이 글은 「AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복」 시리즈의 4/12회입니다. 1~3회(WHY 단계)를 아직 읽지 않았다면, 이번 글만으로도 충분히 이해할 수 있지만 시리즈 순서대로 읽으면 맥락이 더 선명해집니다.
WHY에서 WHAT으로 — 하니스의 부품을 열어 보자
1회에서 우리는 에이전트 하니스(Agent Harness)가 무엇인지 정의했습니다. LLM이 CPU라면 하니스는 OS이고, 그 OS가 I/O·메모리·스케줄링을 어떻게 처리하느냐에 따라 같은 CPU의 체감 성능이 완전히 달라진다는 비유를 세웠죠. 2회에서는 같은 모델이 하니스만 바꿔 Terminal-Bench에서 16점 차이가 난다는 벤치마크를 확인했고, 3회에서는 AI 에이전트 프로젝트의 약 88%가 프로덕션에 도달하지 못하는 근본 원인이 모델이 아니라 모델을 둘러싼 운영 레이어에 있다는 결론에 도달했습니다.
이제 Phase 2, WHAT 단계입니다. 에이전트 하니스를 구성하는 6대 핵심 컴포넌트를 하나씩 해부하는 5회에 걸친 여정이 시작됩니다. 4~8회에서 다룰 컴포넌트는 다음과 같습니다.
- 4회 (이번 글): 컨텍스트 엔지니어링 — 토큰 예산, AGENTS.md, 프로그레시브 로딩
- 5회: 도구 인터페이스 & MCP(Model Context Protocol)
- 6회: 메모리 아키텍처 — Working · Session · Long-term
- 7회: 컨트롤 루프 — Agent Loop, 랄프 루프(Ralph Loop), 컨텍스트 불안(Context Anxiety)
- 8회: 센서(Sensors)와 권한 — 가드레일, 에러 캡처, 결과 포맷팅
그중 첫 번째 주인공은 컨텍스트 엔지니어링(Context Engineering)입니다. 하니스의 여섯 부품 가운데 이것을 가장 먼저 다루는 이유는 단순합니다. 나머지 다섯 컴포넌트가 모두 컨텍스트 위에서 작동하기 때문입니다. 도구 결과도 컨텍스트에 실리고, 메모리도 컨텍스트로 주입되며, 컨트롤 루프의 판단 기준도 컨텍스트 안의 정보입니다. 컨텍스트가 무너지면 나머지 부품은 아무리 정교해도 의미가 없습니다.
정의: 컨텍스트 엔지니어링이란 무엇인가
컨텍스트 엔지니어링은 “모델의 컨텍스트 윈도우에 들어갈 정보를 선택·구조화·압축·갱신하는 체계적 활동”을 뜻합니다. ‘프롬프트 엔지니어링(Prompt Engineering)’이라는 용어에 익숙한 분이 많을 텐데, 2025년부터 AI 엔지니어링 커뮤니티에서는 이 용어가 실상을 충분히 반영하지 못한다는 공감대가 형성됐습니다.
프롬프트 엔지니어링이 “모델에게 어떤 말을 하느냐”에 초점을 맞춘다면, 컨텍스트 엔지니어링은 “모델이 추론을 시작하는 시점에 어떤 정보가, 어떤 순서로, 얼마나 존재하느냐”를 설계합니다. 프롬프트는 컨텍스트의 일부일 뿐이고, 실제 에이전트 시스템에서는 대화 이력, 도구 호출 결과, 파일 내용, 메모리 요약, 시스템 지침 등 수많은 정보 소스가 하나의 컨텍스트 윈도우 안에서 경합합니다.
이 프레이밍 전환을 가장 명확하게 표현한 인물 중 하나가 Andrej Karpathy입니다. 그는 2025년 초 “the hottest new programming language is English”라는 자신의 유명한 문구를 수정하며 이렇게 말했습니다. “I would now say the hottest new programming language is context.” 프롬프트를 잘 쓰는 것만으로는 부족하고, 모델에게 전달되는 전체 컨텍스트를 설계하는 능력이 핵심이라는 선언이었습니다.
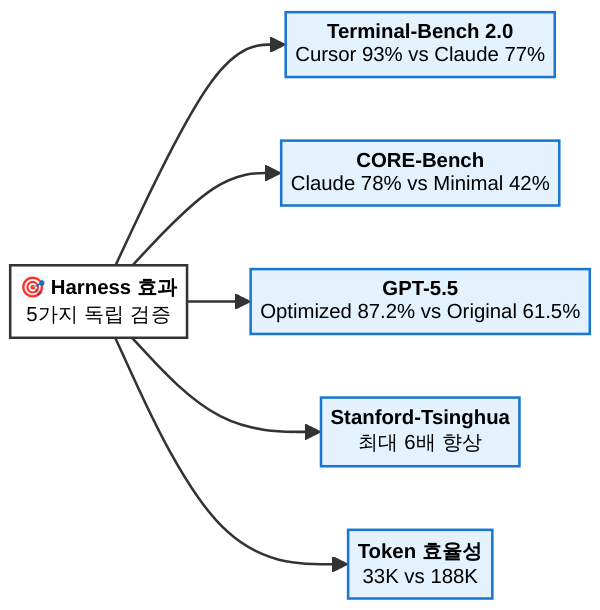
2026년 2월, Mitchell Hashimoto가 에이전트 하니스 프레임워크를 공식화하면서 컨텍스트 엔지니어링을 하니스의 1번 컴포넌트로 배치한 것은 이 흐름의 자연스러운 귀결입니다. 그의 분석에 따르면, 하니스가 동일 모델의 성능을 최대 6배까지 끌어올리는 메커니즘의 절반 이상이 컨텍스트 관리에서 비롯됩니다.
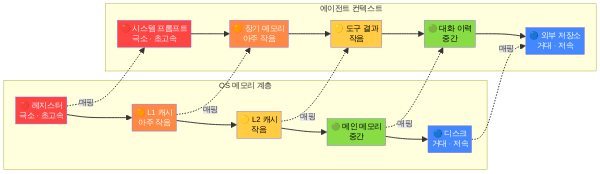
컨텍스트 윈도우 = RAM — OS 비유의 심화
이 시리즈에서 일관되게 사용하는 비유를 다시 꺼내 봅시다.
- LLM = CPU — 연산(추론)을 수행하는 엔진
- 컨텍스트 윈도우 = RAM — CPU가 한 번에 참조할 수 있는 작업 메모리
- 에이전트 하니스 = OS — RAM에 무엇을 올리고, 언제 내리고, 어떻게 구조화할지를 결정하는 운영 체제
이 비유를 더 깊이 들어가면 놀라울 정도로 대응이 정확합니다.
페이지 폴트(Page Fault) → 환각(Hallucination). OS가 RAM에 없는 데이터를 참조하려 하면 페이지 폴트가 발생합니다. LLM에서 컨텍스트에 없는 정보를 참조하려 하면? 모델은 “모른다”고 말하는 대신, 그럴듯한 내용을 지어냅니다 — 환각입니다. RAM에 올바른 데이터가 있었다면 일어나지 않았을 오류입니다.
메모리 누수(Memory Leak) → 컨텍스트 부패(Context Rot). 프로그램이 더 이상 필요 없는 메모리를 해제하지 않으면 메모리 누수가 발생하고, 결국 가용 RAM이 고갈됩니다. 에이전트 시스템에서 오래된 대화 이력, 실패한 도구 호출 결과, 폐기된 계획 등이 컨텍스트에 누적되면 동일한 현상이 벌어집니다. 정작 필요한 최신 정보가 들어갈 자리가 없어지는 것이죠. 이것을 컨텍스트 부패(Context Rot)라고 부릅니다.
OOM(Out of Memory) → 토큰 초과(Token Overflow). RAM이 가득 차면 OS는 프로세스를 죽이거나 스왑을 쓰는 극단적 조치를 취합니다. 컨텍스트 윈도우가 가득 차면 API는 에러를 반환하거나, 하니스가 강제로 오래된 내용을 잘라냅니다. 어떤 내용이 잘릴지를 하니스가 의도적으로 제어하지 않으면, 중요한 시스템 프롬프트나 핵심 지침이 날아갈 수도 있습니다.
가상 메모리(Virtual Memory) → 프로그레시브 로딩. 현대 OS는 물리 RAM보다 훨씬 큰 주소 공간을 프로그램에 제공합니다. 실제로는 필요한 페이지만 RAM에 올리고 나머지는 디스크에 둡니다. 에이전트 하니스의 프로그레시브 로딩도 같은 원리입니다 — 전체 코드베이스를 한꺼번에 컨텍스트에 올리지 않고, 필요한 파일만 그때그때 읽어 들입니다.
이 비유가 단순한 수사가 아니라 설계 원칙이 되어야 한다는 것이 이번 글의 핵심입니다. OS가 메모리를 관리하듯, 하니스는 컨텍스트를 관리해야 합니다. 그리고 그 관리 수준의 차이가 곧 성능 차이입니다.
이것이 없으면 무엇이 깨지는가 — 컨텍스트 부패의 4가지 증상
컨텍스트 엔지니어링이 미흡하거나 부재할 때, 에이전트 시스템에서는 다음과 같은 구체적인 증상이 나타납니다.
증상 1: 토큰 폭식 — 5.5배의 낭비
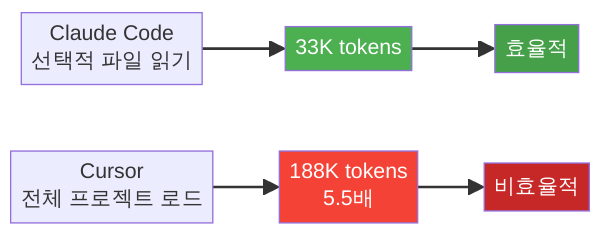
가장 즉각적이고 측정 가능한 증상은 토큰 낭비입니다. 2회에서 인용한 Matt Mayer의 독립 벤치마크를 다시 봅시다. 동일한 코딩 작업을 수행할 때:
- Claude Code (정교한 컨텍스트 엔지니어링): 평균 33K 토큰
- Cursor (상대적으로 단순한 컨텍스트 관리): 평균 188K 토큰
5.5배 차이. 같은 모델(Claude Opus)이 같은 작업을 하는데, 하니스가 컨텍스트에 무엇을 얼마나 넣느냐의 차이만으로 토큰 소비량이 이만큼 벌어집니다. 이것은 단순한 비용 문제가 아닙니다. 토큰을 많이 쓴다는 것은 모델이 불필요한 정보를 처리하느라 연산 자원을 소모한다는 뜻이고, 그만큼 핵심 작업에 대한 집중도가 떨어진다는 의미입니다.
증상 2: 지시 망각(Instruction Amnesia)
긴 대화나 복잡한 멀티스텝 작업에서 모델이 초기에 받은 지시를 “잊어버리는” 현상입니다. 실제로 모델이 기억력을 상실한 것이 아니라, 중간에 쌓인 대화 이력과 도구 결과가 시스템 프롬프트의 영향력을 희석시킨 것입니다. 컨텍스트 윈도우 안에서 시스템 프롬프트가 차지하는 비중이 작아질수록, 모델은 그 지시를 덜 따르게 됩니다.
이것은 RAM에서 중요한 시스템 프로세스가 다른 프로세스에 밀려 스왑 아웃되는 것과 같습니다. OS의 메모리 관리자가 제대로 작동한다면 커널 영역의 데이터가 밀려나는 일은 없겠죠. 마찬가지로 하니스의 컨텍스트 엔지니어링이 제대로 작동한다면, 시스템 프롬프트의 위치와 영향력을 보호해야 합니다.
증상 3: 컨텍스트 부패(Context Rot)
앞서 비유에서 설명한 메모리 누수의 LLM 버전입니다. 에이전트가 여러 단계를 거치면서, 실패한 시도의 흔적·중간 계획의 잔해·이미 수정된 코드의 이전 버전 등이 컨텍스트에 남아 있으면, 모델은 최신 상태와 과거 상태를 혼동합니다.
구체적인 예시: 코딩 에이전트가 파일 A를 수정한 뒤, 그 수정이 실패해서 파일 B로 방향을 바꿨다고 합시다. 파일 A의 수정 내역과 실패 로그가 여전히 컨텍스트에 남아 있으면, 이후 단계에서 에이전트는 파일 A의 (이미 롤백된) 수정을 기정사실로 참조하여 논리적으로 앞뒤가 맞지 않는 코드를 생성할 수 있습니다. 이것이 컨텍스트 부패의 전형적인 발현입니다.
증상 4: 컨텍스트 불안(Context Anxiety)
컨텍스트 불안(Context Anxiety)이라는 용어는 에이전트가 컨텍스트 윈도우의 한계에 가까워졌을 때 보이는 행동 패턴을 지칭합니다. 토큰이 부족해지면 에이전트는 — 마치 시험 시간이 임박한 학생처럼 — 지름길을 택합니다. 설명을 줄이고, 단계를 건너뛰고, “이전에 논의한 대로”라며 실제로는 논의하지 않은 내용을 참조합니다.
이 네 가지 증상은 독립적이 아니라 연쇄적으로 발생합니다. 토큰 폭식(증상 1)이 컨텍스트 부패(증상 3)를 촉진하고, 부패된 컨텍스트가 지시 망각(증상 2)을 악화시키며, 결국 윈도우가 가득 차면서 컨텍스트 불안(증상 4)이 발현되어 작업 품질이 급격히 하락합니다.

숫자로 증명하는 컨텍스트 엔지니어링 — 벤치마크 데이터
컨텍스트 엔지니어링의 영향을 정량화한 핵심 데이터를 정리합니다. 이 수치들은 2회에서 소개한 벤치마크의 연장선이지만, 이번에는 “왜 차이가 나는가”의 메커니즘 관점에서 다시 읽습니다.
| 측정 항목 | Claude Code (정교한 컨텍스트) | Cursor (기본 컨텍스트) | 격차 |
|---|---|---|---|
| 동일 작업 평균 토큰 사용 | 33K | 188K | 5.5배 |
| 달러당 정확도 (복잡 멀티파일) | 8.5점 | 6.2점 | +37% |
| 달러당 정확도 (단순 유틸리티) | 31점 | 42점 | Cursor 우세 |
| Terminal-Bench 2.0 점수 | 77점 (Claude Code) | 93점 (Cursor) | Cursor 우세* |
* Terminal-Bench 2.0에서 Cursor가 더 높은 점수를 기록한 이유 또한 컨텍스트 엔지니어링과 관련이 있습니다. Cursor는 IDE 전체의 파일 트리, 열린 탭, 커서 위치 등 풍부한 IDE 컨텍스트를 활용합니다. 이 컨텍스트가 해당 벤치마크의 작업 유형에는 유리하게 작용한 것이죠. 그 대가가 188K 토큰이라는 높은 비용인 셈입니다.
여기서 주목할 점은 두 가지입니다.
첫째, 컨텍스트 전략은 트레이드오프입니다. Claude Code는 토큰 효율성에서 압도적이지만, 단순 유틸리티 작업에서는 Cursor의 “풍부한 컨텍스트” 전략이 오히려 낫습니다. 이것은 컨텍스트 엔지니어링에 “정답”이 하나가 아니라, 작업의 성격에 맞는 최적 전략이 다르다는 것을 보여줍니다.
둘째, 비용 대비 성능은 일관되게 컨텍스트 효율 쪽이 우세합니다. 복잡한 멀티파일 작업 — 즉 프로덕션에서 실제로 마주하는 유형의 작업 — 에서 Claude Code의 달러당 정확도가 37% 높다는 것은 같은 비용으로 더 나은 결과를 얻거나, 같은 결과를 더 적은 비용으로 얻을 수 있다는 의미입니다.
CORE-Bench 데이터도 같은 방향을 가리킵니다.
| 하니스 수준 | Claude Opus 점수 | 핵심 차이 |
|---|---|---|
| 최소 스캐폴드 (프롬프트만) | 42% | 컨텍스트 관리 없음 |
| Claude Code 전체 하니스 | 78% | 토큰 예산 + 프로그레시브 로딩 + 압축 |
같은 Claude Opus 모델이 하니스 없이 42%, 풀 하니스로 78% — 36%포인트 차이의 가장 큰 단일 요인이 컨텍스트 엔지니어링입니다. 스탠퍼드·칭화 공동 연구에서 보고한 “동일 모델, 하니스 설계에 따라 최대 6배 성능 차이” 역시 컨텍스트 관리가 지배적 변수로 분석됩니다.
GPT-5.5에서도 같은 패턴이 관찰됩니다. 하니스만 교체하여 기능성 점수를 61.5%에서 87.2%로 끌어올린 사례에서, 연구팀이 가장 먼저 바꾼 것이 컨텍스트 전략이었습니다.
패턴 1 — 토큰 예산(Token Budget) 전략
이제 문제를 진단했으니, 해법을 봅시다. 컨텍스트 엔지니어링의 검증된 패턴 세 가지를 소개합니다.
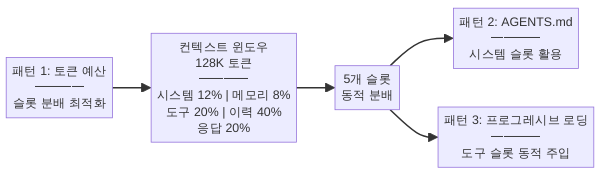
첫 번째 패턴은 토큰 예산(Token Budget)입니다. 이것은 가장 기초적이면서도 가장 효과적인 기법입니다.
원리는 단순합니다. 컨텍스트 윈도우의 총 토큰 수를 목적별 슬롯(slot)으로 사전 분배하고, 각 슬롯이 배정된 예산을 초과하지 않도록 강제합니다. OS의 메모리 관리자가 프로세스별 메모리 한도를 설정하는 것과 정확히 같은 개념입니다.
일반적인 슬롯 구성은 다음과 같습니다.
| 슬롯 | 비율 | 용도 | 관리 전략 |
|---|---|---|---|
| 시스템 프롬프트 | 10~15% | 역할 정의, 규칙, 금지사항 | 고정 — 항상 전량 포함 |
| 장기 메모리 | 5~10% | 이전 세션 요약, 사용자 선호도 | 요약 압축 후 주입 |
| 도구 결과 | 15~25% | 파일 내용, API 응답, 검색 결과 | 최신 N개만 유지, 나머지 요약 |
| 대화 이력 | 30~40% | 사용자-에이전트 대화 턴 | FIFO(선입선출) — 오래된 턴부터 제거 |
| 응답 예약 | 15~25% | 모델이 생성할 응답 공간 | 고정 — 빈 공간으로 확보 |
핵심은 “응답 예약” 슬롯을 반드시 확보하는 것입니다. 초보적인 하니스 구현에서 가장 흔한 실수가 컨텍스트를 99%까지 채우고 모델에게 응답할 공간을 1%만 남기는 것입니다. 이렇게 하면 모델은 할 말을 다 하지 못하고 중간에 잘리거나, 극도로 압축된(그래서 부정확한) 응답을 생성합니다.
토큰 예산의 비율은 에이전트의 성격에 따라 조정합니다. 코딩 에이전트처럼 도구(파일 읽기) 결과가 중요한 경우 도구 슬롯을 25%까지 올리고 대화 이력을 줄입니다. 대화형 어시스턴트라면 대화 이력에 40%를 배정하고 도구 슬롯을 최소화합니다.
Claude Code의 실제 구현은 이보다 훨씬 정교합니다. Anthropic이 공개한 엔지니어링 인사이트에 따르면, Claude Code는 대화가 길어지면 자동으로 이전 대화를 요약(compaction)합니다. 전체 이력을 잘라내는 것이 아니라, 중간 대화를 요약본으로 치환하여 핵심 정보는 보존하면서 토큰을 절약하는 방식입니다. 이것이 33K라는 놀라운 효율의 비밀 중 하나입니다.
예산 초과 시 전략: FIFO vs 중요도 기반
특정 슬롯이 예산을 초과했을 때 어떤 항목을 제거할 것인가? 두 가지 전략이 있습니다.
FIFO(First In, First Out)는 가장 오래된 항목부터 제거합니다. 대화 이력에 적합합니다 — 대부분의 경우 최신 대화가 과거 대화보다 관련성이 높기 때문입니다. 구현이 단순하고 예측 가능하다는 장점이 있습니다.
중요도 기반(Priority-Based)은 각 항목에 가중치를 부여하고, 낮은 가중치부터 제거합니다. 시스템 프롬프트의 핵심 지시에 높은 가중치를, 일상적인 도구 호출 결과에 낮은 가중치를 주는 식입니다. 구현 복잡도가 올라가지만, 중요한 정보가 밀려나는 것을 방지할 수 있습니다.
실무에서는 하이브리드가 가장 효과적입니다. 시스템 프롬프트와 장기 메모리는 중요도 기반으로 보호하고, 대화 이력과 도구 결과는 FIFO로 관리합니다.
패턴 2 — AGENTS.md와 구조화된 컨텍스트 주입
두 번째 패턴은 구조화된 컨텍스트 주입(Structured Context Injection)입니다. 가장 대표적인 구현이 AGENTS.md(또는 CLAUDE.md, .cursorrules 등) 같은 프로젝트 루트 마크다운 파일입니다.
이 패턴의 핵심 아이디어는 이렇습니다. 에이전트가 매 대화마다 “이 프로젝트는 뭘 하는 건지”, “코딩 규칙은 뭔지”, “어떤 라이브러리를 쓰는지”를 처음부터 파악하느라 토큰을 쓰는 대신, 사전에 구조화된 문서를 컨텍스트에 자동 주입하는 것입니다.
CLAUDE.md의 구조 — 실전 예시
Anthropic이 Claude Code에 도입한 CLAUDE.md 패턴은 이미 업계 표준이 되어 가고 있습니다. 효과적인 CLAUDE.md는 다음과 같은 계층 구조를 갖습니다.
- 프로젝트 소개 (1~2줄): 이 저장소가 무엇인가
- 절대 금지 사항: 모델이 절대 해서는 안 되는 행동 목록
- 기술 스택: 사용 중인 언어, 프레임워크, 도구
- 디렉토리 구조: 프로젝트 레이아웃 (모델이 파일을 찾을 때 전체 탐색 대신 이 맵을 참조)
- 코딩 규칙: 네이밍 컨벤션, 테스트 전략, 커밋 메시지 형식
- 개발 워크플로우: 브랜치 모델, PR 절차, CI 체크 항목
이 구조가 컨텍스트 엔지니어링의 관점에서 왜 강력한지 살펴봅시다.
토큰 대비 정보 밀도가 극도로 높습니다. CLAUDE.md 하나가 보통 1,000~3,000 토큰 범위인데, 이 안에 프로젝트의 핵심 맥락이 모두 담깁니다. 이 파일이 없다면 에이전트는 동일한 정보를 얻기 위해 파일 10개를 열어보고, README를 읽고, package.json을 확인하는 등 수만 토큰을 소비해야 합니다.
일관성을 강제합니다. 대화가 길어져도, 세션이 바뀌어도, CLAUDE.md는 항상 같은 위치에서 같은 내용을 주입합니다. 이것은 앞서 말한 “지시 망각” 증상을 구조적으로 예방합니다.
점진적 구체화가 가능합니다. 프로젝트 루트의 CLAUDE.md는 전체 프로젝트 맥락을, 하위 디렉토리의 CLAUDE.md는 해당 모듈의 구체적 규칙을 담을 수 있습니다. Claude Code는 작업 중인 파일의 경로를 기반으로 관련 CLAUDE.md를 자동 탐색합니다.
“컨텍스트 메뉴” — 너무 많은 정보의 역설
주의할 점이 있습니다. AGENTS.md가 너무 길어지면 오히려 역효과가 납니다. 시스템 프롬프트 슬롯의 예산을 초과하면 다른 슬롯을 잠식하고, 모델이 핵심 지시를 문서의 바다에서 놓칠 수 있습니다.
Anthropic의 엔지니어링 가이드 “Building effective agents”(2024)에서는 이 문제를 명시적으로 경고합니다. “시스템 프롬프트에 담는 규칙의 수가 늘어날수록, 개별 규칙의 준수율이 하락한다”는 것이 반복 실험을 통해 확인된 패턴이라고 합니다. 그들의 권장은 “가장 중요한 규칙 5~7개에 집중하고, 나머지는 도구 호출이나 별도 파일로 분리하라”는 것입니다.
이것은 OS의 “워킹 세트(Working Set)” 개념과 정확히 대응합니다. 프로세스가 실제로 자주 참조하는 메모리 페이지만 RAM에 유지하고 나머지는 가상 메모리로 내리듯, 에이전트에게 항상 노출할 핵심 규칙(워킹 세트)과 필요할 때만 불러올 부가 정보를 분리해야 합니다.
패턴 3 — 프로그레시브 로딩과 가상 파일시스템
세 번째 패턴은 프로그레시브 로딩(Progressive Loading)입니다. OS가 가상 메모리를 통해 물리 RAM보다 큰 데이터를 다루듯, 하니스가 컨텍스트 윈도우보다 큰 코드베이스나 문서를 다루는 기법입니다.
Eager vs Lazy — 로딩 전략의 스펙트럼
Eager Loading(즉시 로딩)은 에이전트가 작업을 시작할 때 관련될 가능성이 있는 모든 정보를 한꺼번에 컨텍스트에 넣는 전략입니다. 단순한 작업에서는 효과적이지만, 프로젝트 규모가 커지면 토큰 폭식(증상 1)을 일으킵니다. Cursor가 IDE의 열린 탭, 파일 트리, 심볼 인덱스를 모두 컨텍스트에 포함시키는 것이 이 전략의 극단적 예시이며, 188K 토큰이라는 비용의 원인입니다.
Lazy Loading(지연 로딩)은 에이전트가 실제로 필요로 하는 시점에 비로소 정보를 가져오는 전략입니다. Claude Code가 파일을 읽을 때 Read 도구를 호출하여 그때그때 내용을 가져오는 것이 대표적입니다. 토큰 효율은 극대화되지만, “필요하다”는 판단을 모델에게 맡기므로 중요한 파일을 놓칠 위험이 있습니다.
최적은 그 사이입니다. 실무에서 검증된 접근은 다음과 같습니다.
- 레벨 0 (항상 포함): AGENTS.md, 프로젝트 구조 맵, 핵심 설정 파일 — 시스템 프롬프트 슬롯에 포함
- 레벨 1 (작업 시작 시 자동 로딩): 작업 대상 파일과 그 직접 의존성 — 도구 슬롯에 사전 배치
- 레벨 2 (요청 시 로딩): 관련될 수 있는 파일 — 모델이 도구를 호출하여 읽기
- 레벨 3 (검색으로 발견): 존재조차 모르는 파일 — Grep/Glob 도구로 탐색 후 로딩
이 4단계 구조가 바로 OS의 메모리 계층(레지스터 → L1 캐시 → L2 캐시 → 메인 메모리 → 디스크)과 대응합니다. 자주 쓰는 것은 가까이, 드물게 쓰는 것은 멀리 두되, 필요하면 언제든 가져올 수 있는 경로를 확보하는 것이 핵심입니다.
가상 파일시스템 패턴
프로그레시브 로딩의 고급 형태가 가상 파일시스템(Virtual Filesystem) 패턴입니다. 이것은 에이전트에게 실제 파일시스템의 전체 구조를 “목차” 형태로 보여주되, 각 파일의 실제 내용은 에이전트가 명시적으로 요청할 때만 로딩하는 방식입니다.
구체적으로:
- 프로젝트의 디렉토리 트리를 컨텍스트에 포함합니다 (보통 100~500 토큰 수준).
- 각 파일에는 한 줄짜리 요약(docstring, 첫 번째 주석 등)을 붙입니다.
- 에이전트는 이 “목차”를 보고 어떤 파일을 읽을지 결정합니다.
- 파일을 읽으면 해당 내용이 도구 슬롯에 로딩됩니다.
이 패턴의 토큰 효율은 극적입니다. 1,000개 파일로 구성된 프로젝트에서 모든 파일을 로딩하면 수백만 토큰이 필요하지만, 가상 파일시스템 목차는 1,000~2,000 토큰이면 충분합니다. 에이전트는 이 목차를 기반으로 실제로 필요한 5~10개 파일만 읽으므로, 총 토큰 사용량은 수만 토큰 수준에 머뭅니다.
Claude Code가 Glob, Grep, Read 같은 도구를 제공하는 이유가 여기에 있습니다. 이 도구들은 단순한 편의 기능이 아니라, 프로그레시브 로딩과 가상 파일시스템 패턴을 구현하기 위한 핵심 인프라입니다.
코드로 만드는 토큰 예산 관리자
세 가지 패턴 중 토큰 예산 전략을 코드로 구현해 봅시다. 다음은 Python으로 작성한 40줄짜리 미니 컨텍스트 버짓 매니저입니다. 에이전트 하니스의 핵심 모듈 중 하나를 최소 형태로 보여주는 코드이며, 실제로 실행하여 동작을 확인할 수 있습니다.
"""context_budget.py — 에이전트 하니스의 토큰 예산 관리자 (미니 구현)"""
from __future__ import annotations
import tiktoken
class ContextBudget:
"""128K 컨텍스트 윈도우를 슬롯별로 분배한다."""
SLOTS = {
"system": 0.12, # 시스템 프롬프트 12 %
"memory": 0.08, # 장기 메모리 8 %
"tools": 0.20, # 도구 결과 20 %
"history": 0.40, # 대화 이력 40 %
"output": 0.20, # 응답 예약 20 %
}
def __init__(self, max_tokens: int = 128_000) -> None:
self.max = max_tokens
self.enc = tiktoken.encoding_for_model("gpt-4o")
def count(self, text: str) -> int:
return len(self.enc.encode(text))
def budget(self, slot: str) -> int:
return int(self.max * self.SLOTS[slot])
def fit_newest(self, slot: str, items: list[str]) -> list[str]:
"""예산 안에서 최신 항목부터 역순으로 채운다 (FIFO 드롭)."""
limit = self.budget(slot)
kept: list[str] = []
used = 0
for item in reversed(items):
cost = self.count(item)
if used + cost > limit:
break
kept.append(item)
used += cost
return list(reversed(kept))
# ── 데모 ──────────────────────────────────────────────
if __name__ == "__main__":
cb = ContextBudget(max_tokens=128_000)
# 50턴 분량의 가상 대화 이력 생성
history = [f"[turn {i}] " + "대화 내용입니다. " * 80 for i in range(50)]
fitted = cb.fit_newest("history", history)
print(f"전체 턴 수 : {len(history)}")
print(f"선택된 턴 수: {len(fitted)}")
for slot, ratio in cb.SLOTS.items():
print(f" {slot:10s}: {cb.budget(slot):>7,} 토큰 ({ratio:.0%})")
이 코드가 보여주는 핵심 원리:
- 슬롯별 예산 분배:
SLOTS딕셔너리가 컨텍스트 윈도우를 5개 영역으로 나눕니다. 합계 100%가 되어야 합니다. - FIFO 드롭:
fit_newest메서드는 최신 항목부터 역순으로 예산에 채웁니다. 예산을 초과하면 가장 오래된 항목이 자연스럽게 탈락합니다. - 토큰 카운팅:
tiktoken라이브러리로 정확한 토큰 수를 계산합니다. 문자 수가 아니라 실제 토큰 수 기준입니다. - 응답 예약:
output슬롯(20%)은 데이터를 넣지 않고 비워둡니다. 이 공간이 모델의 응답 영역입니다.
실행하면 다음과 비슷한 출력을 볼 수 있습니다 (pip install tiktoken 필요).
전체 턴 수 : 50
선택된 턴 수: 23
system : 15,360 토큰 (12%)
memory : 10,240 토큰 (8%)
tools : 25,600 토큰 (20%)
history : 51,200 토큰 (40%)
output : 25,600 토큰 (20%)
50개 턴 중 23개만 선택됐습니다. 나머지 27개 턴은 예산 초과로 탈락한 것이죠. 단순한 코드지만, 이것이 바로 Claude Code 같은 정교한 하니스가 내부적으로 수행하는 작업의 핵심 골격입니다. 실제 프로덕션 하니스에서는 여기에 중요도 가중치, 요약 압축, 슬롯 간 동적 재분배 등이 추가됩니다.
1차 자료 심층 인용 — Anthropic의 컨텍스트 관리 원칙
Anthropic이 2024년 말에 공개한 엔지니어링 가이드 “Building effective agents”는 에이전트 시스템의 컨텍스트 관리에 대해 업계에서 가장 체계적인 지침을 제공합니다. 이 문서에서 컨텍스트 엔지니어링과 직접 관련된 핵심 원칙 세 가지를 발췌합니다.
원칙 1: “Keep the agent’s context focused.” — 에이전트의 컨텍스트를 집중시키라. Anthropic은 도구 결과가 누적되면서 컨텍스트가 비대해지는 것을 에이전트 시스템의 가장 흔한 성능 저하 원인으로 꼽습니다. 특히 도구 호출이 예상보다 긴 결과를 반환했을 때, 그 결과를 그대로 컨텍스트에 넣는 것이 아니라 요약하거나 필요한 부분만 추출해야 한다고 강조합니다.
원칙 2: “Don’t put everything in the system prompt.” — 시스템 프롬프트에 모든 것을 넣지 마라. 앞서 패턴 2에서 언급한 내용의 근거입니다. 규칙의 수가 늘어나면 개별 규칙의 준수율이 떨어집니다. 핵심 규칙은 시스템 프롬프트에, 상세 규칙은 필요할 때 도구로 불러오라는 것이 그들의 권장입니다.
원칙 3: “Plan for long conversations.” — 긴 대화를 대비하라. 에이전트가 20~30턴 이상의 긴 작업을 수행할 때, 컨텍스트 관리 없이는 성능이 급격히 저하됩니다. Anthropic이 Claude Code에 구현한 자동 대화 요약(automatic conversation compaction)은 이 원칙의 직접적 구현입니다. 대화 중간 지점에서 이전 내용을 요약본으로 치환하여, 핵심 결정과 현재 상태만 유지하는 방식입니다.
이 세 원칙은 독립적이 아니라 하나의 설계 철학을 구성합니다. “컨텍스트 윈도우는 한정된 자원이다. 이 자원을 최대한 효율적으로, 최대한 관련성 높은 정보로 채워야 한다.” — 이것이 컨텍스트 엔지니어링의 본질이며, 이번 글의 제목이 “토큰은 한정 자원이다”인 이유입니다.
추론 샌드위치(Reasoning Sandwich) — 컨텍스트 배치의 기술
패턴을 하나 더 짚고 넘어갑시다. 컨텍스트 안에 정보를 얼마나 넣느냐도 중요하지만, 어떤 순서로 배치하느냐도 성능에 영향을 미칩니다.
추론 샌드위치(Reasoning Sandwich)는 이 배치 전략을 표현하는 용어입니다. 핵심 지시를 컨텍스트의 맨 앞과 맨 뒤에 동시에 배치하고, 그 사이에 참고 자료(대화 이력, 도구 결과 등)를 끼워 넣는 구조입니다.
┌─────────────────────────────────┐
│ 시스템 프롬프트 + 핵심 지시 │ ← 빵 (상단)
├─────────────────────────────────┤
│ 대화 이력 │
│ 도구 호출 결과 │ ← 속재료 (중간)
│ 파일 내용 │
├─────────────────────────────────┤
│ 핵심 지시 재확인 (리마인더) │ ← 빵 (하단)
└─────────────────────────────────┘
왜 이 구조가 효과적인가? LLM의 어텐션 메커니즘은 컨텍스트의 처음과 끝에 위치한 정보에 더 높은 가중치를 부여하는 경향이 있습니다 (이것을 “primacy-recency effect”라고 합니다). 중간에 위치한 정보는 상대적으로 주의를 덜 받습니다. 따라서 모델이 반드시 따라야 하는 지시는 맨 앞에 놓되, 대량의 참고 자료가 그 지시를 희석시키지 않도록 맨 뒤에서 다시 한번 상기시키는 것입니다.
Claude Code의 실제 구현에서도 이 패턴을 확인할 수 있습니다. 시스템 프롬프트의 핵심 규칙이 대화 초반에 주입되고, 대화가 길어지면 중간에 <system-reminder> 태그를 통해 핵심 지시가 다시 삽입됩니다. 이것은 추론 샌드위치의 실전 적용입니다.
컨텍스트 엔지니어링의 숨은 차원 — 시간과 신선도
지금까지 다룬 패턴은 주로 공간적 차원(토큰 윈도우 안에 무엇을 얼마나 넣을 것인가)에 초점을 맞췄습니다. 하지만 컨텍스트 엔지니어링에는 시간적 차원도 있습니다 — 정보의 신선도(freshness) 관리입니다.
에이전트가 10분 전에 읽은 파일 내용이 지금도 유효할까요? 다른 에이전트나 사용자가 그 사이에 파일을 수정했을 수 있습니다. 컨텍스트에 올라와 있는 파일 내용이 디스크의 현재 상태와 다르다면, 에이전트는 유령 컨텍스트(stale context)를 기반으로 잘못된 판단을 내립니다.
이 문제에 대한 해법은 두 가지입니다.
TTL(Time to Live) 기반 무효화: 컨텍스트에 로딩된 각 항목에 만료 시간을 부여합니다. 예를 들어 파일 내용은 5분 후 무효화하고, 에이전트가 해당 파일을 다시 참조할 때 자동으로 재로딩합니다.
이벤트 기반 무효화: 파일 시스템 워치(file system watch)를 통해 파일이 변경되면 컨텍스트에서 해당 항목을 즉시 무효화합니다. 더 정교하지만 구현 비용이 높습니다.
대부분의 현재 하니스는 첫 번째 방식을 채택합니다. 완벽하지 않지만 구현이 단순하고 대부분의 경우 충분히 효과적입니다.
내가 겪은 Harness 실패담 — 회의록 30분을 통째로 넣은 날
음성·STT 파이프라인 프로젝트에서 겪은 일입니다. 30분 분량의 회의 녹음을 STT로 변환하면 대략 4,000~5,000 단어의 텍스트가 나옵니다. 이것을 한국어 토큰으로 환산하면 약 8,000~12,000 토큰입니다.
당시 저는 이 전사(transcription) 결과를 통째로 LLM 컨텍스트에 넣고 “핵심 결정 사항을 정리해 줘”라고 요청하는 단순한 파이프라인을 만들었습니다. 결과는 참담했습니다. 모델은 회의 후반 10분의 내용만 요약했고, 전반부에서 내려진 핵심 의사결정 3건 중 2건을 놓쳤습니다. 특히 회의 초반 5분에 확정된 예산 변경 건이 요약에 완전히 빠져 있었습니다.
원인은 전형적인 컨텍스트 부패 + primacy-recency 편향이었습니다. 30분 분량의 텍스트에는 잡담, 반복, 중간 탈선이 포함되어 있었고, 이것들이 핵심 정보를 희석시켰습니다. 또한 모델의 어텐션이 컨텍스트 후반부에 치우친 결과, 회의 후반의 (상대적으로 덜 중요한) 일정 조율 이야기가 요약의 대부분을 차지했습니다.
해법은 바로 이번 글에서 다룬 패턴의 조합이었습니다. 전사 텍스트를 5분 단위 청크로 분할하고, 각 청크를 먼저 개별 요약한 뒤, 그 요약들만 모아 최종 종합을 요청하는 2단계 프로그레시브 구조로 바꿨습니다. 각 청크 요약은 200~300 토큰 수준이므로, 6개 청크 요약(총 1,500 토큰 내외)이면 30분 회의 전체의 핵심을 누락 없이 담을 수 있었습니다. 12,000 토큰 → 1,500 토큰으로 8배 압축하면서도 정확도는 오히려 올라간 것이죠.
돌이켜보면 이것은 OS의 메모리 관리 원칙 그대로입니다 — 원본 데이터를 통째로 RAM에 올리지 말고, 요약(캐시)을 만들어서 올려라.
실전 체크리스트 — 당신의 하니스에 바로 적용하기
이번 글의 세 가지 패턴을 자신의 에이전트 시스템에 적용할 때 참고할 체크리스트입니다.
- 토큰 예산을 명시적으로 정의했는가? 대부분의 하니스가 암묵적으로(“대충 넣고 잘리면 줄이자”) 컨텍스트를 관리합니다. 슬롯과 비율을 코드 수준에서 명시하는 것만으로도 토큰 효율이 개선됩니다.
- 시스템 프롬프트 슬롯이 보호되고 있는가? 대화가 길어져도 시스템 프롬프트가 밀려나지 않는지 확인하세요. 추론 샌드위치 패턴(리마인더)을 적용하면 추가 안전장치가 됩니다.
- AGENTS.md(또는 동등한 구조화 문서)가 있는가? 없다면 지금 당장 만드세요. 프로젝트 소개, 핵심 규칙 5~7개, 디렉토리 구조만 담아도 효과가 즉각적입니다.
- 파일/데이터를 통째로 컨텍스트에 넣고 있지는 않은가? 프로그레시브 로딩으로 전환하면 토큰 사용량이 수 배에서 수십 배 줄어들 수 있습니다.
- 응답 예약 공간을 확보했는가? 컨텍스트 80% 이상 채우기 전에, 모델이 충분히 길게 응답할 공간이 있는지 확인하세요.
- 오래된 도구 결과나 실패 로그가 청소되고 있는가? 컨텍스트 부패를 예방하려면 무효화된 정보를 적극적으로 제거해야 합니다.
정리 — 토큰 예산 비율 가이드
에이전트 유형별로 권장하는 토큰 예산 비율을 정리합니다.
| 슬롯 | 코딩 에이전트 | 대화형 어시스턴트 | 데이터 분석 에이전트 |
|---|---|---|---|
| 시스템 프롬프트 | 12% | 10% | 15% |
| 장기 메모리 | 8% | 15% | 5% |
| 도구 결과 | 25% | 10% | 30% |
| 대화 이력 | 35% | 45% | 25% |
| 응답 예약 | 20% | 20% | 25% |
이 비율은 출발점이지 절대 법칙이 아닙니다. 자신의 에이전트가 어떤 유형에 가까운지 판단한 뒤, 실제 운영 데이터를 보면서 조정하세요. 핵심은 비율 자체가 아니라 “비율을 의식적으로 설정하고 관리한다”는 행위입니다.
이번 글의 한 줄 요약
컨텍스트 윈도우는 RAM이고, 토큰은 한정 자원이다 — 토큰 예산·구조화된 주입·프로그레시브 로딩, 이 세 패턴이 하니스 성능의 절반을 결정한다.
다음 회차 예고 — 5회: 도구 인터페이스와 MCP
이번 글에서 우리는 하니스의 첫 번째 부품, 컨텍스트 엔지니어링을 해부했습니다. 하지만 컨텍스트를 채우는 정보는 어디서 올까요? 사용자 입력을 제외하면, 가장 큰 정보 소스는 도구(Tool)입니다. 파일 읽기, 웹 검색, API 호출, 데이터베이스 쿼리 — 이 모든 것이 도구 인터페이스를 통해 컨텍스트에 흘러들어옵니다.
5회에서는 하니스의 두 번째 컴포넌트, 도구 인터페이스와 MCP(Model Context Protocol)를 다룹니다. LLM이 외부 세계와 상호작용하는 방식, MCP가 도구 생태계를 어떻게 표준화하고 있는지, 그리고 도구를 너무 많이 노출했을 때 벌어지는 “도구 과다(tool overload)” 문제까지 — OS 비유로 말하면, RAM(컨텍스트) 다음은 I/O 시스템(도구)입니다.
컨텍스트에 넣을 정보를 만드는 곳이 도구라면, 도구를 잘 설계해야 컨텍스트도 깨끗해집니다. 다음 글에서 그 연결고리를 풀어 보겠습니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 3화 (다음 차수는 아직 게시되지 않았습니다)