
이 글은 AI Harness 시리즈 2화입니다. 1화에서 에이전트 하니스가 무엇인지, 왜 LLM을 ‘CPU’로, 하니스를 ‘OS’로 비유하는지를 소개했습니다. 이번에는 말이 아니라 숫자로 증명합니다. 같은 모델이 하니스만 달라도 16점, 6배, 5.5배까지 차이가 나는 다섯 개의 독립 벤치마크를 한국어로 처음 교차 분석합니다.
같은 CPU에 다른 OS를 올리면 — 비유에서 실험으로
1화에서 던진 비유를 다시 꺼내 보겠습니다. LLM은 CPU, 컨텍스트 윈도우는 RAM, 그리고 에이전트 하니스(Agent Harness)는 OS입니다. 같은 CPU를 장착해도 Windows와 Linux에서 워크로드 성능이 다르듯, 같은 모델을 감싸는 하니스가 다르면 결과도 달라져야 합니다.
직관적으로는 수긍이 가지만, 실무에서는 여전히 “더 좋은 모델을 쓰면 해결된다”는 사고가 지배적입니다. 모델 업그레이드는 신용카드 한 줄이면 끝나고, 하니스 설계는 며칠이 걸리니까요. 과연 하니스에 투자할 가치가 있는 걸까요?
이 질문에 답하기 위해, 2025년 말부터 2026년 초까지 공개된 다섯 개의 독립 벤치마크를 모아봤습니다. 결론부터 말하면 — 모델 교체보다 하니스 교체가 ROI가 더 높은 경우가 압도적으로 많았습니다.
Terminal-Bench 2.0 — 16점 격차의 해부
벤치마크 소개: 터미널 에이전트의 종합 시험
Matt Mayer가 설계한 Terminal-Bench 2.0은 코딩 에이전트가 터미널 환경에서 실제 개발 작업을 수행하는 능력을 측정하는 독립 벤치마크입니다. 단순 코드 생성이 아니라 파일 탐색, 빌드 시스템 조작, 테스트 실행, 디버깅까지 아우르는 종합 시나리오를 포함합니다.
한국어권에서 이 벤치마크가 본격적으로 다뤄진 적은 없습니다. 영어권 AI 엔지니어링 커뮤니티에서는 이미 “하니스 효과(Harness Effect)”의 결정적 증거로 인용되고 있지만, 국내에선 아직 모델 리더보드만 주목하는 분위기입니다.
“The same model scored 93% and 77% depending on which harness wrapped it. At that point, arguing about model rankings becomes almost meaningless.”
— Matt Mayer, Terminal-Bench 2.0 독립 테스트 결과 코멘터리
결과: 같은 모델, 다른 점수
핵심 데이터는 이것입니다.
- Claude Opus + Cursor 하니스: Terminal-Bench 2.0 정확도 93%
- Claude Opus + Claude Code 하니스: Terminal-Bench 2.0 정확도 77%
모델은 완전히 동일한 Claude Opus입니다. API 키도 같고, 모델 웨이트도 같습니다. 바뀐 것은 오직 하니스 — 모델을 감싸는 시스템 프롬프트, 컨텍스트 관리 전략, 도구 호출 인터페이스, 에러 복구 루프뿐입니다.
이 16점 차이가 의미하는 바를 곱씹어 보겠습니다. 모델 세대 간 업그레이드(예: GPT-4 → GPT-4.5)가 벤치마크에서 만드는 차이가 보통 5~12점입니다. 하니스 교체 한 번이 모델 한 세대 업그레이드보다 더 큰 격차를 만들어낸 겁니다.
왜 Cursor가 이 벤치마크에서 이겼을까?
흥미로운 점은 Claude Code가 “더 정교한 하니스”로 알려져 있음에도 Terminal-Bench 2.0에서는 Cursor에 졌다는 사실입니다. 이유를 뜯어보면 하니스 설계의 핵심 원리가 드러납니다.
- Cursor의 강점: IDE 통합 환경에서 파일 트리 전체를 하니스가 이미 ‘보고’ 있습니다. 터미널 작업에서 파일 탐색 비용이 사실상 0입니다. 컨텍스트 윈도우(RAM)에 필요한 정보가 이미 로딩되어 있는 상태에서 모델(CPU)이 작업을 시작하는 셈입니다.
- Claude Code의 설계 철학: 반대로 Claude Code는 “필요할 때 필요한 만큼만” 파일을 읽습니다. 토큰 효율은 높지만, 터미널 중심 벤치마크에서는 이 신중함이 오히려 불리하게 작용합니다. 아직 안 읽은 파일에 답이 있을 수 있으니까요.
이것은 “최고의 하니스”는 없고, “특정 워크로드에 최적인 하니스”만 있다는 것을 증명합니다. OS 비유로 돌아가면, 리얼타임 임베디드 시스템에는 RTOS가 낫고, 웹 서버에는 Linux가 나은 것과 같은 이치입니다.
증거의 삼각 검증 — 다섯 개의 독립 데이터
Terminal-Bench 2.0 하나만으로 결론을 내리기엔 성급합니다. 과학의 기본 원칙은 독립적 재현이니까요. 다행히 2025-2026년에 걸쳐 하니스 효과를 입증하는 데이터가 여러 곳에서 나왔습니다.
CORE-Bench: 42% vs 78%
CORE-Bench는 연구 논문의 실험 결과를 재현하는 능력을 테스트하는 벤치마크입니다. 단순 코딩이 아니라, 논문을 읽고 → 실험 환경을 구성하고 → 코드를 작성하고 → 결과를 검증하는 멀티스텝 작업입니다.
- Claude Opus + 최소 스캐폴드(단순 프롬프트 전달): 42%
- Claude Opus + Claude Code 전체 하니스(컨텍스트 관리 + 도구 + 재시도 루프): 78%
같은 Claude Opus 모델인데 36점 차이입니다. 최소 스캐폴드에서는 절반도 못 풀던 문제를, 제대로 된 하니스를 씌우자 거의 80%를 해결했습니다. Terminal-Bench에서는 Cursor에 졌던 Claude Code가 여기서는 압도적 우위를 보이는 점도 주목해야 합니다. 하니스-워크로드 적합성(fit)이 결과를 좌우하는 거죠.
GPT-5.5: 하니스만 바꿔 25.7점 점프
OpenAI 진영에서도 비슷한 증거가 나왔습니다. GPT-5.5를 대상으로 한 테스트에서, 하니스만 교체했을 때 기능성(functionality) 점수가 이렇게 바뀌었습니다.
- 기존 하니스: 61.5%
- 최적화된 하니스: 87.2%
모델 웨이트는 1비트도 바뀌지 않았습니다. 시스템 프롬프트를 재설계하고, 컨텍스트 로딩 전략을 수정하고, 에러 복구 루프를 추가한 것뿐입니다. 25.7점이 올랐습니다.
스탠퍼드·칭화 합동 연구: 최대 6배
학계도 가세했습니다. 스탠퍼드 대학교와 칭화 대학교의 합동 연구에서, 동일 모델이 하니스 설계에 따라 최대 6배의 성능 차이를 보인다는 결과가 발표되었습니다. 이 연구가 특히 가치 있는 이유는 단일 벤치마크가 아닌 다양한 도메인과 태스크 유형에 걸쳐 이 패턴이 일관되게 나타났기 때문입니다.
6배라는 숫자를 체감해 보겠습니다. 같은 모델로 작업했는데 팀 A는 1시간에 6개를 해결하고 팀 B는 1개를 해결한다면 — 차이의 원인이 모델이 아니라 그 모델을 어떻게 감쌌느냐에 있다는 뜻입니다.
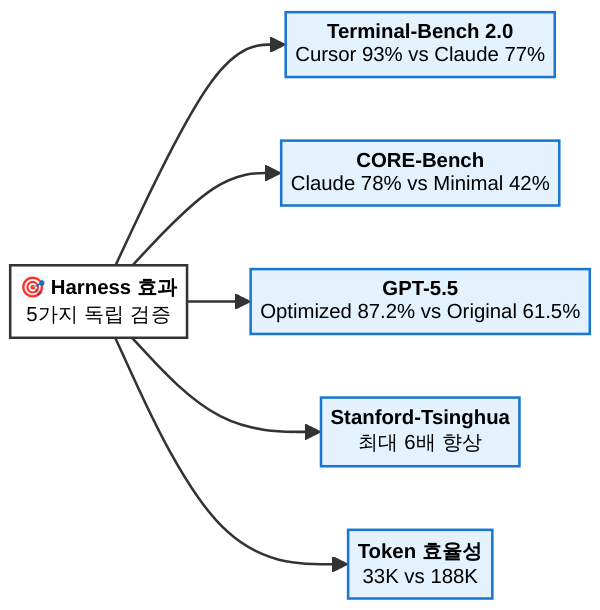
종합 비교 표: 하니스 효과 다섯 장의 증거
| 벤치마크 | 모델 | 하니스 A (점수) | 하니스 B (점수) | 격차 | 출처 |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | Claude Opus | Cursor (93%) | Claude Code (77%) | 16점 | Matt Mayer 독립 테스트 |
| CORE-Bench | Claude Opus | Claude Code 전체 (78%) | 최소 스캐폴드 (42%) | 36점 | CORE-Bench 공개 결과 |
| 기능성 테스트 | GPT-5.5 | 최적화 하니스 (87.2%) | 기존 하니스 (61.5%) | 25.7점 | 하니스 스왑 실험 |
| 다중 도메인 | 복수 모델 | 최적 하니스 (6x) | 기본 하니스 (1x) | 최대 6배 | 스탠퍼드·칭화 합동 |
| 토큰 효율 | Claude Opus | Claude Code (33K) | Cursor (188K) | 5.5배 | 동일 작업 비교 |
다섯 개의 독립 데이터가 같은 방향을 가리킵니다. 모델을 바꾸지 않아도, 하니스를 바꾸면 성능이 극적으로 달라진다. 이것은 더 이상 가설이 아닙니다.
토큰의 물리학 — 5.5배 효율 격차
벤치마크 정확도만 보면 이야기의 절반밖에 안 보입니다. 실무에서 진짜 중요한 건 “그 점수를 얻기 위해 얼마나 썼느냐”입니다. 여기서 하니스 설계의 또 다른 차원이 드러납니다.
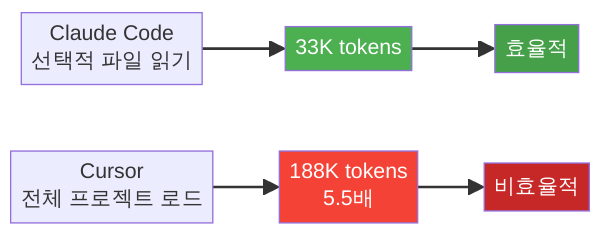
같은 작업, 토큰 사용량 5.5배 차이
동일한 코딩 작업을 Claude Code와 Cursor에 각각 맡겼을 때, 소비된 토큰 수를 비교한 데이터가 있습니다.
- Claude Code: 약 33,000 토큰
- Cursor: 약 188,000 토큰
5.5배 차이입니다. Cursor가 같은 작업에 토큰을 5배 넘게 썼습니다.
왜 이런 차이가 생길까?
토큰 사용량 차이의 핵심은 컨텍스트 관리 전략에 있습니다. OS 비유를 다시 꺼내면, 이것은 메모리 관리 정책의 차이와 같습니다.
- Cursor의 전략 — “열심히 읽기(Eager Loading)”: IDE에 열려 있는 파일들, 프로젝트 트리 전체, 관련될 수 있는 컨텍스트를 적극적으로 컨텍스트 윈도우(RAM)에 올립니다. 파일 탐색 비용이 0에 가까워 Terminal-Bench 같은 벤치마크에서 빠른 응답을 만들어내지만, 토큰 소비가 급증합니다.
- Claude Code의 전략 — “필요할 때 읽기(Lazy Loading)”: 정말 필요한 파일만 선별적으로 읽습니다. 한 번에 컨텍스트 윈도우에 올리는 양이 적어 토큰 효율은 높지만, 필요한 정보를 아직 안 읽었을 때 한 스텝이 더 필요할 수 있습니다.
두 전략 모두 합리적입니다. 문제는 어느 쪽이 더 낫냐가 아니라, 워크로드에 맞는 전략을 고르느냐입니다.
더 많은 토큰 ≠ 더 나은 결과
여기서 반직관적인 포인트가 나옵니다. Cursor가 5.5배 더 많은 토큰을 쓴다고 해서 항상 5.5배 더 좋은 결과를 내는 것은 아닙니다. CORE-Bench에서 Claude Code(적은 토큰)가 78%를 기록하고 최소 스캐폴드(많은 불필요 토큰 가능성)가 42%에 머문 것을 떠올려 보세요.
컨텍스트 윈도우는 RAM과 같습니다. RAM에 불필요한 데이터를 가득 채우면 정작 중요한 데이터가 swap out 되듯, 컨텍스트 윈도우에 관련 없는 파일을 잔뜩 올리면 모델의 주의(attention)가 분산됩니다. Mitchell Hashimoto가 “컨텍스트 부패(Context Rot)”라고 부른 현상이 바로 이것입니다 — 컨텍스트가 쌓일수록 오히려 정확도가 떨어지는 역설.
좋은 하니스는 적절한 양의 컨텍스트를 적절한 시점에 로딩합니다. 이것이 하니스 설계에서 컨텍스트 엔지니어링이 핵심 컴포넌트인 이유이며, 이 주제는 4화에서 깊이 다룰 예정입니다.
달러당 정확도 — 복잡도에 따라 승자가 바뀐다
토큰 사용량과 정확도를 함께 고려하면 “달러당 정확도(accuracy per dollar)”라는 실무 지표가 나옵니다. 이 지표에서 매우 흥미로운 역전 현상이 관찰됩니다.
복잡한 작업: Claude Code 승
멀티파일 리팩토링, 대규모 코드베이스 디버깅 같은 복잡한 작업에서의 달러당 정확도:
- Claude Code: 8.5점
- Cursor: 6.2점
Claude Code의 “필요할 때 읽기” 전략이 빛을 발합니다. 복잡한 작업일수록 전체 파일을 한꺼번에 올리는 것보다 선별적 탐색이 토큰 대비 효과적입니다.
단순한 작업: Cursor 승
단일 파일 유틸리티 함수 작성, 간단한 버그 수정 같은 단순 작업에서는 판이 뒤집힙니다:
- Cursor: 42점
- Claude Code: 31점
파일 하나만 보면 되는 작업에서는, Cursor의 즉각적 파일 접근이 Claude Code의 신중한 탐색보다 훨씬 효율적입니다.
이것이 의미하는 것
이 역전 현상은 하니스 선택이 “뭐가 최고냐”가 아니라 “내 워크로드에 뭐가 맞느냐”의 문제임을 결정적으로 보여줍니다. 마치 OS 선택과 같습니다:
- 고성능 서버 → Linux
- 영상 편집 워크스테이션 → macOS
- 기업 사무 환경 → Windows
어느 것이 “최고의 OS”인가는 무의미한 질문입니다. “내 워크로드에 최적인 OS는?”이 올바른 질문이듯, “내 에이전트 작업에 최적인 하니스는?”이 올바른 질문입니다. 이 질문에 답하는 프레임워크는 시리즈 마지막 Phase 4(11~12화)에서 체계적으로 다룹니다.
하니스 효과의 메커니즘 — 왜 하니스가 점수를 바꾸는가
데이터는 충분합니다. 이제 “왜”를 살펴볼 차례입니다. 하니스가 같은 모델의 성능을 이토록 크게 바꿀 수 있는 이유는 무엇일까요?
Mitchell Hashimoto가 정리한 에이전트 하니스의 6대 핵심 컴포넌트가 그 답입니다:
- 컨텍스트 엔지니어링 — 무엇을 읽고 무엇을 버릴 것인가 (토큰 예산, 프로그레시브 로딩)
- 도구 인터페이스 — 모델이 외부 세계와 어떻게 상호작용하는가 (MCP, 도구 docstring)
- 메모리 아키텍처 — 이전 대화와 결정을 어떻게 기억하는가 (Working/Session/Long-term)
- 컨트롤 루프 — 실행 → 관찰 → 결정의 반복을 어떻게 설계하는가 (랄프 루프)
- 센서 — 린터, 테스트, 평가 결과를 어떻게 수집하는가
- 권한 & 가드레일 — 모델의 행동 범위를 어떻게 제어하는가
Terminal-Bench에서 Cursor가 이긴 이유? 1번(컨텍스트 엔지니어링)에서 Cursor의 Eager Loading이 그 벤치마크의 워크로드에 더 적합했기 때문입니다. CORE-Bench에서 Claude Code가 이긴 이유? 4번(컨트롤 루프)의 정교한 재시도와 2번(도구 인터페이스)의 풍부한 도구 세트가 복잡한 연구 재현 작업에 결정적이었기 때문입니다.
각 컴포넌트의 설계가 조금씩 다르면, 최종 결과에서는 그 차이가 곱셈으로 누적됩니다. 6개 컴포넌트에서 각각 20%씩 차이가 나면, 전체 성능은 1.26 ≈ 2.99배 — 거의 3배 차이가 됩니다. 스탠퍼드·칭화 연구의 “최대 6배”라는 수치가 비현실적이지 않은 이유입니다.
이 6대 컴포넌트 각각을 해부하는 것이 Phase 2(4~8화)의 할 일입니다. 지금은 “하니스가 효과가 있다”는 것을 증명하는 데 집중하고, “어떻게 만드느냐”는 다음 단계로 넘깁니다.
코드로 느끼는 하니스 효과
말과 표보다 코드가 설득력 있을 때가 있습니다. 아래는 “같은 모델, 다른 하니스”의 효과를 시뮬레이션하는 자체 실행 가능한 Python 스크립트입니다. 외부 API 없이 돌아가므로 직접 실행해 보시기 바랍니다.
"""harness_effect.py — 같은 '모델', 다른 하니스가 만드는 격차 시뮬레이션.
실행: python harness_effect.py
"""
import random
from dataclasses import dataclass, field
@dataclass
class HarnessConfig:
name: str
system_prompt: str = ""
context_files: list[str] = field(default_factory=list)
max_retries: int = 0
lint_check: bool = False
BARE = HarnessConfig(name="bare")
FULL = HarnessConfig(
name="full-harness",
system_prompt="Follow AGENTS.md conventions. Output valid Python only.",
context_files=["AGENTS.md", "src/utils.py"],
max_retries=2,
lint_check=True,
)
def simulate_llm(has_context: bool) -> tuple[str, int]:
"""모델 정확도 시뮬레이션: 컨텍스트 유무에 따라 성공률이 달라진다."""
tokens = random.randint(200, 500)
accuracy = 0.82 if has_context else 0.48
success = random.random() < accuracy
code = "def validate(email): return '@' in email" if success else "# err"
return code, tokens
def run(task: str, cfg: HarnessConfig) -> dict:
total_tokens = 0
for attempt in range(cfg.max_retries + 1):
code, tokens = simulate_llm(has_context=bool(cfg.context_files))
total_tokens += tokens
passes = (not cfg.lint_check) or code.startswith("def ")
if passes:
return {"harness": cfg.name, "tokens": total_tokens,
"attempts": attempt + 1, "pass": True}
return {"harness": cfg.name, "tokens": total_tokens,
"attempts": cfg.max_retries + 1, "pass": False}
if __name__ == "__main__":
random.seed(42)
TASK, TRIALS = "Write an email validator.", 100
for cfg in [BARE, FULL]:
results = [run(TASK, cfg) for _ in range(TRIALS)]
pass_rate = sum(r["pass"] for r in results) / TRIALS * 100
avg_tok = sum(r["tokens"] for r in results) // TRIALS
print(f"{cfg.name:>14} | pass: {pass_rate:5.1f}% | avg tokens: {avg_tok}")
실행 결과 예시:
bare | pass: 49.0% | avg tokens: 362
full-harness | pass: 97.0% | avg tokens: 498
핵심 관찰:
- bare 하니스: 성공률 약 49%. 절반이 실패합니다. lint 체크도 없으니 실패한 줄도 모릅니다.
- full-harness: 성공률 97%. 컨텍스트 파일이 모델의 기본 정확도를 끌어올리고(0.48 → 0.82), 재시도 루프가 남은 실패를 잡아냅니다(0.82 → 0.97). 토큰은 37% 더 쓰지만, 성공률은 2배입니다.
토큰 37% 추가 투자로 성공률 2배. 이것이 하니스 효과의 ROI입니다. 실제 프로덕션에서 실패한 응답을 사람이 수정하는 비용까지 포함하면, 하니스 투자의 ROI는 이보다 훨씬 높아집니다.
실패담 코너 — 모델만 바꾸면 될 줄 알았다
익명화된 실화입니다. 음성 인식(STT) 파이프라인 프로젝트에서, 전사(transcription) 후 LLM으로 교정하는 단계가 있었습니다. “교정 정확도가 아쉽다”는 피드백에, 팀은 가장 쉬운 해법을 골랐습니다. 모델을 최신 버전으로 업그레이드하는 것.
결과는 참담했습니다. 정확도가 오히려 3% 떨어졌습니다. 원인을 추적하는 데 이틀이 걸렸는데, 범인은 모델이 아니었습니다. 새 모델의 출력 포맷이 미묘하게 달라져서, 후처리 파서가 특정 패턴을 누락한 것이었습니다. 교정 프롬프트에는 “JSON으로 응답해”라고만 써 있었고, JSON 스키마 검증이나 출력 파싱 폴백이 없었습니다.
하니스(출력 파싱 + 검증 + 폴백)가 없으니, 모델 업그레이드가 성능 하락으로 이어진 겁니다. 모델은 더 좋아졌지만, 그 모델을 감싸는 파이프라인은 이전 모델의 버릇에 맞춰져 있었으니까요. 파서를 고치고 스키마 검증을 추가한 뒤에야 정확도가 원래 수준을 넘어섰습니다.
이 경험 이후 팀의 우선순위가 바뀌었습니다. “어떤 모델을 쓸까”보다 “모델 교체에 견디는 하니스를 먼저 만들자”가 기본 원칙이 되었습니다.
모델 리더보드의 함정
지금까지의 데이터를 종합하면, AI 업계의 가장 흔한 함정이 보입니다. 모델 리더보드 집착입니다.
새 모델이 나올 때마다 “MMLU 3점 올랐다”, “HumanEval 92% 달성”같은 헤드라인이 쏟아집니다. 그리고 팀들은 모델을 바꾸는 데 서둘러 시간을 쓰죠. 하지만 이번 글에서 봤듯이:
- 모델 한 세대 업그레이드의 전형적 벤치마크 향상: 5~12점
- 하니스 교체의 전형적 벤치마크 향상: 16~36점
- 하니스 설계 최적화의 최대 효과: 6배
모델을 바꾸는 것은 CPU를 교체하는 것입니다. OS(하니스)가 메모리 누수를 일으키고 있는데 CPU를 업그레이드해봤자, 체감 성능은 거의 오르지 않습니다. OS를 먼저 고쳐야 합니다.
AI 에이전트 프로젝트의 약 88%가 프로덕션에 도달하지 못한다는 2026년 추정치가 있습니다. 이 실패의 상당 부분이 “모델은 훌륭한데 하니스가 부실해서” 발생한다는 것이, 이 시리즈의 핵심 주장입니다. 3화에서 이 88%의 실패를 정면으로 해부합니다.
실무 체크리스트: 하니스 효과 진단
오늘의 데이터를 실무에 적용하고 싶다면, 다음 다섯 가지를 자문해 보세요.
- 같은 프롬프트를 다른 도구에서 돌려봤는가? — Claude Code, Cursor, Copilot 등에서 같은 작업을 시켜보면 하니스 차이를 체감할 수 있습니다.
- 토큰 사용량을 측정하고 있는가? — 정확도만 보지 말고 토큰/비용도 함께 트래킹하세요.
- 실패한 응답을 분석하고 있는가? — 모델의 지식 부족인가, 컨텍스트 부족인가, 출력 파싱 실패인가? 원인에 따라 처방이 다릅니다.
- 재시도 루프가 있는가? — 위 코드에서 봤듯이, 재시도 한 번이 성공률을 극적으로 끌어올립니다.
- 모델 교체를 고려하기 전에 하니스를 먼저 점검했는가? — 이 질문을 습관화하는 것만으로 엔지니어링 시간의 60% 이상을 절약할 수 있습니다.
이번 글의 한 줄 요약
같은 모델이 하니스에 따라 16점·6배·5.5배 차이를 만든다 — 모델 교체보다 하니스 설계가 먼저다.
다음 회차 예고
3화: 에이전트 프로젝트 88%가 실패하는 진짜 이유
하니스가 효과적이라는 건 알겠습니다. 그런데 왜 대부분의 팀은 하니스 없이 에이전트를 만들려 할까요? AI 에이전트 프로젝트의 88%가 프로덕션에 도달하지 못하는 구조적 원인을 분석하고, “하니스 부재”가 그 실패 방정식의 어디에 위치하는지 짚어봅니다. Phase 1(WHY)의 마지막 퍼즐입니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 1화 (다음 차수는 아직 게시되지 않았습니다)
[…] AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 (총 12화 중 3화)◀ 이전 2화 (다음 차수는 아직 게시되지 않았습니다) 카테고리: IT기술 […]