
이 글은 AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 시리즈의 3회입니다. 1회에서 에이전트 하니스의 개념을, 2회에서 벤치마크로 증명한 하니스 효과를 다뤘습니다.
이전 이야기 — 하니스가 중요하다는 건 알겠는데
2회까지 우리는 두 가지를 확인했습니다. 첫째, 에이전트 하니스(Agent Harness)란 LLM이라는 CPU를 감싸는 운영체제 — 컨텍스트 관리, 도구 호출, 메모리, 에러 복구를 책임지는 소프트웨어 계층입니다. 둘째, 같은 Claude Opus 모델이 하니스에 따라 Terminal-Bench 2.0에서 16점, CORE-Bench에서 36점포인트 차이를 보인다는 걸 수치로 증명했습니다.
그런데 여기서 질문이 하나 남습니다. 하니스가 그렇게 중요하다면, 왜 대부분의 팀은 좋은 하니스를 만들지 못하는 걸까요? 왜 “데모에서는 잘 되는데 프로덕션에서는 안 돼요”가 2026년에도 가장 흔한 에이전트 사망 보고인 걸까요?
3회의 주제는 바로 이것입니다. 프로토타입과 제품 사이의 골짜기 — 88%의 에이전트가 빠지는, 하니스 없는 세계의 지형도를 그려보겠습니다.
88%라는 숫자 — 에이전트의 “죽음의 골짜기”
2026년 현재, AI 에이전트 프로젝트의 약 88%가 프로덕션에 도달하지 못합니다. 이 수치는 여러 산업 리포트와 엔터프라이즈 설문의 교집합에서 나온 추정치인데, 숫자의 정밀도보다 중요한 건 이 숫자가 전하는 메시지입니다.
10개 팀이 에이전트를 만들기 시작하면, 1~2개만 실제 사용자 앞에 선다는 뜻입니다. 나머지 8~9개는 어디로 갈까요? 대부분 “내부 데모”나 “POC 완료” 단계에서 조용히 사라집니다. 기술 부채를 감당하지 못해서, 비용이 예산을 초과해서, 또는 단순히 “품질이 불안정해서”라는 이유로.

실리콘밸리에서는 이걸 “Valley of Death”라고 부릅니다. 기술 스타트업에서 시제품과 시장 적합 제품 사이의 간극을 가리키던 용어인데, AI 에이전트 세계에서 이 골짜기는 유독 깊습니다. 왜냐하면 LLM 기반 시스템의 프로토타입은 거의 항상 인상적으로 작동하기 때문입니다.
전통 소프트웨어의 프로토타입은 솔직합니다. 버튼이 작동하거나 안 하거나, 쿼리가 돌아가거나 에러가 나거나. 하지만 LLM 에이전트의 프로토타입은 실패할 때도 그럴듯하게 실패합니다. 자연어로 된 출력은 맞는 것처럼 보이고, 도구 호출은 형식이 올바르며, 전체 흐름이 마치 작동하는 것처럼 느껴집니다. 이게 함정입니다.
“데모에서는 잘 되는데요” — 프로토타입이 거짓말하는 5가지 조건
모든 에이전트 프로토타입은 다섯 가지 숨겨진 특혜 속에서 태어납니다. 이 특혜를 의식하지 못하면, 골짜기에 빠지는 건 시간문제입니다.
특혜 1: 짧은 대화
데모는 보통 3~5턴입니다. “이 코드를 리팩터링해줘” → 결과 확인 → “좋아, 테스트도 추가해줘” → 끝. 컨텍스트 윈도우(우리 비유로 RAM)는 넉넉하고, 컨텍스트 부패(Context Rot)가 일어날 시간이 없습니다. 하지만 프로덕션에서 에이전트는 20턴, 50턴, 때로는 200턴을 이어갑니다. RAM이 가득 차면 어떻게 될까요? 하니스 없는 에이전트는 그냥 느려지거나, 이전 지시를 잊거나, 환각을 시작합니다.
특혜 2: 해피 패스 입력
데모에서 테스트하는 입력은 깔끔합니다. 잘 정리된 코드, 명확한 지시, 예상 가능한 도구 응답. 프로덕션에서는? 사용자가 오타 가득한 한국어와 영어를 섞어 쓰고, API가 502를 반환하고, 파일 인코딩이 EUC-KR이며, JSON 응답에 예상 못 한 필드가 30개 추가되어 있습니다. 프로토타입은 해피 패스만 걷고, 프로덕션은 정글을 통과해야 합니다.
특혜 3: 단일 사용자
데모에서는 개발자 한 명이 에이전트 한 대를 독점합니다. 프로덕션에서는 동시에 여러 요청이 들어오고, 세션이 섞이면 안 되고, 한 사용자의 폭주가 다른 사용자를 굶기면 안 됩니다. 하니스의 세션 관리와 요청 큐가 필요한 이유입니다.
특혜 4: 무한 예산
POC 기간에는 토큰 비용을 아무도 세지 않습니다. “일단 되게 만들자”가 모토이니까요. 하지만 프로덕션에 올리는 순간 CFO가 물어봅니다 — “이 에이전트 한 달에 얼마야?” 같은 작업에서 하니스 설계에 따라 토큰 사용량이 33K 대 188K로 5.5배 차이가 납니다(2회에서 다룬 Claude Code vs Cursor 데이터). 5.5배는 월 100만 원과 550만 원의 차이입니다.
특혜 5: 인간 안전망
가장 위험한 특혜입니다. 데모에서는 개발자가 실시간으로 지켜보며, 에이전트가 이상한 방향으로 가면 즉시 개입합니다. “아, 그게 아니라 이걸 해줘.” 이 인간 안전망이 프로토타입의 성공률을 인위적으로 끌어올립니다. 프로덕션에서는 에이전트가 혼자 돌아갑니다. 새벽 3시에 API 키가 만료되어도, 잘못된 파일을 삭제하려 해도, 루프에 빠져 토큰을 태워도 — 아무도 없습니다.
이 다섯 가지 특혜를 OS 비유로 정리하면 이렇습니다: 프로토타입은 관리자가 옆에 앉아 수동으로 메모리를 관리해주고, 프로세스를 감시해주고, 에러가 나면 직접 재부팅해주는 환경입니다. 프로덕션은 OS 없이 CPU만 던져놓은 상태이고요. 88%가 죽는 건 당연합니다.
프로덕션이 프로토타입에게 던지는 5가지 치명적 질문
Anthropic의 엔지니어링 블로그 “Building Effective Agents”(2024)는 프로덕션 에이전트 구축에서 반복되는 실패 패턴을 다루며 이렇게 말합니다:
“The most successful implementations weren’t using complex frameworks or specialized libraries — they were building with simple, composable patterns.”
— Anthropic, “Building Effective Agents”
역설적이지만 핵심을 찌르는 관찰입니다. 성공한 팀은 화려한 프레임워크가 아니라 단순하고 조합 가능한 패턴 — 즉, 잘 설계된 하니스를 썼다는 겁니다. 이 문장을 뒤집으면, 실패한 팀의 공통점이 보입니다: 하니스가 없거나, 있어도 프로덕션의 질문에 답하지 못하는 하니스를 갖고 있었다는 것.
프로덕션 환경이 에이전트에게 던지는 질문은 다섯 가지로 수렴합니다. 이 질문 각각은 다음 회차(4~8회)에서 다룰 하니스 컴포넌트와 직결됩니다.

질문 1: “컨텍스트가 넘치면 어떻게 할 건가?”
200K 토큰 컨텍스트 윈도우가 무한하다고 착각하면 안 됩니다. 복잡한 코딩 작업에서 에이전트는 소스 파일, 도구 호출 결과, 에러 로그, 이전 시도 이력을 모두 컨텍스트에 쌓습니다. 20턴만 지나도 컨텍스트의 절반이 “쓰레기”로 차고, 모델은 중요한 지시를 놓치기 시작합니다. 이게 컨텍스트 부패(Context Rot)입니다.
CORE-Bench 결과가 이를 정확히 보여줍니다. Claude Opus가 최소 스캐폴드(= 하니스 없음)에서 42%, 완전한 하니스(Claude Code)에서 78%를 기록했습니다. 같은 모델인데 36점포인트 차이. 이 차이의 상당 부분이 컨텍스트 관리에서 옵니다 — 언제 오래된 정보를 버리고, 무엇을 요약하고, 어떤 파일을 프로그레시브하게 로딩할지를 하니스가 결정하기 때문입니다.
프로토타입은 이 질문을 받지 않습니다. 대화가 짧으니까요. 하지만 프로덕션에서 이 질문에 답하지 못하면, 에이전트는 30턴 이후 급격히 정확도가 떨어지는 시한폭탄이 됩니다.
질문 2: “도구가 실패하면 어떻게 할 건가?”
에이전트의 힘은 도구에서 나옵니다. 파일을 읽고, API를 호출하고, 데이터베이스를 쿼리하고, 코드를 실행합니다. 데모에서 이 도구들은 항상 작동합니다. 로컬 파일시스템은 빠르고, 테스트 API는 안정적이고, 데이터베이스는 개발자 로컬에서 돌아갑니다.
프로덕션에서는?
- 외부 API가 타임아웃을 냅니다 (평균 응답 200ms인 서비스가 갑자기 12초)
- 파일 시스템 권한이 다릅니다 (개발 환경에서는 sudo였는데 프로덕션은 제한된 사용자)
- 도구가 예상과 다른 형식의 응답을 반환합니다 (API 버전 업데이트, 필드 이름 변경)
- 도구가 부분적으로 성공합니다 (5개 파일 중 3개만 수정됨 — 성공인가? 실패인가?)
하니스 없는 에이전트는 도구 실패 앞에서 무력합니다. 최선의 경우 멈추고, 최악의 경우 실패를 무시하고 진행하다 엉뚱한 결과를 냅니다. 도구 타임아웃, 재시도 로직, 부분 실패 처리 — 전부 하니스의 몫입니다.
질문 3: “비용이 폭발하면 어떻게 할 건가?”
이전 회차에서 확인한 수치를 다시 꺼내봅시다. 동일한 코딩 작업에서:
- Claude Code: 평균 33K 토큰 소비
- Cursor: 평균 188K 토큰 소비
5.5배 차이입니다. 이 차이는 모델이 아니라 하니스가 만들어냅니다. Claude Code는 필요한 파일만 선택적으로 로딩하고, Cursor는 프로젝트 컨텍스트를 넓게 포함합니다. 두 전략 모두 일리 있지만, 비용 민감한 프로덕션 환경에서는 토큰 예산 관리가 생존의 문제입니다.
프로토타입 단계에서 “작업당 $0.05″였던 비용이 프로덕션의 긴 대화와 재시도 루프를 거치면 “작업당 $0.50″으로 10배 뛰는 건 흔한 일입니다. 월 1만 건 처리 기준으로 $500과 $5,000의 차이 — 스타트업에게는 생사의 문제입니다.
질문 4: “에러를 어떻게 복구하는가?”
프로토타입 에이전트의 에러 처리는 보통 이렇습니다:
try/except: pass(에러 삼키기)- 또는 에러를 그대로 사용자에게 전달 (“An error occurred: ConnectionResetError…”)
- 또는 에러 처리 자체가 없음
프로덕션 에이전트에게 필요한 에러 복구는 차원이 다릅니다:
- 자동 재시도: 일시적 실패(네트워크 타임아웃, rate limit)는 지수 백오프로 재시도
- 대안 경로: 1차 도구가 실패하면 대안 도구로 전환 (파일 읽기 실패 → grep으로 탐색)
- 우아한 퇴보(graceful degradation): 전체 실패보다 부분 결과 반환이 나음
- 루프 탈출: 같은 에러를 3번 반복하면 전략을 바꾸거나 사용자에게 위임
이 모든 것이 하니스의 컨트롤 루프(Agent Loop) 레이어에서 처리됩니다. 컨트롤 루프 없는 에이전트는 첫 번째 에러에서 멈추거나, 에러를 무시하고 잘못된 길로 돌진합니다.
질문 5: “성능을 어떻게 측정하는가?”
가장 교활한 질문입니다. 프로토타입 단계에서 “성능 측정”은 개발자의 눈입니다. 결과를 보고 “이 정도면 괜찮네” 하면 통과입니다. 하지만 프로덕션에서는:
- 하루 1,000건의 에이전트 작업을 사람이 일일이 검수할 수 없습니다
- 어제까지 잘 되던 작업이 오늘 갑자기 품질이 떨어져도 알 방법이 없습니다
- “잘 되고 있다”의 기준이 주관적이어서 팀원마다 다릅니다
하니스의 센서(Sensors) 계층 — 린터, 자동 테스트, 결과 평가기 — 이 여기서 작동합니다. 센서가 없는 에이전트를 프로덕션에 올리는 건, 계기판 없는 비행기를 조종하는 것과 같습니다. 이륙은 할 수 있지만 착륙은 운에 맡기는 셈입니다.
벤치마크로 보는 골짜기의 깊이
다섯 가지 질문이 실제로 얼마나 큰 차이를 만드는지, 공개된 벤치마크 데이터를 한 테이블로 모아보겠습니다. 아래 수치들은 모두 2회에서 다룬 독립 테스트 결과를 프로토타입 조건(최소 하니스)과 프로덕션 조건(완전 하니스)으로 재배열한 것입니다.
| 측정 항목 | 최소 하니스 (프로토타입) | 완전 하니스 (프로덕션) | 격차 |
|---|---|---|---|
| CORE-Bench 작업 완료율 (Claude Opus) | 42% | 78% | +36pp |
| Terminal-Bench 2.0 점수 (Claude Opus) | 77% (Claude Code) | 93% (Cursor) | +16pp |
| GPT-5.5 기능성 점수 | 61.5% (기본 하니스) | 87.2% (최적 하니스) | +25.7pp |
| 동일 작업 토큰 소비 | 188K (Cursor) | 33K (Claude Code) | 5.5× 절약 |
| 달러당 정확도 — 복잡 멀티파일 | 6.2점 (Cursor) | 8.5점 (Claude Code) | +37% |
| 달러당 정확도 — 단순 유틸리티 | 31점 (Claude Code) | 42점 (Cursor) | +35% |
| 스탠퍼드·칭화 연구 — 동일 모델 최대 격차 | 기준선 | 최적 하니스 | 최대 6× |
이 테이블에서 주목할 점이 두 가지 있습니다.
첫째, 격차가 일관되게 크다. 16점포인트에서 36점포인트, 최대 6배까지. 이건 통계적 노이즈가 아닙니다. 하니스라는 구조적 요인이 만들어내는 체계적 차이입니다.
둘째, “최고의 하니스”는 작업에 따라 다르다. 복잡한 멀티파일 작업에서는 Claude Code의 하니스가 달러당 정확도 8.5점으로 우위지만, 단순 유틸리티 작업에서는 Cursor가 42점으로 앞섭니다. 하니스는 만능 열쇠가 아니라 작업에 맞는 열쇠입니다. 이건 11~12회(Phase 4: WHICH)에서 깊이 다룰 주제이기도 합니다.
하지만 지금 단계에서 확실한 건 이겁니다: 하니스가 “없는” 상태(최소 스캐폴드 42%)에서 “있는” 상태(78%)로 가는 것만으로도 성능이 거의 두 배 됩니다. 88%의 에이전트가 프로덕션에 실패하는 이유는, 이 42% → 78% 여정을 시작하지 않았기 때문입니다.
코드로 보는 차이 — 프로덕션 준비도 진단기
이론만으로는 부족하니, 여러분의 에이전트가 골짜기의 어디쯤에 서 있는지 진단할 수 있는 도구를 만들어봅시다. 아래 코드는 에이전트 하니스의 10가지 핵심 체크포인트를 점수화하여 PROTOTYPE / STAGING / PRODUCTION 세 구간으로 분류합니다.
# harness_diagnostic.py — 에이전트 하니스 프로덕션 준비도 진단
from dataclasses import dataclass
@dataclass
class HarnessAudit:
"""에이전트 하니스의 프로덕션 준비도를 10개 항목으로 진단합니다."""
context_budget: bool = False # 토큰 예산 한도가 있는가
context_eviction: bool = False # 오래된 컨텍스트를 자동 퇴거하는가
tool_timeout: bool = False # 도구 호출에 타임아웃이 있는가
tool_retry: bool = False # 도구 실패 시 재시도 로직이 있는가
error_recovery: bool = False # 에러 복구 전략이 있는가
cost_tracking: bool = False # 토큰/비용을 추적하는가
eval_pipeline: bool = False # 자동화된 평가가 있는가
memory_mgmt: bool = False # 세션/장기 메모리를 관리하는가
permission_gate: bool = False # 위험 행동에 사전 승인이 있는가
guide_docs: bool = False # 시스템 프롬프트/규칙 문서가 있는가
_WEIGHTS = { # 가중치 합계 = 100
"context_budget": 15, "context_eviction": 10,
"tool_timeout": 10, "tool_retry": 10,
"error_recovery": 15, "cost_tracking": 5,
"eval_pipeline": 15, "memory_mgmt": 10,
"permission_gate": 5, "guide_docs": 5,
}
def score(self) -> int:
return sum(
w for field, w in self._WEIGHTS.items()
if getattr(self, field)
)
def zone(self) -> str:
s = self.score()
if s >= 80: return "🟢 PRODUCTION"
if s >= 50: return "🟡 STAGING"
return "🔴 PROTOTYPE"
def gaps(self) -> list[str]:
return [f for f, _ in self._WEIGHTS.items() if not getattr(self, f)]
def report(self) -> str:
lines = [f"준비도: {self.score()}/100 — {self.zone()}"]
if g := self.gaps():
lines.append(f"미충족 항목: {', '.join(g)}")
return "\n".join(lines)
# ── 사용 예시 ──
prototype = HarnessAudit(guide_docs=True, tool_timeout=True)
print(prototype.report())
# 준비도: 15/100 — 🔴 PROTOTYPE
# 미충족 항목: context_budget, context_eviction, tool_retry, ...
production = HarnessAudit(
context_budget=True, context_eviction=True,
tool_timeout=True, tool_retry=True, error_recovery=True,
cost_tracking=True, eval_pipeline=True,
memory_mgmt=True, permission_gate=True, guide_docs=True,
)
print(production.report())
# 준비도: 100/100 — 🟢 PRODUCTION
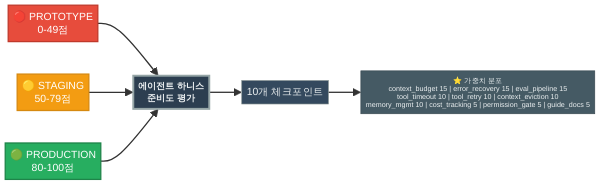
이 코드를 여러분의 에이전트 프로젝트에 적용해보세요. 대부분의 프로토타입은 10~20점 구간에 머뭅니다 — guide_docs(시스템 프롬프트는 대개 있으니까)와 tool_timeout(HTTP 라이브러리 기본값) 정도만 True일 테니까요. 이 점수가 80점 이상으로 올라가려면, 4~8회에서 다룰 6대 하니스 컴포넌트를 하나씩 구축해야 합니다.
진단기의 가중치 설계가 전하는 메시지도 중요합니다. context_budget(15점), error_recovery(15점), eval_pipeline(15점) — 이 세 항목이 전체의 45%를 차지합니다. 컨텍스트 관리, 에러 복구, 평가. 이 세 가지가 골짜기를 건너는 다리의 세 기둥입니다.
내가 겪은 Harness 실패담: 음성 에이전트의 배신
작년 말, 사내에서 음성 기반 작업 자동화 에이전트를 만들었습니다. 한국어 음성을 STT로 변환하고, 의도를 추출하고, 적절한 API를 호출하는 파이프라인이었습니다. 데모는 완벽했습니다. 3분짜리 음성 클립 10개로 테스트했고, 의도 추출 정확도 94%를 찍었습니다. 팀은 축하했고, 2주 뒤 프로덕션 배포를 잡았습니다.
배포 후 일주일이 지나자 정확도가 61%로 곤두박질쳤습니다.
원인은 세 가지였습니다. 첫째, 실제 통화는 평균 12분이었는데, STT 결과를 통째로 컨텍스트에 넣으니 토큰 예산을 초과했습니다 — 컨텍스트 부패. 둘째, STT 서비스가 간헐적으로 부분 실패(앞부분만 변환)를 반환했는데, 에이전트는 이걸 정상 입력으로 처리했습니다 — 도구 실패 미감지. 셋째, 에러 핸들러는 통째로 try/except: pass였습니다 — 에러 복구 부재.
진단기를 돌렸다면 해당 시스템은 15점짜리 PROTOTYPE이었습니다. 가이드 문서와 기본 타임아웃만 있었으니까요. 우리는 프로토타입을 프로덕션이라 착각한 88%의 일원이었습니다. 결국 3주를 더 써서 컨텍스트 요약기, STT 검증 레이어, 재시도 로직을 추가한 뒤에야 정확도가 87%까지 회복됐습니다. 그 3주 동안 추가한 것이 바로 하니스였습니다.
골짜기를 건너는 지도 — 6대 하니스 컴포넌트
지금까지 우리는 골짜기의 존재를 확인하고, 깊이를 측정하고, 빠지는 이유를 분석했습니다. 남은 질문은 하나입니다: 어떻게 건너는가?
답은 다음 회차(4~8회)에서 하나씩 펼쳐질 6대 하니스 컴포넌트에 있습니다. 오늘은 미리 지도만 펼쳐놓겠습니다.
| 컴포넌트 | 대응하는 프로덕션 질문 | 회차 |
|---|---|---|
| 컨텍스트 엔지니어링 | 컨텍스트가 넘치면? | 4회 |
| 도구 인터페이스 & MCP | 도구가 실패하면? | 5회 |
| 메모리 아키텍처 | 이전 대화를 기억해야 하면? | 6회 |
| 컨트롤 루프 | 에러를 어떻게 복구하는가? | 7회 |
| 센서 & 권한 | 성능을 어떻게 측정하는가? | 8회 |
OS 비유를 이어가면, 이 6개가 하니스라는 운영체제의 핵심 서브시스템입니다:
- 컨텍스트 엔지니어링 = 메모리 관리자 (RAM 할당과 해제)
- 도구 인터페이스 = I/O 드라이버 (하드웨어와의 통신)
- 메모리 아키텍처 = 파일시스템 (영속적 저장)
- 컨트롤 루프 = 프로세스 스케줄러 (실행 흐름 제어)
- 센서 = 시스템 모니터 (성능 계측)
- 권한 = 접근 제어 (보안 게이트)
프로토타입에서 프로덕션으로 가는 길은, 이 6개 컴포넌트를 하나씩 구축하는 과정입니다. 진단기에서 15점이었던 에이전트가 컴포넌트를 하나 추가할 때마다 10~15점씩 올라가고, 80점을 넘으면 프로덕션 존에 진입합니다. 마법이 아니라 엔지니어링입니다.
이번 글의 한 줄 요약
88%의 에이전트가 프로덕션에 실패하는 이유는 모델의 한계가 아니라 하니스의 부재다 — 프로토타입의 5가지 숨겨진 특혜가 사라지는 순간, 하니스 없는 에이전트는 무너진다.
다음 회차 예고
4회부터는 Phase 2 “WHAT”에 진입합니다. 첫 번째 컴포넌트는 컨텍스트 엔지니어링 — 토큰 예산을 설계하고, AGENTS.md로 가이드하고, 프로그레시브 로딩으로 필요한 것만 올리는 기술입니다. 컨텍스트 윈도우라는 RAM을 어떻게 관리하면 같은 모델이 2배 똑똑해지는지, 코드와 함께 보여드리겠습니다.
다음 화: 컨텍스트 엔지니어링 — 토큰 예산, AGENTS.md, 그리고 프로그레시브 로딩
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 2화 (다음 차수는 아직 게시되지 않았습니다)