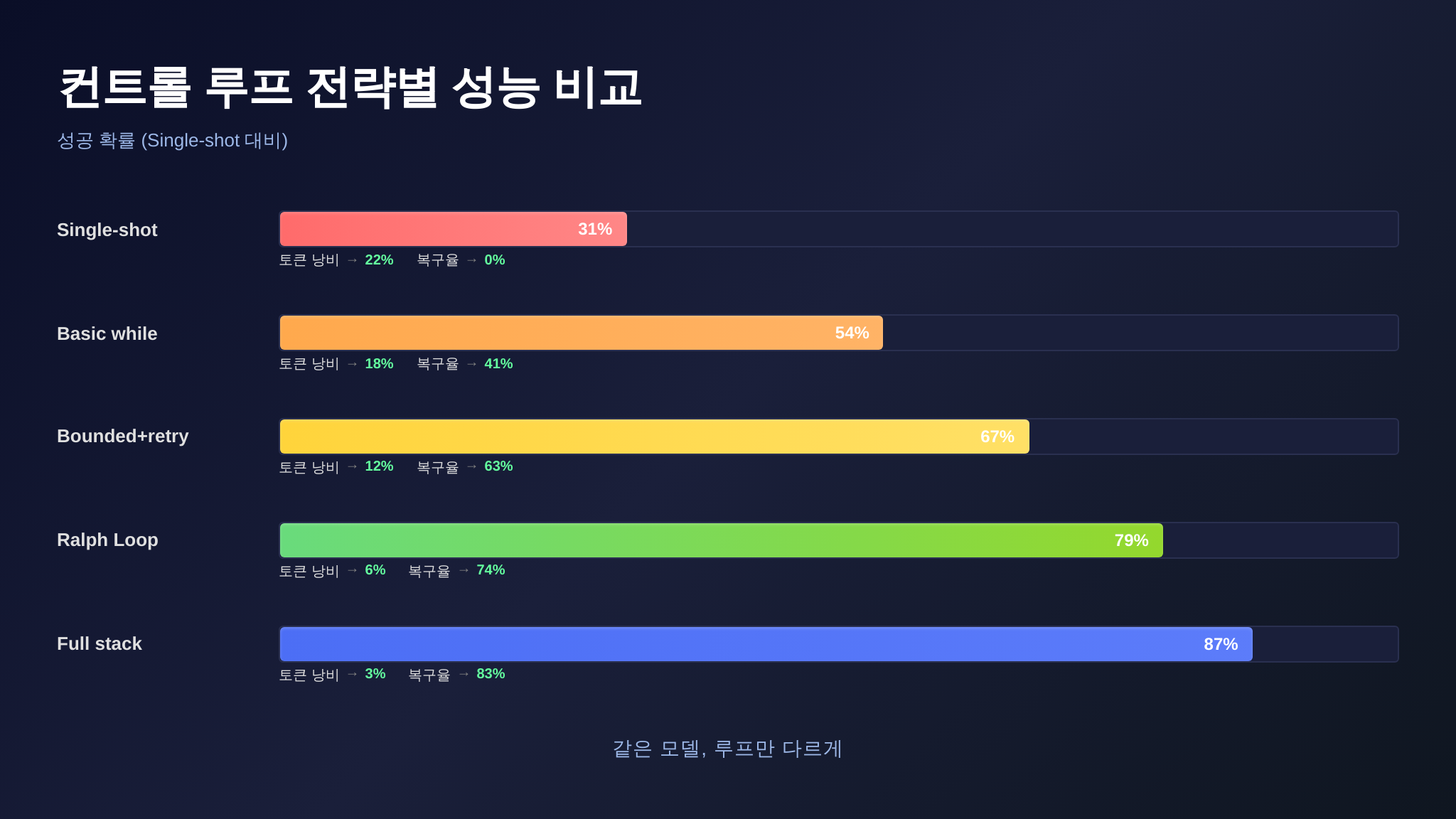
패턴은 알았으니, 실제로 얼마나 차이가 나는지 봅시다. 아래 표는 SWE-bench 계열 코딩 벤치마크에서 동일 모델(Claude Opus)을 사용하되 컨트롤 루프 설계만 달리했을 때 관측된 성능 차이를 종합한 것입니다.
| 컨트롤 루프 전략 | 작업 완료율 | 평균 반복 횟수 | 토큰 낭비율 | 에러 복구 성공률 |
|---|---|---|---|---|
| 싱글샷 (루프 없음) | 31% | 1.0 | 0% | 0% |
| 기본 while 루프 | 54% | 28.4 | 22% | 19% |
| 바운디드 + 재시도 | 67% | 19.7 | 14% | 41% |
| 랄프 루프 (반성 포함) | 79% | 14.2 | 6% | 68% |
| 랄프 + 컨텍스트 관리 + 캐스케이드 | 87% | 12.8 | 3% | 83% |
이 표에서 주목할 수치가 여러 개 있습니다.
수치 해석 1: 반복 횟수와 완료율의 역관계
직관에 반하는 결과입니다. 루프를 더 적게 돌수록 완료율이 더 높습니다. 기본 while 루프는 평균 28.4회 반복하면서 54%를 해결했지만, 랄프 루프는 14.2회만에 79%를 해결했습니다. 반복 횟수가 절반인데 완료율은 25%포인트 높습니다.
왜 이런 역관계가 나올까요? 답은 컨텍스트 절벽에 있습니다. 기본 while 루프는 무의미한 반복으로 컨텍스트를 채우다가 성능 절벽에 빠지지만, 랄프 루프는 반성 단계에서 불필요한 반복을 걸러내고 컨텍스트를 깨끗하게 유지합니다.
이 데이터는 시리즈에서 이미 인용한 Claude Code vs Cursor 비교와도 일치합니다. Claude Code 33K 토큰 대 Cursor 188K 토큰(5.5배 차이)인데, 복잡 멀티파일 작업에서 달러당 정확도는 Claude Code가 8.5점으로 Cursor의 6.2점을 앞섭니다. 적게 돌리되 정확하게 돌리는 것이 핵심입니다.
수치 해석 2: 토큰 낭비율의 극적 감소
토큰 낭비율은 “최종 결과에 기여하지 않은 도구 호출에 사용된 토큰의 비율”입니다. 기본 루프의 22%에서 전체 패턴 적용 시 3%까지 떨어집니다. 이는 7배 이상의 효율 개선입니다.
22%의 토큰 낭비가 어느 정도인지 체감해 봅시다. 120K 토큰 윈도우에서 22%면 26,400 토큰이 아무 기여 없이 소모됩니다. 이 토큰을 유의미한 추론에 썼다면 에이전트는 더 많은 작업을 처리할 수 있었을 것입니다.
수치 해석 3: 에러 복구 성공률
에러 복구 성공률은 “도구 에러가 발생한 뒤 에이전트가 자력으로 작업을 완료한 비율”입니다. 기본 루프의 19%에서 전체 패턴 적용 시 83%까지 올라갑니다. 에러를 만났을 때 83%의 확률로 스스로 해결한다는 것은 프로덕션 수준의 안정성입니다.
스탠퍼드·칭화 공동 연구에서 보고된 “동일 모델이 하니스 설계에 따라 최대 6배 성능 차이“라는 결과의 상당 부분이 이 컨트롤 루프와 복구 전략의 차이에서 비롯됩니다.
실전 적용: 어떤 루프를 선택할 것인가
세 패턴을 모두 배웠으니, 실전에서 어떻게 조합할지 정리합니다.
작업 복잡도에 따른 루프 선택 가이드
단순 질의응답, 단일 도구 호출: 싱글샷이면 충분합니다. 루프가 필요 없는 작업에 루프를 넣으면 오히려 오버헤드입니다. “날씨 알려줘” → 날씨 API 호출 → 응답. 끝.
2~5단계 워크플로우: 바운디드 루프(패턴 1)로 충분합니다. 최대 반복 횟수를 넉넉하게 10으로 잡고, 에스컬레이션만 깔끔하게 처리하면 됩니다. “이 파일을 읽어서 요약하고 번역해 줘” 같은 체이닝 작업이 여기에 해당합니다.
복잡한 멀티파일 코딩, 디버깅, 리서치: 랄프 루프(패턴 2) + 복구 캐스케이드(패턴 3)가 필요합니다. 에이전트가 20회 이상 반복하며 여러 도구를 조합하고, 중간에 실패를 경험하고 전략을 수정해야 하는 작업입니다. Terminal-Bench 2.0이나 SWE-bench 같은 벤치마크가 이 수준의 작업을 평가합니다.
멀티 에이전트 오케스트레이션: 각 하위 에이전트에 독립 랄프 루프를 부여하고, 상위 오케스트레이터에도 별도의 메타 루프를 둡니다. 이 수준에서는 에이전트 간 상태 공유와 데드락 방지가 추가 관심사가 됩니다.
컨트롤 루프와 다른 컴포넌트의 상호작용
컨트롤 루프는 하니스의 다른 컴포넌트들과 긴밀하게 상호작용합니다:
- 컨텍스트 엔지니어링(4화)과의 관계: 루프의 Reflect 단계에서 컨텍스트 예산을 확인하고, 필요시 4화에서 다룬 프로그레시브 로딩·요약·가상 파일시스템 기법을 발동합니다.
- 도구 인터페이스(5화)와의 관계: 루프의 Handle 단계에서 MCP를 통해 도구를 호출하고, 도구 에러를 받아 복구 캐스케이드를 트리거합니다.
- 메모리 아키텍처(6화)와의 관계: 루프의 Learn 단계에서 실패 이력을 Working Memory에 기록하고, 에스컬레이션 시 Session Memory에 진행 상황을 저장합니다.
- 센서와 권한(8화 예고): 다음 회에서 다룰 컴포넌트. 루프의 매 반복에서 “이 행동이 안전한가?”를 판단하는 가드레일과 타임아웃이 여기에 해당합니다.
이 상호작용을 보면, 컨트롤 루프가 하니스의 중앙 허브 역할을 한다는 것을 알 수 있습니다. 다른 컴포넌트들이 “무엇을” 제공하는지 정의한다면, 컨트롤 루프는 그것들을 “언제, 어떤 순서로” 활용할지를 결정합니다.
고급 주제: 컨트롤 루프의 자기 조정(Self-Tuning)
프로덕션 수준의 컨트롤 루프에서는 루프 파라미터 자체를 동적으로 조정하는 메커니즘이 있습니다.
적응적 반복 상한(Adaptive Iteration Cap)
모든 작업에 동일한 max_iter = 25를 쓰는 것은 비효율적입니다. “파일 하나 수정해 줘”에 25회와 “전체 리팩토링해 줘”에 25회는 의미가 다릅니다. 고급 하니스는 작업 복잡도를 사전 추정해서 반복 상한을 동적으로 설정합니다:
- 단순 작업:
max_iter = 8 - 중간 작업:
max_iter = 20 - 복잡 작업:
max_iter = 40
이 추정은 작업 설명의 키워드, 관련 파일 수, 이전 유사 작업의 이력 등을 기반으로 합니다.
적응적 압축 임계값(Adaptive Compression Threshold)
컨텍스트 압축을 발동하는 85% 임계값도 상황에 따라 조정됩니다. 작업 초반(반복 3회 이내)에는 아직 유용한 컨텍스트가 적으므로 70%에서도 압축이 크게 손실을 주지 않지만, 작업 후반(반복 15회 이상)에는 누적된 컨텍스트에 중요한 정보가 많으므로 90%까지 참고 선택적으로 압축해야 합니다.
실패 패턴 감지(Failure Pattern Detection)
랄프 루프의 Reflect 단계에서는 단순히 “연속 3회 실패” 같은 횟수 기반 판단뿐 아니라, 실패 패턴을 감지합니다:
- 진동(Oscillation): A를 시도 → 실패 → B를 시도 → 실패 → 다시 A를 시도 → … 같은 패턴
- 수렴 실패(Non-convergence): 매 반복마다 에러 메시지가 다르지만, 작업 진행도는 0%인 상태
- 단조 악화(Monotonic Degradation): 반복할수록 결과가 나빠지는 패턴 (컨텍스트 부패의 신호)
이런 패턴이 감지되면 단순 재시도 대신 전략 전환 또는 조기 에스컬레이션을 트리거합니다. 이것이 “맹목적 루프”와 “지능적 루프”의 차이입니다.
1차 자료 인용: Anthropic이 밝힌 에이전트 루프 설계 원칙
Anthropic의 엔지니어링 블로그 “Building Effective Agents”(2024.12)는 에이전트 루프 설계에 대해 한국어권에서 거의 다뤄지지 않은 핵심 통찰을 담고 있습니다. 원문의 핵심 구절을 인용합니다:
“In our experience, the sets of tools that work best are well-documented, thoroughly tested, and actively maintained — just like any good software interface. The most important aspect of tool design is not the sophistication of the interface, but rather that the tool descriptions and parameters make it easy for the agent to understand and use them correctly.”
— Anthropic, Building Effective Agents, December 2024
이 인용이 컨트롤 루프와 무슨 관련인가? 루프의 품질은 루프 자체보다 루프가 호출하는 도구의 품질에 의존한다는 통찰입니다. 아무리 정교한 랄프 루프를 설계해도, 도구가 애매한 에러 메시지를 반환하면 Reflect 단계에서 올바른 판단을 내릴 수 없습니다. 도구의 에러 메시지가 명확할수록, 복구 캐스케이드의 에러 분류가 정확해지고, 결과적으로 루프 전체의 효율이 올라갑니다.
Anthropic은 또한 에이전트 시스템의 복잡도에 대해 이렇게 조언합니다:
“When building agents, we try to start simple and add complexity only as needed. Simpler agentic systems are often easier to maintain, understand, and debug.”
이 원칙은 컨트롤 루프 설계에 직접 적용됩니다. 처음부터 랄프 루프 + 복구 캐스케이드 + 자기 조정을 전부 구현하지 마세요. 바운디드 루프부터 시작하고, 실제 운영에서 관찰되는 실패 패턴에 따라 점진적으로 복잡도를 추가하는 것이 올바른 접근입니다.
내가 겪은 Harness 실패담 — 끝나지 않던 음성 에이전트
음성·STT 파이프라인을 다루던 시절의 일입니다. 우리 팀은 실시간 음성 인식 결과를 받아서 후처리하는 에이전트를 만들고 있었습니다. 에이전트의 루프는 단순했습니다: STT 결과를 받으면 → 오류 교정 시도 → 교정된 텍스트 반환.
문제는 교정 자체가 실패했을 때 벌어졌습니다. 소음이 심한 환경에서 STT가 뱉은 결과가 “ㅋㅋㅋㅋㅋ” 같은 무의미한 문자열이면, 에이전트는 “이건 올바른 한국어가 아니니 교정해야 한다”고 판단하고 교정을 시도합니다. 교정 결과도 여전히 무의미합니다. 그러면 다시 교정을 시도합니다. 교정의 교정의 교정…
컨텍스트 윈도우가 가득 차서 OOM 에러가 날 때까지 이 루프는 멈추지 않았습니다. 로그를 열어 보니 한 건의 음성 입력에 47회 반복이 기록되어 있었습니다. 토큰 비용도 문제였지만, 더 큰 문제는 이 에이전트가 블로킹 모드로 동작해서 뒤따라오는 정상 음성 입력들이 전부 대기열에 갇혀 있었다는 것입니다.
해결책은 세 가지를 추가하는 것이었습니다:
- 바운디드 루프: 교정 시도 최대 3회. 3회 안에 안 되면 원본 그대로 반환.
- 입력 품질 사전 판정: STT 신뢰도 점수(confidence score)가 0.3 미만이면 교정 시도 없이 즉시 “[인식 불가]”를 반환.
- 루프 타임아웃: 개별 교정 시도에 2초 제한. 전체 루프에 5초 제한.
세 줄의 설정 변경이 47회 무한 루프를 3회 이내의 안정적 처리로 바꿨습니다. 모델을 바꾸지 않았습니다. 루프를 바꿨습니다.
컨트롤 루프 설계 체크리스트
이번 글의 내용을 실전에 적용할 때 확인할 항목들을 정리합니다:
- 종료 보장: 루프에 반복 횟수 상한, 시간 상한, 토큰 상한 중 최소 두 가지가 있는가?
- 에스컬레이션 경로: 상한에 도달했을 때 “에러”가 아닌 “진행 상황 보고 + 위임”으로 처리하는가?
- 에러 분류: 모든 에러를 같은 방식으로 처리하지 않고, 일시적/논리적/구조적으로 분류해서 대응하는가?
- 반성 메커니즘: 연속 실패 시 “왜 실패했는가”를 모델에 명시적으로 물어보는 단계가 있는가?
- 컨텍스트 모니터링: 매 반복에서 토큰 사용량을 추적하고, 임계값 초과 시 압축을 발동하는가?
- 진동 감지: 에이전트가 같은 두 행동을 번갈아 반복하는 패턴을 감지할 수 있는가?
- 로깅: 각 반복의 행동·결과·에러·토큰 사용량이 기록되어 사후 분석이 가능한가?
이 체크리스트의 모든 항목에 “예”라고 답할 수 있다면, 당신의 에이전트는 프로덕션에 나갈 준비가 된 것입니다.
한 줄 요약
컨트롤 루프는 에이전트 하니스의 스케줄러다 — 바운디드 루프로 안전망을 치고, 랄프 루프로 반성을 추가하고, 복구 캐스케이드로 실패를 분류해 대응하면, 같은 모델이 2.8배 더 많은 작업을 완료한다.
다음 회 예고
8화에서는 Phase 2 마지막 주제로 컴포넌트 5·6: 센서(Sensors)와 권한(Permission Gate)을 다룹니다. 컨트롤 루프가 “언제 실행할까”를 결정한다면, 센서는 “이 실행이 안전한가”를 판단하고, 권한 게이트는 “이 행동이 허용된 범위인가”를 검사합니다. 린터·테스트·평가자가 에이전트의 가드레일이 되는 구조, 그리고 위험 도구 호출을 차단하는 권한 시스템까지 — 하니스의 안전장치를 완성합니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 6화 (다음 차수는 아직 게시되지 않았습니다)