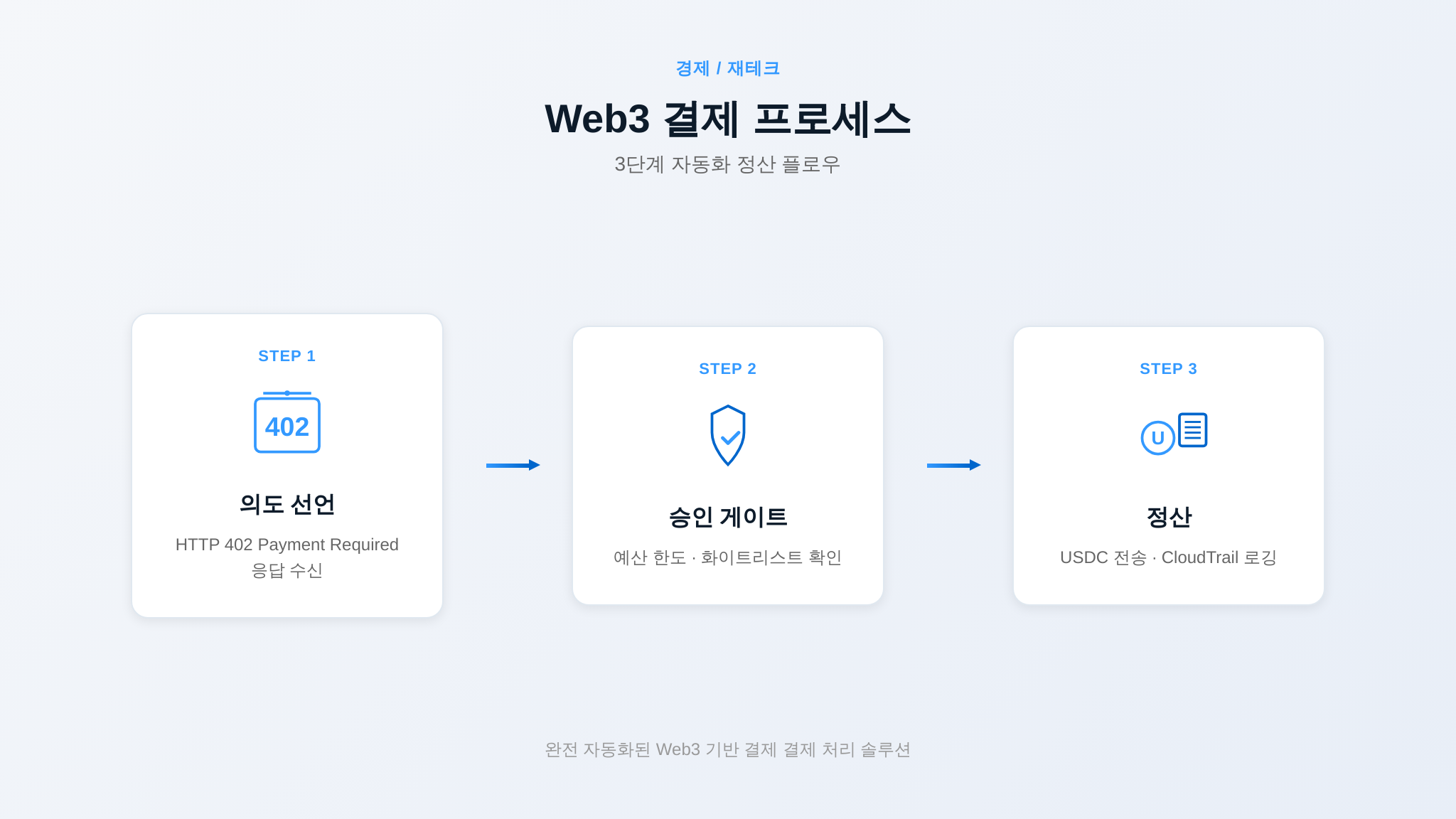
어제 22화에서는 AWS가 Bedrock AgentCore Payments로 AI 에이전트 결제 인프라 시장에 본격 진입한 흐름을 짚었습니다. 오늘은 시선을 국내로 돌립니다 — 한국은행 프로젝트 한강 플랫폼 위에서 AI 에이전트가 디지털 원화로 자율 거래를 수행하는 시나리오, 과연 현실이 될까요, 아니면 거품에 불과할까요.
본 글은 「토큰북: 금융IT 20년차의 디지털 원화 관찰일지」 24일 연재 23회차입니다.
본 글은 공개된 보도·자료만을 바탕으로 한 일반 독자용 분석이며, 어떤 기관의 내부 정보도 담고 있지 않습니다.
왜 중앙은행이 AI 에이전트를 신경 써야 하는가
20화(에이전틱 커머스) → 21화(x402 프로토콜) → 22화(AWS AgentCore Payments). 이 세 회를 관통하는 단어가 하나 있습니다. 기계 대 기계(M2M, Machine-to-Machine) 결제입니다. AI 에이전트가 사람의 승인 없이 상품을 비교하고, 가격을 협상하며, 결제까지 끝내는 세상. 이 시나리오가 실현되려면 에이전트가 프로그래밍 방식으로 제어할 수 있는 화폐가 반드시 필요합니다.
프로그래머블 머니 — CBDC의 진짜 가치
프로그래머블 머니(Programmable Money)란 소프트웨어 코드로 지급 조건·용도·한도를 내장할 수 있는 디지털 화폐를 뜻합니다. 일반 계좌이체가 “A에서 B로 얼마를 보내라”만 표현한다면, 프로그래머블 머니는 “배송 완료가 확인되면, 판매자에게 10만 원을 지급하되, 30일 이내 반품 시 자동 환불하라” 같은 복합 조건을 화폐 자체에 심을 수 있습니다.
6화에서 살펴본 프로젝트 한강 2단계가 테스트한 핵심이 바로 이 기능이었습니다. 스마트 컨트랙트(자동 실행 계약)를 CBDC 플랫폼 위에 올려, 예금토큰과 디지털 원화의 조건부 지급을 시험했죠. 이 기능이 AI 에이전트에게는 사실상 프로그래밍 인터페이스(API) 역할을 합니다.
화폐 주도권 경쟁 — 스테이블코인 vs CBDC
현재 AI 에이전트 결제의 유력 후보는 두 갈래로 나뉩니다.
스테이블코인 진영 — USDC를 채택한 x402 프로토콜(21화), AWS AgentCore(22화), Coinbase 등 민간이 빠르게 주도. 장점은 속도와 글로벌 호환성, 단점은 법정 통화 지위 부재와 발행자 신용 위험.
CBDC 진영 — 한국은행 프로젝트 한강, ECB 디지털 유로, 중국 e-CNY 등 중앙은행이 직접 발행. 장점은 법적 안정성과 최종 결제성(settlement finality), 단점은 개발 속도와 민간 생태계 구축의 어려움.
한국은행이 AI 에이전트에 관심을 가져야 하는 이유는 명확합니다. 만약 AI 에이전트 경제의 결제 표준이 USDC 같은 달러 스테이블코인 중심으로 먼저 굳어지면, 디지털 원화가 설 자리는 급격히 줄어듭니다. 8화에서 다뤘던 원화 스테이블코인 공백 문제가 AI 에이전트 시대에 더 뼈아프게 돌아오는 셈입니다.
BIS(국제결제은행)도 같은 인식입니다. BIS 이노베이션 허브는 2025년 연례 보고서에서 “AI 에이전트가 대규모로 활성화될 경우, CBDC가 아닌 민간 스테이블코인이 M2M 결제의 사실상 표준이 될 위험이 있다”고 경고한 바 있습니다(BIS Annual Economic Report, 2025년 6월).
프로젝트 한강 + AI 에이전트 — 타임라인 정리
프로젝트 한강의 진행 경과를 AI 에이전트 관점에서 재구성해 보겠습니다. 6화에서 다룬 내용과 중복을 피하면서, 이후에 새로 공개된 흐름에 집중합니다.
2단계에서 확인된 기술적 토대
프로젝트 한강 2단계(2024~2025년)는 KB국민·신한·하나·우리 등 9개 은행과 함께 예금토큰·CBDC의 실결제 가능성을 검증했습니다. 핵심 성과 세 가지가 AI 에이전트와 직접 연결됩니다.
스마트 컨트랙트 실행: 조건부 지급(에스크로)을 온체인에서 자동 처리. AI 에이전트의 조건부 결제에 기반 기술 제공.
실시간 정산: 은행 간 대사(reconciliation) 없이 건별 즉시 최종 정산. 에이전트 간 밀리초 단위 거래에 적합.
프라이버시 레이어: 영지식증명(ZKP) 기반 거래 프라이버시 테스트. 에이전트 거래의 개인정보 보호 요건 충족 가능성 확인.
이 세 가지가 갖춰졌다고 해서 AI 에이전트가 당장 디지털 원화를 쓸 수 있는 건 아닙니다. 하지만 ‘기술적으로 가능한가?’라는 질문에는 조건부 예라고 답할 수 있는 단계에 도달한 것입니다.
3단계 논의에서 AI가 등장한 배경
한국은행은 2025년 10월 프로젝트 한강 2단계 결과보고서를 공개하면서, 3단계 방향을 예고했습니다. 보도자료에 따르면 3단계는 “프로그래머블 머니의 활용 범위를 IoT·AI 에이전트 영역으로 확장하는 방안을 포함”한다고 명시했습니다(한국은행 보도자료, 2025년 10월).
이 문구가 중요한 이유는 크게 두 가지입니다.
첫째, 중앙은행이 AI 에이전트를 공식 의제로 올린 최초 사례 중 하나입니다. 글로벌 중앙은행 중에서도 BOK, MAS(싱가포르 통화청), BIS 정도만 이 수준의 명시적 언급을 하고 있습니다.
둘째, AI 에이전트와 IoT를 함께 묶었다는 점입니다. 이는 M2M 마이크로페이먼트 — 기기 간 소액 자율 결제 — 를 핵심 활용처로 상정하고 있다는 신호입니다.
2026년 상반기 — 공식 실험 윤곽
2026년 들어 움직임이 좀 더 구체화됐습니다.
매일경제(2026년 3월) 보도에 따르면, 한국은행 금융결제국 관계자는 “AI 에이전트가 소액 결제를 자율적으로 처리하는 시나리오는 CBDC의 핵심 활용처 중 하나로 검토 중”이라고 밝혔습니다.
2026년 4월 서울에서 열린 BIS-BOK 공동 컨퍼런스에서는 “한강 플랫폼의 API를 AI 에이전트 프레임워크에 연동하는 기술 실증(PoC)을 2026년 하반기에 착수할 계획”이라는 발표가 있었습니다(한국은행·BIS 공동 세미나 자료, 2026년 4월).
자본시장연구원은 “AI 에이전트 기반 금융 자동화와 CBDC 결합 가능성” 보고서(2026년 5월)에서 한국형 AI 에이전트 결제 모델의 기술적·법적 요건을 정리했습니다.
이 흐름을 종합하면, 한국은행은 AI 에이전트를 CBDC의 핵심 미래 활용처로 인식하고 있으며, 기술 실증 단계에 진입하려는 시점에 있습니다. ‘실험실 안의 계획’에서 ‘실험실 밖 PoC’로 넘어가는 전환점이라 할 수 있습니다.
글로벌 중앙은행의 AI 에이전트 실험 — 한눈에 비교
한국은행만 이 탐색을 하는 건 아닙니다. 주요 중앙은행과 국제기구의 현황을 비교해 봅니다.
기관 / 프로젝트
핵심 실험 내용
진행 단계
AI 에이전트 연계
한국은행 프로젝트 한강
예금토큰·CBDC 스마트 컨트랙트, 실시간 정산
2단계 완료 3단계 준비
PoC 계획 공식 발표 (2026 하반기 착수)
BIS Innovation Hub Project Agorá 외
토큰화 예금 크로스보더 결제, AI 감독 도구
기술 실증 진행
AI 기반 금융 감독 연구 병행
싱가포르 MAS Project Guardian
토큰화 자산 운용·DeFi 연계
2단계 진행
AI 펀드 매니저 PoC 포함 (19화 참조)
ECB 디지털 유로
오프라인 결제·프라이버시 설계
준비 단계
공식 언급 제한적 (프라이버시 우선)
일본은행(BOJ) DCJPY 협의체
예금토큰 표준화·상호운용
민관 공동 파일럿
IoT 결제 연계 검토
영란은행(BOE) 디지털 파운드
CBDC 아키텍처 설계·API 사양
설계 협의
API 생태계 설계 중 (에이전트 활용 가정 포함)
이 표에서 읽을 수 있는 신호는 두 가지입니다.
첫째, 한국은 AI 에이전트 연계를 공식 의제로 올린 초기 그룹에 속합니다. 싱가포르와 함께 아시아에서 가장 앞서 있으며, ECB·BOE보다 한 발 빠릅니다.
둘째, 어디도 ‘운영 배포’ 단계에 도달하지 못했습니다. 가장 앞선 싱가포르도 PoC(기술 실증) 수준이며, 실 사용자 대상 서비스는 전 세계 어디에도 없습니다. 이 사실이 “진짜 vs 거품” 판단의 출발점입니다.
AI 에이전트가 디지털 원화를 쓰는 시나리오 3가지
추상적인 “AI + CBDC”를 구체적 일상으로 번역해 봅니다. 만약 프로젝트 한강 3단계에서 AI 에이전트 연동이 성공한다면, 어떤 서비스가 가능해질까요.
시나리오 A — B2B 공급망 자동 정산
누가: 제조사, 부품 공급업체, 물류사 어떻게: AI 에이전트가 발주서를 자동 생성 → 납품 센서가 입고를 확인 → 스마트 컨트랙트가 대금을 즉시 지급 왜 CBDC가 필요한가: 현행 은행 시스템은 건별 정산에 1~3영업일이 소요됩니다. CBDC 스마트 컨트랙트는 실시간 최종 정산이 가능해, 공급망 전체의 운전자금 부담을 크게 줄일 수 있습니다.
이 시나리오는 실현 가능성이 가장 높다고 평가됩니다. 참여자가 기업(법인)이므로 규제 공백이 상대적으로 작고, 경제적 인센티브가 명확하기 때문입니다.
시나리오 B — 소비자 AI 비서의 청구서 최적화
누가: 개인 소비자 어떻게: AI 비서가 전기·가스·통신·보험 청구서를 분석 → 요금제 비교 → 최적 플랜으로 자동 전환 → 디지털 원화로 납부 왜 CBDC가 필요한가: 기존 자동이체는 “지정 날짜에 고정 금액 인출”만 가능합니다. 프로그래머블 디지털 원화는 “조건 A 충족 시 B 플랜으로 전환 후 차액 납부”라는 복합 로직을 화폐 단에서 처리할 수 있습니다.
이 시나리오는 소비자 체감도가 높지만, 규제 장벽이 큽니다. AI가 소비자를 대리해 계약을 변경하고 결제하는 행위의 법적 근거가 아직 없기 때문입니다.
시나리오 C — IoT 마이크로페이먼트
누가: 자율주행차, 스마트홈 기기, 산업용 센서 어떻게: 전기차가 충전소에 도착 → 충전기와 차량이 직접 가격 협상 → 충전 완료 후 디지털 원화로 마이크로 결제 (건당 100~1,000원 수준) 왜 CBDC가 필요한가: 건당 거래액이 너무 작아 기존 카드·계좌이체 수수료 구조로는 수수료가 거래 금액을 초과합니다. CBDC의 무(無)수수료 또는 극저수수료 구조만이 경제성을 확보합니다.
이 시나리오는 CBDC + AI의 가장 강력한 존재 이유이지만, 시장 자체가 아직 초기입니다. 자율주행 상용화, IoT 결제 표준 확립 등 선결 조건이 많습니다.
진짜일까 거품일까 — 3가지 판단 기준
금융IT 20년차의 시각으로 한국은행의 AI 에이전트 실험이 어느 쪽에 가까운지, 세 가지 기준으로 냉정하게 진단해 봅니다.
기준 1 — 기술적 준비도: “에이전트가 호출할 API가 있는가?”
AI 에이전트가 디지털 원화를 사용하려면 기계가 읽을 수 있는 표준 API(Application Programming Interface)가 필수입니다. 22화에서 본 AWS AgentCore가 USDC 결제를 지원할 수 있었던 건 Coinbase의 CDP(Commerce Developer Platform) API가 이미 있었기 때문입니다.
현재 프로젝트 한강 플랫폼의 API는 은행 간 테스트 전용으로 설계됐습니다. 외부 AI 에이전트 프레임워크 — AWS Bedrock, OpenAI Agents SDK, Google Vertex AI 등 — 와의 연동 규격은 아직 공개되지 않았습니다. API 규격이 공개되더라도 인증·인가·속도 제한(rate limiting)·에러 처리 등 프로덕션급 요건까지 갖추려면 상당한 시간이 필요합니다.
진단: 방향은 맞지만, 외부 에이전트가 호출 가능한 공개 API까지는 최소 12~18개월이 필요해 보입니다. 반은 진짜(기술 방향), 반은 아직 계획(구현 수준).
기준 2 — 규제 프레임워크: “AI가 법적으로 돈을 쓸 수 있는가?”
이것이 가장 어려운 문제입니다. 현행 전자금융거래법과 10화에서 다룬 디지털자산기본법은 ‘이용자’를 자연인(개인) 또는 법인으로 정의합니다. AI 에이전트는 둘 다 아닙니다.
에이전트가 결제를 실행할 때 답이 필요한 질문들이 산적합니다.
법적 책임: 에이전트가 잘못된 결제를 실행하면 책임은 에이전트 개발사인가, 사용자인가, 아니면 CBDC 발행 주체(한국은행)인가?
결제 한도: AI 에이전트의 1회·1일 결제 상한은 누가, 어떤 기준으로 설정하는가?
사기 방지: 에이전트가 피싱·사기 사이트에 속아 결제한 경우 취소 절차는?
자금세탁 방지(AML): 에이전트 간 대량 소액 거래가 자금세탁에 악용될 경우 모니터링 방법은?
소비자 보호: 에이전트가 소비자 의사에 반하는 결제를 한 경우 구제 방법은?
이 법적 공백은 한국만의 문제가 아닙니다. 미국, EU, 싱가포르, 일본 어디에서도 “AI 에이전트의 법적 결제 주체성”을 명확히 규정한 법률은 2026년 6월 현재 없습니다. 18화에서 다룬 미국 GENIUS Act도, EU MiCA 규정도 이 부분은 다루지 않았습니다.
진단: 기술보다 규제가 더 늦을 가능성이 높습니다. 법적 프레임워크 마련에 최소 2~3년이 추가로 필요할 것으로 보이며, 이 기간에는 제한된 샌드박스 환경에서만 실험이 가능합니다.
기준 3 — 시장 수요: “누가, 언제 쓸 것인가?”
가장 현실적인 질문입니다. 기술이 있고 규제가 갖춰져도, 쓸 사람(시장)이 없으면 의미가 없습니다.
앞서 살펴본 세 시나리오별 시장 성숙도를 정리하면 이렇습니다.
시나리오
기술 준비도
규제 준비도
시장 수요
예상 시기
A. B2B 공급망 정산
중
중
높음
2027~2028
B. 소비자 AI 비서
중
낮음
중
2029~2030
C. IoT 마이크로페이먼트
낮음
낮음
잠재적 높음
2030 이후
진단: 시장 수요는 분명히 존재하지만, “지금 당장” 대중화될 수요는 아닙니다. B2B 영역이 가장 먼저 움직이고, 소비자 서비스는 3~4년 뒤에나 가시화될 가능성이 높습니다.
종합 판정 — “기술은 진짜, 타이밍은 아직”
세 기준을 종합한 나의 진단은 이렇습니다.
한국은행의 AI 에이전트 실험은 거품이 아니라 방향 탐색이다. 기술적 방향은 정확하고, 글로벌 초기 그룹에 속해 있다는 점에서 유의미하다. 그러나 “내년에 AI가 내 디지털 원화로 장을 본다”라는 수준의 기대는 시기상조다.
더 구체적으로 풀어보면 다음과 같습니다.
기술: 프로그래머블 머니의 기반은 2단계에서 검증됐습니다. 3단계 PoC가 성공하면 기술적 준비도는 크게 올라갑니다. (진짜)
규제: AI 에이전트의 법적 지위 정의가 선행돼야 하며, 이 작업은 어디에서도 완료되지 않았습니다. (미해결)
시장: 킬러 유스케이스는 B2B 정산이 유력하나, 소비자 대중화까지는 거리가 있습니다. (초기)
나는 이렇게 본다: 2027~2028년 사이에 기업 간(B2B) 영역에서 제한적 파일럿이 시작되고, 소비자 대상 서비스는 2029년 이후에나 가시화될 가능성이 있다. 지금 중요한 건 “언제 쓸 수 있나”보다 “표준이 어떻게 정해지는가”를 지켜보는 것이다.
5부를 관통하는 하나의 질문
20화부터 23화까지, 에이전틱 커머스(개념) → x402(프로토콜) → AWS AgentCore(빅테크 인프라) → 프로젝트 한강(중앙은행 실험)을 네 회에 걸쳐 해부했습니다. 이 네 개의 퍼즐을 꿰뚫는 하나의 질문은 이것입니다.
“AI 에이전트 경제의 결제 기축은 달러 스테이블코인이 될 것인가, 각국 CBDC가 될 것인가?”
현재까지의 모멘텀은 달러 스테이블코인 쪽이 압도적입니다. x402는 USDC 기반, AWS AgentCore도 USDC, Stripe의 에이전트 결제 SDK도 USDC를 기본 통화로 채택했습니다. 반면 CBDC 진영은 아직 PoC 단계에 머물러 있습니다.
그러나 두 가지를 기억해야 합니다.
인터넷 결제 초기(1990년대)에도 비슷한 구도가 있었습니다. DigiCash, Flooz, Beenz 같은 민간 디지털 화폐가 먼저 뛰었지만, 결국 규제된 결제 시스템(카드사·은행)이 시장을 가져갔습니다.
중국 e-CNY의 변수: 중국이 AI 에이전트 + e-CNY 조합으로 먼저 대규모 상용화에 성공하면, CBDC 진영의 판도가 급변할 수 있습니다.
결론을 내리기엔 이릅니다. 하지만 한국이 이 경쟁에서 방관자가 돼서는 안 된다는 점은 분명합니다. 프로젝트 한강 3단계의 AI 에이전트 PoC는 그 방관을 거부하는 첫 걸음으로 평가할 수 있습니다.
일반 독자가 지금 주목할 3가지
“나는 개발자도 아니고 금융인도 아닌데, 뭘 봐야 하나?” 일반 독자를 위한 세 가지 관전 포인트를 정리합니다.
1. 프로젝트 한강 3단계 공식 발표를 주시하세요.
2026년 하반기로 예고된 3단계 발표에서 AI 에이전트 PoC의 구체적 범위와 참여 기관이 공개됩니다. 여기서 민간 AI 기업(네이버, 카카오, 통신 3사 등)의 참여 여부가 확인되면, 실현 가능성의 바로미터가 됩니다.
2. 디지털자산기본법 시행령을 함께 보세요.
10화에서 다룬 디지털자산기본법의 시행령 세부 내용에 AI 에이전트의 결제 주체성 관련 조항이 포함될 가능성이 있습니다. 시행령은 법률의 실제 운영 방식을 결정하므로, 법 본문보다 시행령이 더 중요할 수 있습니다.
3. ‘내 AI 비서’에 결제 권한을 줄 준비가 됐는지 스스로 물어보세요.
기술과 규제가 아무리 갖춰져도, 최종 선택은 소비자의 몫입니다. “AI에게 내 돈을 맡겨도 되는가?” — 이 질문에 대한 각자의 답이 시장 수요를 결정합니다. 아직 답이 없어도 괜찮습니다. 지금은 질문을 품고 있는 것만으로 충분합니다.
마무리 — 퍼즐의 마지막 조각
5부(20~23화)를 한 문장으로 요약하면 이렇습니다: AI 에이전트가 스스로 돈을 쓰는 시대는 “올지 안 올지”가 아니라 “언제, 어떤 화폐로” 오는가의 문제다.
스테이블코인이 먼저 달리고, CBDC가 뒤쫓고 있습니다. 한국은행 프로젝트 한강의 AI 에이전트 실험은 거품이 아니라 방향 탐색이며, 그 방향은 정확합니다. 다만 목적지까지의 거리는 아직 상당합니다.
24일 연재의 마지막 퍼즐 조각이 남았습니다.
내일 24화(최종회)에서는 1화부터 23화까지의 여정을 한 장으로 정리하고, “그래서 나는 무엇을 해야 하는가” — 일반 독자를 위한 실질적 행동 가이드를 드립니다.
디스클레이머
본 글은 공개된 보도·자료만을 바탕으로 한 일반 독자용 분석이며, 어떤 기관의 내부 정보도 담고 있지 않습니다. 본 글의 내용은 투자 권유나 자문이 아닙니다. 가상자산·토큰증권·금융상품 투자 결정은 반드시 본인 판단과 자격을 갖춘 전문가(투자권유대행인·세무사·변호사 등)와의 상담을 거쳐 진행하시기 바랍니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: 토큰북: 금융IT 20년차의 디지털 원화 관찰일지 (총 24화 중 23화) ◀ 이전 22화 (다음 차수는 아직 게시되지 않았습니다)
새 프로젝트를 시작할 때마다 찾아오는 익숙한 고민이 있습니다. “데이터베이스는 뭘 쓰지?”, “프론트엔드는 React로 할까, 아니면 요즘 뜬다는 걸로 갈아탈까?”, “AI 도구는 어떤 걸 도입해야 우리 팀에 맞을까?” 2026년 여름 현재, 개발자가 선택할 수 있는 기술 옵션은 역대 최대치를 기록하고 있습니다. GitHub에는 매주 새 프레임워크가 별을 받고, AI 관련 서비스만 해도 수십 개가 치열하게 경쟁 중이죠.
선택지가 풍부한 건 분명 좋은 일입니다. 하지만 그 풍요가 오히려 결정을 가로막기도 합니다. 심리학에서 말하는 ‘선택의 역설(Paradox of Choice)’이 IT 기술 선택에도 정확히 적용됩니다. 선택지가 늘어날수록 결정에 대한 만족도는 떨어지고, 결정을 미루는 시간만 길어집니다. 그래서 많은 개발자와 IT 팀이 결국 “제일 유명한 걸로 하자” 또는 “팀장님이 좋다는 걸로”라는 비체계적인 방식에 기대게 됩니다.
이런 방식이 항상 나쁜 건 아닙니다. 작은 사이드 프로젝트나 되돌리기 쉬운 결정이라면 빠르게 감으로 골라도 괜찮습니다. 하지만 프로젝트 규모가 커지거나, 한번 선택하면 수개월 치 코드가 그 위에 쌓이는 핵심 기술일수록 이야기가 달라집니다. 이 글에서는 기술 선택을 ‘감’이 아닌 구조화된 의사결정 프레임워크로 접근하는 방법을 다룹니다. 그중에서도 실무에서 바로 쓸 수 있는 가중 평가 매트릭스(Weighted Scoring Matrix)를 중심으로, 다음번 기술 선택에서 후회를 줄이는 구체적인 단계를 안내하겠습니다.
왜 ‘감’으로 기술을 고르면 실패 확률이 높을까
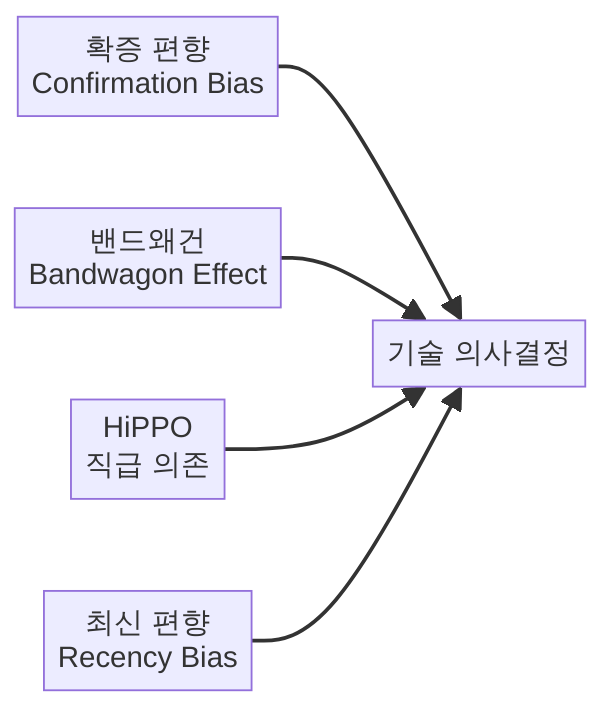
먼저 왜 직관적인 기술 선택이 위험한지부터 짚어볼 필요가 있습니다. 경험 많은 시니어 개발자의 직관은 물론 가치가 있지만, 그 직관조차 여러 인지 편향(cognitive bias)의 영향을 받습니다. 기술 선택에서 흔히 나타나는 편향 네 가지를 살펴보겠습니다.
확증 편향: 이미 마음에 든 기술의 장점만 보인다
확증 편향(Confirmation Bias)은 의사결정에서 가장 흔하고 강력한 함정입니다. 어떤 기술에 호감을 느끼면, 무의식적으로 그 기술에 유리한 벤치마크, 블로그 글, 성공 사례만 찾게 됩니다. 반대로 단점이나 실패 사례는 “우리 경우는 다르지”라며 무시하게 되죠. 예를 들어, 이미 MongoDB에 마음이 끌렸다면 “스키마 유연성”이라는 장점에만 집중하고, 복잡한 조인 쿼리가 필요한 자신의 프로젝트 특성은 간과하기 쉽습니다. 체계적인 프레임워크는 모든 후보를 동일한 기준으로 평가하게 함으로써 이 편향을 줄여줍니다.
밴드왜건 효과: 유행이라고 좋은 건 아니다
“요즘 다들 쓴다더라”는 기술 선택에서 가장 위험한 논거 중 하나입니다. 밴드왜건 효과(Bandwagon Effect)는 많은 사람이 선택했다는 사실 자체가 판단 근거가 되는 현상입니다. 물론 활발한 커뮤니티와 풍부한 레퍼런스는 실질적 장점입니다. 하지만 “유행하는 기술”과 “우리 팀에 맞는 기술”은 전혀 다른 질문입니다. 2024년에 유행한 기술이 2026년에는 유지보수 부담이 된 사례를 한두 개쯤 떠올릴 수 있을 겁니다. 트렌드는 평가 기준 중 하나일 뿐이지, 유일한 기준이 되어서는 안 됩니다.
HiPPO 의사결정: 가장 높은 직급의 의견이 곧 결론
HiPPO(Highest Paid Person’s Opinion)는 조직에서 가장 직급이 높거나 영향력이 큰 사람의 의견이 곧 최종 결정이 되는 현상을 말합니다. CTO가 “우리 팀은 Go로 가자”고 하면 팀원들은 반론을 꺼내기 어렵습니다. 경험에서 나온 판단일 수도 있지만, 때로는 그 경험이 과거의 맥락에 묶여 있을 수도 있죠. 현재 팀의 기술 수준, 프로젝트의 실제 요구사항, 채용 시장의 변화 같은 현실적 요소가 무시될 위험이 있습니다. 의사결정 매트릭스는 논리와 데이터 기반의 대화를 가능하게 해서 직급에 상관없이 근거 있는 의견이 반영될 수 있게 돕습니다.
최신 편향: 새로운 것이 무조건 더 낫다는 착각
최신 편향(Recency Bias)은 최근에 접한 정보나 기술에 과도한 비중을 두는 경향입니다. 어제 컨퍼런스에서 인상적인 데모를 본 기술, 이번 주에 읽은 블로그에서 극찬한 라이브러리가 갑자기 최고의 후보처럼 느껴지죠. 하지만 매력적인 데모와 실제 프로덕션 환경에서의 안정성은 완전히 다른 문제입니다. 프레임워크를 사용하면 일시적인 인상이 아니라 지속적이고 측정 가능한 기준으로 기술을 평가하게 됩니다.
IT 의사결정에 쓸 수 있는 프레임워크 세 가지
그렇다면 어떤 프레임워크를 쓸 수 있을까요? 소프트웨어 엔지니어링과 프로덕트 매니지먼트 분야에서 검증된 세 가지 의사결정 도구를 소개합니다. 각각 적합한 상황이 다르므로, 자신의 상황에 맞는 도구를 골라 쓰면 됩니다.
1. 가중 평가 매트릭스 (Weighted Scoring Matrix)
가중 평가 매트릭스는 여러 후보를 동일한 평가 기준으로 비교할 때 가장 효과적인 도구입니다. 핵심 원리는 단순합니다. 평가 기준을 정하고, 각 기준의 중요도(가중치)를 설정한 뒤, 모든 후보에 동일한 척도로 점수를 매겨 가중 합산하는 것이죠.
이 방법의 가장 큰 장점은 투명성입니다. 왜 A 기술 대신 B를 골랐는지, 어떤 기준이 결정적이었는지가 숫자로 명확하게 남습니다. 팀원 간의 이견이 있을 때 “어떤 기준의 가중치를 다르게 보는가”로 논의를 좁힐 수 있어서, 감정적인 논쟁 대신 건설적인 대화가 가능해집니다.
적합한 상황은 이렇습니다.
데이터베이스, 클라우드 서비스, 프레임워크 등 2개 이상의 후보를 비교할 때
팀 내에서 의견이 갈릴 때 합의의 도구로 활용할 때
선택의 근거를 문서로 남겨야 할 때 (감사, 회고 등)
2. RICE 스코어링
RICE는 Reach(도달 범위), Impact(영향력), Confidence(확신도), Effort(노력)의 약자로, 원래 프로덕트 매니지먼트에서 기능 우선순위를 정하는 데 쓰이는 프레임워크입니다. 하지만 “어떤 기술을 먼저 도입할까?”라는 우선순위 결정에도 효과적으로 활용할 수 있습니다.
RICE 점수는 (Reach × Impact × Confidence) ÷ Effort로 계산합니다. 예를 들어, CI/CD 파이프라인 도입과 코드 리뷰 자동화 도구 도입 중 뭘 먼저 할지 고민이라면, 각각의 RICE 점수를 계산해 더 높은 쪽을 먼저 진행하는 식입니다.
다만 RICE는 “A냐 B냐”의 비교보다는 “무엇을 먼저 하느냐”의 순서 결정에 더 적합합니다. 기술 스택 자체를 고르는 상황보다는 여러 기술 이니셔티브의 실행 순서를 정할 때 빛을 발합니다.
3. ADR (Architecture Decision Records)
ADR(아키텍처 의사결정 기록)은 엄밀히 말해 의사결정 ‘도구’보다는 의사결정을 기록하고 공유하는 형식입니다. 하지만 ADR을 작성하는 과정 자체가 의사결정의 질을 높여주기 때문에 함께 소개합니다.
ADR은 보통 다음 구조를 따릅니다.
제목: 결정의 핵심을 한 줄로
상태: 제안됨 / 수락됨 / 폐기됨 / 대체됨
맥락: 이 결정이 필요한 배경
결정: 무엇을 선택했는가
결과: 이 결정으로 예상되는 장단점
ADR의 진짜 가치는 “6개월 뒤의 나”에게 보내는 편지 역할을 한다는 데 있습니다. 왜 그때 MySQL 대신 PostgreSQL을 골랐는지, 그 맥락을 기록해두면 나중에 상황이 바뀌었을 때 재평가의 출발점이 됩니다. 가중 평가 매트릭스로 결정을 내린 뒤, 그 과정과 결과를 ADR로 기록하는 것이 가장 이상적인 조합입니다.
언제 어떤 프레임워크를 쓸까
세 도구는 서로 경쟁 관계가 아니라 보완 관계입니다. 정리하면 이렇습니다.
후보 비교 (A vs B vs C) → 가중 평가 매트릭스
실행 순서 (뭘 먼저?) → RICE 스코어링
결정 기록 (왜 이걸?) → ADR
이 글에서는 가장 범용적이고 실전 활용도가 높은 가중 평가 매트릭스를 5단계로 나눠서 자세히 다루겠습니다.
가중 평가 매트릭스 5단계 실전 가이드
가중 평가 매트릭스의 원리는 간단하지만, 실제로 효과적으로 활용하려면 각 단계에서 주의할 점이 있습니다. 하나씩 살펴보겠습니다.
1단계: 평가 기준을 정의한다
첫 번째이자 가장 중요한 단계입니다. 어떤 기준으로 기술을 평가할지 정하는 것이죠. 평가 기준이 잘못되면 아무리 점수를 정교하게 매겨도 결과가 의미 없습니다.
IT 기술 선택에서 자주 쓰이는 평가 기준을 유형별로 정리하면 다음과 같습니다.
기술적 기준
성능: 처리 속도, 응답 시간, 동시 처리 능력
확장성: 사용자나 데이터가 늘었을 때 대응 가능한 정도
보안: 알려진 취약점, 보안 업데이트 주기, 인증/인가 지원
호환성: 기존 시스템, 기술 스택과의 통합 용이성
운영적 기준
유지보수 난이도: 디버깅, 모니터링, 업그레이드의 편의성
커뮤니티와 생태계: 라이브러리, 플러그인, 서드파티 도구의 풍부함
문서 품질: 공식 문서의 완성도, 튜토리얼 접근성
인력 확보: 해당 기술을 다룰 수 있는 개발자 채용 용이성
비즈니스 기준
비용: 라이선스, 인프라, 운영에 드는 총 비용(TCO)
학습 곡선: 팀이 생산성을 낼 때까지 걸리는 시간
벤더 종속(Lock-in) 위험: 나중에 다른 기술로 전환할 때의 비용
라이선스: 오픈소스 라이선스 조건이 프로젝트에 부합하는지
여기서 중요한 원칙이 하나 있습니다. 평가 기준은 5~7개로 제한하세요. 기준이 너무 많으면 오히려 의미 있는 차이가 희석됩니다. 10개 기준으로 평가하면 각 기준의 가중치가 평균 10%밖에 되지 않아서, 정말 중요한 요소의 영향력이 줄어듭니다. 프로젝트의 맥락에서 “이것 때문에 프로젝트가 성공하거나 실패한다”고 말할 수 있는 핵심 기준만 남기세요.
2단계: 가중치를 배분한다
기준을 정했으면 각 기준의 상대적 중요도를 수치로 표현합니다. 이것이 가중치(weight)입니다. 가중치의 합은 100%(또는 1.0)이 되게 맞추는 것이 일반적입니다.
가중치 배분에서 가장 흔한 실수는 “다 중요하니까 비슷하게 주자”입니다. 모든 기준에 동일한 가중치를 주면 가중 평가 매트릭스를 쓰는 의미가 사라집니다. 결국 단순 합산과 같아지니까요.
편향을 줄이면서 가중치를 정하는 실용적인 방법 두 가지를 추천합니다.
방법 1: 쌍대 비교(Pairwise Comparison)
모든 기준을 두 개씩 짝지어 “이 둘 중 뭐가 더 중요한가?”를 비교합니다. 5개 기준이면 총 10번의 비교를 하게 됩니다. 각 기준이 “이겼던” 횟수를 세서 비율로 변환하면 자연스러운 가중치가 나옵니다. 이 방법은 한 번에 모든 기준의 중요도를 직관적으로 판단하는 것보다 훨씬 일관된 결과를 만들어줍니다.
방법 2: 100점 배분법(Point Allocation)
100점을 기준들 사이에 자유롭게 나눠주는 방식입니다. 성능이 가장 중요하면 30점, 비용이 그 다음이면 25점, 학습 곡선에 20점… 하는 식이죠. 쌍대 비교보다 직관적이지만, 기준 수가 많으면 배분이 어려워지는 단점이 있습니다. 기준이 5개 이하일 때 추천하는 방법입니다.
팀으로 결정할 때는 각 팀원이 독립적으로 가중치를 매긴 뒤 평균을 내는 것이 좋습니다. 먼저 누군가의 가중치를 보여주면 앵커링 효과로 다른 사람의 판단이 끌려가거든요. 각자 적은 뒤 한꺼번에 공개하면 이 문제를 줄일 수 있습니다.
3단계: 후보 기술을 나열한다
비교할 기술 후보 목록을 만듭니다. 여기서도 몇 가지 원칙이 있습니다.
후보는 3~5개로 제한합니다. 7개 이상이면 비교 자체가 부담이 됩니다. 사전 조사를 통해 명백히 부적합한 후보는 먼저 걸러내세요.
같은 카테고리의 기술만 비교합니다. PostgreSQL과 Redis를 비교하는 건 의미가 없습니다. 둘은 해결하는 문제가 다르니까요. “관계형 데이터베이스 중에서” 또는 “인메모리 캐시 중에서”처럼 범위를 맞추세요.
“현상 유지”도 후보에 넣으세요. 새 기술 도입을 검토하는 상황이라면 “지금 쓰는 기술을 계속 쓴다”는 선택지도 비교 대상에 포함해야 합니다. 이걸 빼면 ‘바꿔야 한다’는 전제가 무의식적으로 깔리게 됩니다.
4단계: 점수를 매긴다
각 후보 기술에 대해 모든 평가 기준별로 점수를 매깁니다. 보통 1~5점 또는 1~10점 척도를 사용합니다. 5점 척도를 추천하는데, 10점 척도는 6점과 7점의 차이를 설명하기 어려운 경우가 많아서 오히려 노이즈가 생깁니다.
점수 매기기에서 핵심적인 주의사항 세 가지입니다.
첫째, 척도의 의미를 미리 정의하세요. “3점이 뭘 뜻하는가”를 사전에 합의하지 않으면 사람마다 다른 기준으로 점수를 매기게 됩니다. 예를 들어 성능 기준의 경우 “1점: 벤치마크 하위 20%, 3점: 중간, 5점: 해당 카테고리 최상위”처럼 구체적인 앵커를 잡아두면 일관성이 올라갑니다.
둘째, 감이 아니라 근거를 기록하세요. “이 기술의 커뮤니티 활성도에 4점을 줬다”면, 그 근거가 뭔지 메모를 남겨야 합니다. GitHub 스타 수, Stack Overflow 질문 빈도, 공식 Discord/Slack 멤버 수 같은 객관적 지표가 있으면 더 좋습니다. 이 기록이 있어야 나중에 “왜 그때 이 점수를 줬지?”라는 의문에 답할 수 있습니다.
셋째, 독립 평가 후 합산하세요. 앞서 가중치 배분에서도 언급했지만, 팀 평가 시에는 반드시 각자 독립적으로 점수를 매긴 뒤 합산해야 합니다. 한 사람이 먼저 점수를 공개하면 나머지 사람의 판단이 그쪽으로 편향됩니다.
5단계: 가중 점수를 계산하고 민감도를 분석한다
각 기준의 점수에 해당 기준의 가중치를 곱한 뒤 합산하면 최종 가중 점수가 나옵니다. 가장 높은 점수를 받은 기술이 가중 평가 매트릭스가 추천하는 선택지입니다.
하지만 여기서 한 단계 더 나가야 합니다. 민감도 분석(Sensitivity Analysis)입니다. 이것은 “가중치나 점수가 조금 달라졌을 때 결과가 바뀌는가?”를 확인하는 작업입니다.
예를 들어, A 기술이 78점이고 B 기술이 76점이라면 사실상 무의미한 차이입니다. 이때 가장 가중치가 높은 기준의 점수를 1점씩 변동시켜 보세요. A와 B의 순위가 자주 뒤집힌다면 이 두 기술은 “매트릭스로는 구분이 안 되는 수준”이라는 뜻입니다. 이 경우에는 매트릭스 외의 요소, 예를 들어 팀의 기존 경험이나 기술적 친밀도 같은 정성적 요소로 최종 결정을 내리면 됩니다.
반대로, A 기술이 82점이고 B 기술이 65점이라면 가중치를 상당히 변경해도 순위가 뒤집히지 않습니다. 이런 경우가 매트릭스가 확실한 답을 주는 케이스이며, 자신 있게 A를 선택할 수 있습니다.
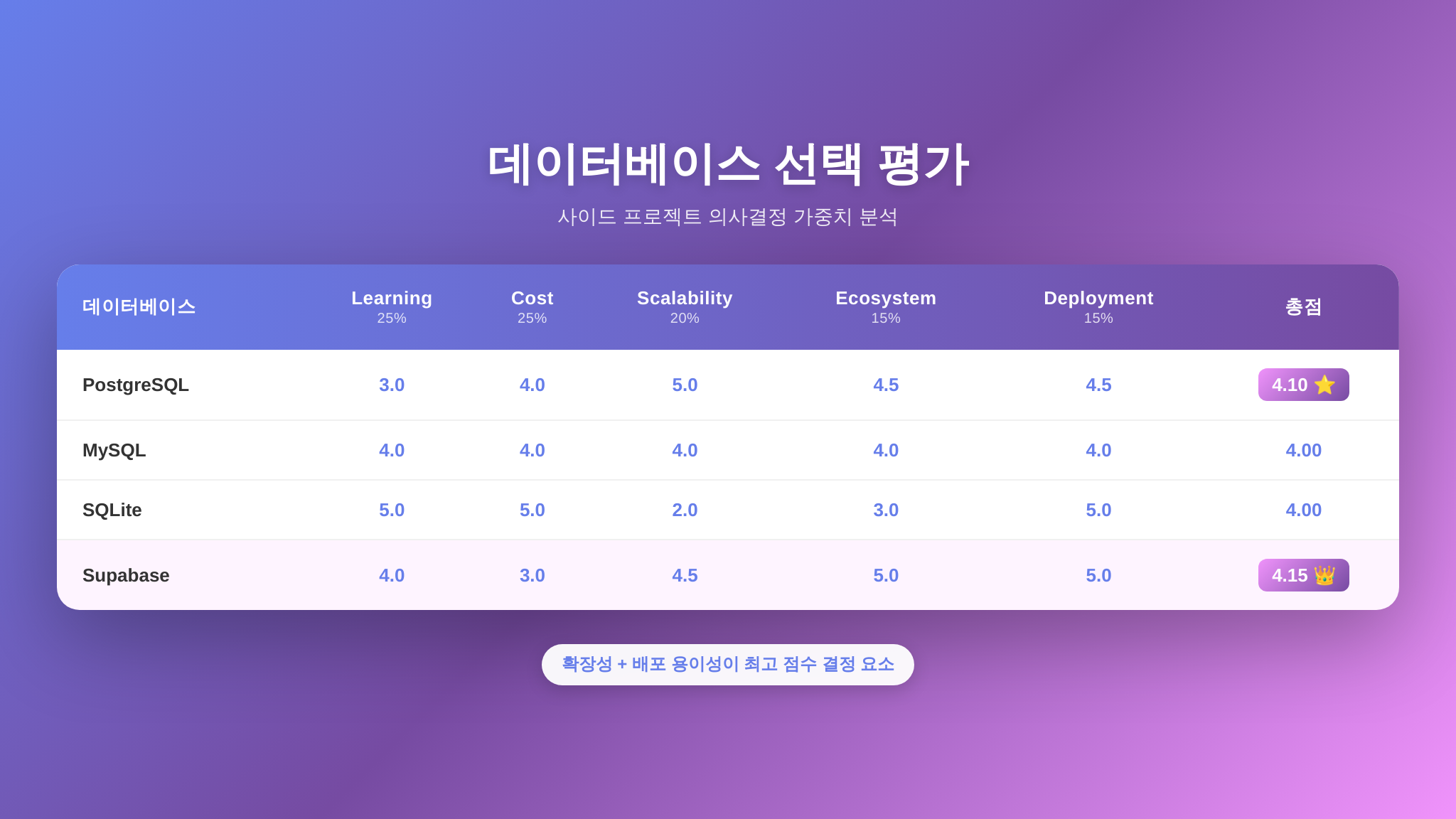
실전 예시: 사이드 프로젝트 데이터베이스 고르기
이론만으로는 와닿지 않을 수 있으니, 구체적인 예시를 하나 만들어 보겠습니다. 2026년 여름, 개인 사이드 프로젝트의 데이터베이스를 선택하는 상황을 가정해 봅니다.
프로젝트 배경: 개인 독서 기록 및 AI 기반 요약 관리 웹앱. 1인 개발, 사용자 수 초기 100명 이하, 배포는 클라우드(Vercel/Railway 등), 추후 확장 가능성은 열어둠.
후보 기술 4가지
PostgreSQL: 오픈소스 관계형 DB의 대표. 풍부한 기능, 강력한 생태계.
MySQL: 가장 오래되고 널리 쓰이는 관계형 DB. 단순하고 빠른 읽기 성능.
SQLite: 파일 기반 경량 DB. 서버가 필요 없어 초기 비용 제로.
Supabase: PostgreSQL 기반 BaaS(Backend as a Service). 인증, 스토리지, 실시간 구독까지 올인원.
평가 기준과 가중치 (100점 배분법 사용)
학습 곡선 (25%): 혼자 개발하므로 빠르게 익힐 수 있는 게 중요
비용 (25%): 사이드 프로젝트이므로 무료 또는 최저 비용 선호
확장성 (20%): 사용자가 늘어날 가능성에 대비
생태계/ORM 지원 (15%): 선호하는 언어/프레임워크와의 호환성
배포 편의성 (15%): 클라우드에 쉽게 올릴 수 있는지
점수 매기기 (1~5점, 근거 메모 포함)
학습 곡선에서 SQLite는 설정이 거의 없으므로 5점, Supabase는 대시보드가 직관적이므로 4점, PostgreSQL은 기능이 많은 만큼 초기 학습량도 있어서 3점, MySQL도 비슷하게 3점을 부여합니다.
비용에서 SQLite는 파일 기반이므로 서버 비용이 0원에 가까워 5점, PostgreSQL과 MySQL은 무료 티어가 있는 클라우드 호스팅(Neon, PlanetScale 등)을 쓰면 초기 무료이므로 4점, Supabase는 무료 티어가 넉넉하므로 4점을 줍니다.
확장성에서 PostgreSQL은 5점(수직·수평 확장 모두 강력), Supabase도 PostgreSQL 기반이라 4점, MySQL은 4점, SQLite는 동시 쓰기에 약해서 2점입니다.
생태계/ORM 지원에서 PostgreSQL은 거의 모든 ORM이 지원하므로 5점, MySQL도 5점, Supabase는 자체 클라이언트 + PostgreSQL ORM 가능이라 4점, SQLite는 대부분 ORM이 지원하나 일부 기능 제한으로 4점입니다.
배포 편의성에서 Supabase는 관리형 서비스라 5점, SQLite는 파일 복사만 하면 되니 4점이지만 클라우드 환경에서 영속 스토리지 이슈가 있어 3점으로 조정, PostgreSQL은 Neon이나 Railway로 원클릭 배포 가능하므로 4점, MySQL도 비슷하게 4점입니다.
Supabase가 4.15점으로 1위, PostgreSQL이 4.10점으로 근소한 2위입니다. 이 0.05점 차이는 의미 있을까요? 민감도 분석을 해봅시다. 학습 곡선의 가중치를 25%에서 15%로, 확장성을 20%에서 30%로 바꾸면 PostgreSQL이 역전합니다. 즉, 이 두 기술은 매트릭스만으로는 확실한 우열을 가리기 어려운 수준입니다.
이럴 때는 정성적 요소를 고려합니다. “PostgreSQL을 직접 다뤄보며 데이터베이스를 깊이 배우고 싶다”면 PostgreSQL, “빠르게 프로토타입을 만들고 인증·스토리지 같은 부가 기능도 편하게 쓰고 싶다”면 Supabase를 고르면 됩니다. 핵심은 두 기술 모두 합리적인 선택이라는 점을 매트릭스가 확인해줬다는 데 있습니다. 어느 쪽을 골라도 “완전히 잘못된 결정”은 아닌 것이죠.
반면 MySQL과 SQLite는 이 프로젝트 맥락에서는 상위 두 후보보다 약간 뒤처지는 것이 숫자로 드러났습니다. 감으로 “MySQL이 제일 안전하지 않을까?”라고 느꼈더라도, 실제 평가 기준에 비추면 이 프로젝트에는 최적이 아닐 수 있다는 판단이 가능해지는 겁니다.
의사결정 프레임워크를 쓸 때 빠지기 쉬운 함정 다섯 가지
가중 평가 매트릭스가 만능은 아닙니다. 도구를 잘못 쓰면 오히려 잘못된 결정에 “분석적으로 검증됨”이라는 가짜 권위를 씌우는 결과가 됩니다. 흔히 빠지는 함정 다섯 가지를 미리 알아두세요.
함정 1: 원하는 결과에 맞춰 가중치를 역설계한다
가장 위험한 함정입니다. 이미 마음속으로 고른 기술이 있고, 그 기술이 1등을 하도록 가중치를 조정하는 것이죠. 이렇게 되면 프레임워크는 편향을 감추는 도구로 전락합니다. 예방법은 간단합니다. 가중치를 먼저 정한 뒤에 점수를 매기세요. 가중치를 정할 때는 아직 후보 기술의 점수를 알면 안 됩니다. 순서가 생명입니다.
함정 2: 정량화할 수 없는 요소를 무시한다
매트릭스는 숫자로 표현되는 것에 강합니다. 하지만 기술 선택에는 “팀의 사기”, “기술적 호기심”, “개발자 경험(DX)의 즐거움” 같은 정성적 요소도 중요합니다. 이런 요소들을 아예 무시하면 숫자적으로는 최적이지만 팀이 쓰기 싫어하는 기술을 고르게 될 수 있습니다. 정성적 요소는 매트릭스 바깥에서 별도로 논의하되, 최종 결정에 반영하세요.
함정 3: 모든 결정에 매트릭스를 꺼낸다
로깅 라이브러리를 고르는 데 2시간짜리 가중 평가를 할 필요는 없습니다. 아마존 창업자 제프 베이조스의 “되돌릴 수 있는 결정(Type 2)”과 “되돌릴 수 없는 결정(Type 1)” 구분이 여기서 유용합니다. Type 2 결정(나중에 바꿀 수 있는 것)은 빠르게 감으로 내리고, Type 1 결정(바꾸려면 대규모 리팩토링이 필요한 것)에만 매트릭스를 투자하세요.
기술 선택에서 Type 1에 해당하는 것들은 이런 것입니다.
프로그래밍 언어 (전체 코드베이스 재작성 필요)
데이터베이스 엔진 (데이터 마이그레이션 비용 막대)
클라우드 공급자 (벤더 종속 위험)
핵심 프레임워크 (컨트롤러/모델/라우팅 전체 교체)
반면 Type 2에 해당하는 것들은 이렇습니다.
HTTP 클라이언트 라이브러리 (인터페이스 래핑하면 교체 용이)
포매터/린터 (설정 파일 교체로 전환 가능)
테스트 프레임워크 (기존 테스트 대부분 재활용 가능)
CSS 프레임워크 (컴포넌트 단위 점진 교체 가능)
함정 4: 평가 시점의 스냅샷만 보고 결정한다
기술 생태계는 빠르게 변합니다. 오늘 커뮤니티가 활발한 기술이 1년 뒤에도 그럴 거라는 보장은 없습니다. 매트릭스 점수를 매길 때 현재 상태뿐 아니라 추세(trend)도 함께 고려하세요. GitHub 스타의 절대 수보다 최근 6개월간의 증가율이 더 의미 있는 지표일 수 있습니다. 릴리스 주기, 주요 스폰서의 안정성, 핵심 메인테이너의 활동 빈도 같은 프로젝트 건강 지표를 함께 보면 미래 리스크를 줄일 수 있습니다.
함정 5: 결정을 기록하지 않는다
매트릭스를 열심히 만들어 놓고 스프레드시트를 그냥 닫아버리는 경우가 놀라울 정도로 많습니다. 6개월 뒤 “왜 이 기술을 골랐지?”라는 질문이 반드시 나옵니다. 앞서 소개한 ADR 형식으로 결정의 맥락, 매트릭스 결과, 최종 선택 이유를 기록해두세요. 미래의 자신이나 합류할 새 팀원에게 큰 도움이 됩니다.
결정 이후가 더 중요합니다
의사결정 프레임워크는 최적의 답을 보장하는 마법이 아닙니다. 불확실성 속에서 “합리적으로 방어 가능한 선택”을 도와주는 도구입니다. 완벽한 결정은 없습니다. 하지만 체계적으로 내린 결정에는 두 가지 분명한 이점이 있습니다.
첫째, 실행에 확신을 갖게 됩니다. “이유 있는 결정”이라는 자각은 이후 개발 과정에서 불필요한 의심과 번복을 줄여줍니다. “다른 걸 골랐어야 했나?”라는 생각이 떠올라도 매트릭스를 다시 꺼내 보면 됩니다. 상황이 진짜 바뀌었다면 그때 재평가하면 되고, 바뀌지 않았다면 원래 결정을 신뢰하면 됩니다.
둘째, 팀의 의사결정 역량이 축적됩니다. ADR로 기록된 결정들은 조직의 판단 이력이 됩니다. 새로운 기술 선택 상황이 왔을 때 과거 기록을 참고하면 같은 시행착오를 반복하지 않게 됩니다. 그리고 이런 프레임워크를 반복적으로 사용하면 팀 전체가 구조적으로 사고하는 습관을 기르게 됩니다.
이번 여름, 새 프로젝트를 시작하거나 기술 스택을 재검토할 계획이 있다면 스프레드시트를 하나 열어보세요. 기준 5개를 정하고, 가중치를 배분하고, 후보 3개에 점수를 매기는 데 30분이면 충분합니다. 그 30분이 앞으로 수개월간의 개발 방향을 결정하는 가장 가치 있는 투자가 될 수 있습니다. 감으로 고르는 시대는 지나갔습니다. 데이터와 구조로 기술을 선택하세요.
이 글은 AI Harness: 모델보다 래퍼 시리즈의 6/12화입니다. 지난 5화에서 MCP와 도구 인터페이스 — 하니스의 손과 발 — 을 살펴봤습니다. 이제 에이전트에게 기억을 선사할 차례입니다.
도구 다음은 기억이다 — 왜 메모리인가
5화를 마치며 우리는 에이전트에게 MCP를 통한 도구 호출 능력을 부여했습니다. 파일을 읽고, 데이터베이스를 조회하고, API를 호출할 수 있게 됐죠. 하지만 여기서 한 가지 불편한 질문이 남습니다.
“아무리 유능한 손과 발이 있어도, 뭘 하고 있었는지 잊어버리면 무슨 소용인가?”
LLM은 본질적으로 무상태(stateless)입니다. 매 요청마다 백지 상태에서 시작합니다. 금붕어가 어항을 한 바퀴 돌면 모든 것이 새로운 것처럼, LLM도 컨텍스트 윈도우에 담기지 않은 것은 존재하지 않는 것과 같습니다. 이것이 바로 골드피시 문제(Goldfish Problem)입니다.
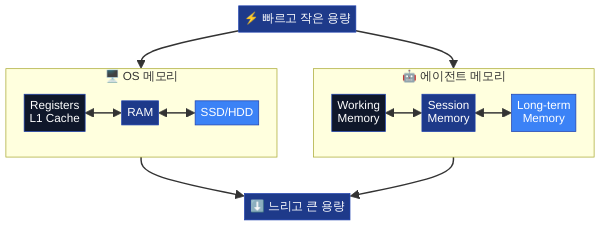
4화에서 다뤘던 비유를 떠올려 봅시다. LLM이 CPU라면, 컨텍스트 윈도우는 RAM이고, 에이전트 하니스(Agent Harness)는 OS입니다. 그런데 OS가 메모리 관리를 하지 않는다면? 프로그램 하나 실행할 때마다 이전 데이터가 사라지고, 파일 시스템도 없고, 캐시도 없는 컴퓨터를 상상해 보세요. 바로 그것이 메모리 아키텍처가 없는 에이전트의 현실입니다.
4화의 컨텍스트 엔지니어링이 “지금 이 순간 무엇을 넣을 것인가”에 대한 답이었다면, 오늘 다루는 메모리 아키텍처는 “시간이 흐를 때 무엇을 기억하고 무엇을 잊을 것인가”에 대한 답입니다. 컨텍스트 엔지니어링이 공간의 문제라면, 메모리 아키텍처는 시간의 문제입니다.
정의 — 에이전트 메모리 아키텍처란 무엇인가
에이전트 메모리 아키텍처(Agent Memory Architecture)란, AI 에이전트가 과거의 상호작용·학습된 사실·현재 작업 상태를 구조적으로 저장·검색·폐기하는 체계를 말합니다. 단순히 “대화 이력을 저장한다”와는 차원이 다릅니다.
인간의 기억 체계를 떠올려 보세요. 인지심리학의 앳킨슨-시프린 모델(Atkinson-Shiffrin Model, 1968)은 인간 기억을 세 가지 저장소로 분류합니다:
감각 기억(Sensory Memory): 수백 밀리초 동안 유지되는 원시 입력
단기 기억(Short-term Memory): 약 20~30초, 용량 7±2 항목
장기 기억(Long-term Memory): 사실상 무제한 용량, 영구 저장
에이전트 하니스의 메모리 아키텍처는 이 인지 모델을 소프트웨어로 재현합니다. 다만 우리의 비유 체계에서는 OS의 메모리 계층과 대응시키는 편이 더 정확합니다:
OS 메모리 계층
에이전트 메모리
역할
특성
CPU 레지스터 / L1 캐시
Working Memory (작업 메모리)
현재 턴의 작업 상태
극소 용량, 극고속, 매 턴 갱신
RAM
Session Memory (세션 메모리)
현재 대화의 이력
중간 용량, 세션 종료 시 소멸 가능
SSD / HDD
Long-term Memory (장기 메모리)
프로젝트 지식, 사용자 선호, 학습된 패턴
대용량, 영구, 검색 비용 존재
가상 메모리 (스왑)
Memory Compression (메모리 압축)
세션 메모리 초과 시 요약·압축
정보 손실 감수, 용량 확보
이 세 계층이 독립적으로 존재하되, 하니스의 메모리 매니저가 계층 간 데이터 이동(승격·강등·폐기)을 관장합니다. 마치 OS의 메모리 관리 유닛(MMU)이 물리 메모리와 가상 메모리 사이의 페이지를 스와핑하듯이요.
메모리 아키텍처가 컨텍스트 엔지니어링과 다른 점
4화에서 다룬 컨텍스트 엔지니어링은 “지금 이 API 호출에 어떤 정보를 담을 것인가”라는 정적 최적화입니다. 반면 메모리 아키텍처는 “연속된 여러 턴에 걸쳐 정보를 어떻게 유지·갱신·검색할 것인가”라는 동적 관리입니다. 컨텍스트 엔지니어링이 한 프레임의 구도라면, 메모리 아키텍처는 영화 전체의 편집입니다.
이 구분이 중요한 이유는, 많은 에이전트 프레임워크가 컨텍스트 엔지니어링만 신경 쓰고 메모리 아키텍처를 방치하기 때문입니다. 결과적으로 단발 질의에는 뛰어나지만, 10턴 이상의 복합 작업에서 급격히 품질이 하락하는 에이전트가 만들어집니다. 88%의 에이전트 프로젝트가 프로덕션에 도달하지 못하는 원인 중 상당 부분이 여기에 있습니다.
메모리가 없으면 무엇이 깨지는가 — 실패의 4가지 증상
메모리 아키텍처가 부재하거나 잘못 설계된 에이전트는 다음 네 가지 증상을 반드시 보입니다. 프로덕션 AI 에이전트를 운영해 본 사람이라면 적어도 하나는 뼈저리게 공감할 겁니다.
증상 1: 반복 질문 — “이거 아까 말씀드렸는데요”
고객 지원 챗봇을 떠올려 보세요. 사용자가 “주문번호는 A12345입니다”라고 말했는데, 5턴 뒤에 봇이 “주문번호를 알려주시겠어요?”라고 다시 묻습니다. 사용자 입장에서 이보다 짜증나는 경험은 없습니다.
이 증상은 작업 메모리(Working Memory)의 부재에서 옵니다. 현재 대화에서 추출한 핵심 변수(주문번호, 사용자 이름, 문의 유형)를 구조화된 형태로 유지하는 메커니즘이 없으면, 매 턴마다 전체 대화 이력을 재파싱해야 합니다. 대화가 길어질수록 핵심 정보가 노이즈 속에 묻히고, 결국 모델이 “잊어버리는” 것처럼 보입니다.
증상 2: 컨텍스트 부패 — 대화가 길어질수록 멍청해진다
이 시리즈에서 반복 등장하는 용어, 컨텍스트 부패(Context Rot)입니다. 3화에서 처음 소개했던 이 현상은 메모리 아키텍처와 가장 직접적으로 연관됩니다.
세션 메모리를 “전체 대화 이력을 그대로 쌓기”로 구현하면 어떻게 될까요? 처음 10턴까지는 완벽합니다. 하지만 30턴, 50턴이 되면 컨텍스트 윈도우의 상당 부분이 과거 대화로 채워집니다. 모델이 추론에 사용할 수 있는 토큰 예산이 줄어들고, 오래된 대화의 노이즈가 현재 작업의 정확도를 떨어뜨립니다.
실제 측정 결과, 압축 없이 전체 이력을 유지하는 에이전트는 50턴 시점에서 정확도가 턴 1 대비 약 69% 하락했습니다. 반면 3계층 메모리 + 압축을 적용한 에이전트는 같은 시점에서 13% 하락에 그쳤습니다. 이것이 메모리 아키텍처의 힘입니다.
증상 3: 프로젝트 지식 소실 — 매번 처음부터
“이 프로젝트는 FastAPI 기반이고, Python 3.11을 쓰고, 테스트는 pytest로 하고, ruff로 린트합니다.” 이 정보를 매 세션 시작할 때마다 에이전트에게 다시 알려줘야 한다면? 그것은 장기 메모리의 부재입니다.
코딩 에이전트의 경우 이 증상이 특히 치명적입니다. 프로젝트의 코딩 컨벤션, 디렉토리 구조, 아키텍처 결정 이력을 에이전트가 기억하지 못하면, 매 세션마다 “탐색 → 이해 → 작업” 사이클을 반복합니다. 사실상 경험이 쌓이지 않는 인턴과 다를 바 없습니다.
실제로 이 문제 때문에 코딩 에이전트 사용자들 사이에서 CLAUDE.md, .cursorrules, AGENTS.md 같은 “부트 메모리” 파일이 급속히 확산되었습니다. 이것은 사용자가 장기 메모리의 부재를 수작업으로 보완하는 패턴이며, 후반부에서 자세히 다루겠습니다.
증상 4: 토큰 폭주 — 기억 대신 원문을 매번 재전송
메모리가 없는 에이전트는 “혹시 모르니까” 모든 관련 문서를 매 턴마다 컨텍스트에 다시 집어넣습니다. 이것이 바로 2화에서 소개한 토큰 사용량의 극적인 차이와 직결됩니다.
같은 작업을 수행할 때 Claude Code는 평균 33K 토큰을, Cursor는 188K 토큰을 사용합니다. 5.5배 차이. 이 격차의 상당 부분은 메모리 아키텍처의 차이에서 옵니다. Claude Code는 이미 파악한 정보를 작업 메모리에 보관하고 필요할 때만 참조합니다. 반면 덜 정교한 하니스는 “방금 읽은 파일을 잊어버릴까 봐” 매 턴 전체를 다시 전송합니다.
이것은 비용의 문제이기도 합니다. 달러당 정확도에서 복잡한 멀티파일 작업 기준 Claude Code가 8.5점, Cursor가 6.2점을 기록하는 이유 중 하나입니다. 기억하는 에이전트는 저렴하고, 잊어버리는 에이전트는 비싸다.
영문 1차 자료 — MemGPT: “LLM을 운영체제처럼”
에이전트 메모리 아키텍처를 학술적으로 공식화한 가장 중요한 논문은 Charles Packer 외의 “MemGPT: Towards LLMs as Operating Systems”(2023, ICLR 2024 채택)입니다. 한국어로 이 논문의 핵심을 제대로 다룬 글은 아직 드문데, 이 논문은 본 시리즈의 OS 비유와 놀라울 정도로 정확히 겹칩니다.
Packer 팀의 핵심 통찰은 이것입니다:
“Traditional operating systems manage the movement of data between fast (RAM) and slow (disk) memory tiers. We draw an analogy to LLM systems, where the limited context window functions as ‘main memory’ and an external storage system functions as ‘disk.’ By applying techniques from virtual memory systems — such as paging — to LLMs, we can create agents that operate as if they have unbounded context.”
— Packer et al., MemGPT, 2023
번역하면: “전통적 운영체제가 빠른 메모리(RAM)와 느린 메모리(디스크) 사이의 데이터 이동을 관리하듯, LLM 시스템에서도 제한된 컨텍스트 윈도우를 ‘메인 메모리’로, 외부 저장소를 ‘디스크’로 간주할 수 있다. 가상 메모리 기법 — 페이징 등 — 을 LLM에 적용하면, 사실상 무한한 컨텍스트를 가진 것처럼 작동하는 에이전트를 만들 수 있다.”
MemGPT가 제안한 구체적 메커니즘을 정리하면:
메인 컨텍스트(Main Context): LLM의 컨텍스트 윈도우. OS의 RAM에 해당. 용량이 제한적이므로 가장 관련도 높은 정보만 유지.
외부 컨텍스트(External Context): 벡터 DB, 파일 시스템, 데이터베이스 등. OS의 디스크에 해당. 사실상 무제한이지만 접근 비용(검색 지연 + 토큰)이 있음.
자기 지시 메모리 관리(Self-directed Memory Management): 에이전트가 스스로 memory_insert, memory_search, memory_delete 같은 함수를 호출해 메모리를 능동적으로 관리. 이것이 핵심입니다. OS가 페이지 폴트를 처리하듯, 에이전트가 메모리 부족을 감지하고 스스로 페이지 인/아웃을 수행합니다.
내부 독백(Inner Monologue): 에이전트의 메모리 관리 추론 과정. “이 정보는 나중에 필요할 것 같으니 장기 메모리에 저장하자”, “이 대화 내역은 핵심만 요약하고 원본은 아카이브하자”와 같은 자기 대화.
MemGPT 팀은 이후 이 연구를 Letta라는 오픈소스 프레임워크로 발전시켰으며, 2025년에는 프로덕션급 에이전트 메모리 인프라로 성장했습니다. 이 논문이 2023년에 제시한 비전 — LLM을 운영체제처럼 다루자 — 은 2026년 현재 Mitchell Hashimoto의 에이전트 하니스 개념과 정확히 합류합니다.
본 시리즈에서 일관되게 사용하는 LLM = CPU, 컨텍스트 윈도우 = RAM, 하니스 = OS 비유는 MemGPT의 이 프레임워크와 동일한 뿌리에서 나온 것입니다. 학술적으로 검증된 비유라는 점에서 자신감을 가져도 좋습니다.
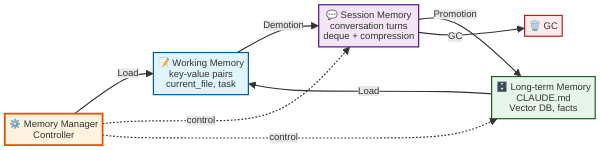
패턴 1 — 3계층 분리 아키텍처
이제 실전으로 들어갑시다. 첫 번째 설계 패턴은 메모리를 Working · Session · Long-term 세 계층으로 명시적으로 분리하는 것입니다. 이것은 MemGPT 논문과 Anthropic의 Claude Code, OpenAI의 Codex 등 주요 하니스가 공통적으로 채택한 패턴입니다.
Working Memory — CPU 레지스터의 역할
작업 메모리는 현재 턴에서 에이전트가 즉시 접근해야 하는 상태 변수입니다. OS 비유로는 CPU 레지스터와 L1 캐시에 해당합니다.
구체적으로 무엇이 들어가는가:
현재 작업 정의: “사용자가 config.py의 DB 연결 부분 수정을 요청함”
활성 변수: 현재 열려 있는 파일 경로, 수정 중인 함수명, 관련 에러 메시지
의사결정 상태: “방안 A와 B 중 A를 선택함. 이유: 성능 우선”
체크리스트: 현재 작업의 완료/미완료 항목
작업 메모리의 핵심 원칙은 구조화입니다. 자유 형식 텍스트가 아니라, 키-값 쌍이나 구조화된 스키마로 유지합니다. 이렇게 해야 모델이 컨텍스트에서 빠르게 정보를 찾을 수 있고, 업데이트도 정밀하게 할 수 있습니다.
# Working Memory의 구조화 예시
working_memory = {
"task": "config.py DB 연결 마이그레이션",
"current_file": "src/config.py",
"target_function": "create_db_engine",
"decision": "asyncpg → psycopg3 전환 (async 지원 유지)",
"blockers": ["테스트 DB 미설정"],
"completed": ["의존성 조사", "마이그레이션 계획 수립"],
"remaining": ["코드 수정", "테스트 작성", "문서 갱신"]
}
이 작업 메모리는 매 턴 시작 시 컨텍스트의 상단(또는 시스템 프롬프트 바로 뒤)에 주입됩니다. 4화에서 다뤘던 추론 샌드위치(Reasoning Sandwich) 패턴의 “상단 빵” 역할을 하는 셈입니다.
Session Memory — RAM의 역할
세션 메모리는 현재 대화 세션의 이력입니다. 사용자와 에이전트가 주고받은 메시지, 도구 호출 결과, 에이전트의 추론 과정 등이 포함됩니다.
가장 단순한 구현은 “모든 메시지를 리스트에 추가”입니다. 하지만 이 접근은 앞서 본 컨텍스트 부패를 일으킵니다. 따라서 실전에서는 다음과 같은 전략이 필요합니다:
슬라이딩 윈도우(Sliding Window): 최근 N개의 턴만 유지. 가장 단순하지만 오래된 중요 정보를 잃음.
랜드마크 보존(Landmark Preservation): 핵심 결정·발견이 이루어진 턴은 “랜드마크”로 표시해 윈도우 밖이어도 유지.
요약 체인(Summary Chain): 오래된 턴을 요약문으로 교체. 정보 밀도를 유지하면서 토큰을 절약.
계층 강등(Tier Demotion): 충분히 오래된 턴의 핵심 사실을 장기 메모리로 이동시키고 원본 삭제.
Claude Code의 세션 메모리 관리가 좋은 참고 사례입니다. Claude Code는 대화가 길어지면 자동으로 이전 메시지를 압축합니다. “The system will automatically compress prior messages in your conversation as it approaches context limits.” 이것은 정확히 OS의 메모리 스왑과 동일한 메커니즘입니다 — 자주 접근하지 않는 페이지를 디스크로 내려 RAM 공간을 확보하는 것이죠.
중요한 설계 포인트는 무엇을 압축하고 무엇을 보존할 것인가의 기준입니다:
보존 우선 (압축 비대상)
압축 대상
즉시 폐기 가능
사용자의 원래 요청
도구 호출의 전체 출력
중간 시행착오 (취소된 접근)
핵심 의사결정과 그 근거
탐색적 코드 읽기 결과
형식적 인사·확인 메시지
에러 메시지와 해결 과정
반복적 패턴의 도구 결과
재생성 가능한 코드 스니펫
사용자 피드백 / 수정 요청
긴 파일 내용 (경로만 보존)
시스템 상태 체크 결과
Long-term Memory — SSD/HDD의 역할
장기 메모리는 세션을 넘어 영구적으로 유지되는 지식입니다. OS의 파일 시스템과 같습니다. 전원을 꺼도 (세션이 끝나도) 살아남는 데이터입니다.
장기 메모리에 저장되는 것들:
프로젝트 메타데이터: 기술 스택, 디렉토리 구조, 코딩 컨벤션, 아키텍처 결정
사용자 선호: 코드 스타일, 커밋 메시지 포맷, 선호하는 라이브러리
학습된 패턴: “이 프로젝트에서는 X 대신 Y를 쓴다”, “이 API는 Z 형식으로 응답한다”
과거 세션의 핵심 요약: 이전 작업의 결과와 교훈
도메인 지식: 비즈니스 규칙, 외부 API 사양, 팀 규칙
장기 메모리의 저장 매체는 다양합니다:
파일 기반: CLAUDE.md, .cursorrules, AGENTS.md — 가장 단순하고 투명. 버전 관리 가능. 다음 패턴에서 자세히 다룸.
벡터 데이터베이스: 임베딩으로 변환해 시멘틱 검색. Pinecone, Weaviate, Chroma 등. 대규모 지식 베이스에 적합.
관계형 데이터베이스: 구조화된 사실을 정확히 검색. 세션 이력 영속화에 적합.
키-값 저장소: Redis 등. 빠른 조회가 필요한 사용자 설정에 적합.
장기 메모리의 핵심 과제는 검색(Retrieval)입니다. 10만 개의 사실이 저장되어 있어도, 지금 이 턴에 필요한 5개를 정확히 가져오지 못하면 의미가 없습니다. 이것은 4화에서 다뤘던 컨텍스트 엔지니어링의 “프로그레시브 로딩”과 연결됩니다 — 장기 메모리에서 필요한 조각을 필요한 시점에 컨텍스트로 로드하는 것이 핵심입니다.
계층 간 데이터 흐름 — 승격과 강등
세 계층은 독립적이되, 데이터가 계층 사이를 오갑니다:
승격(Promotion): Session → Long-term. 여러 세션에 걸쳐 반복 참조되는 사실을 장기 메모리로 승격. 예: “이 프로젝트는 항상 ruff format을 적용한다”가 세 번의 세션에서 반복되면 장기 메모리에 기록.
강등(Demotion): Session → 요약/삭제. 오래된 세션 메모리를 요약해 토큰 예산을 확보.
로드(Load): Long-term → Working. 장기 메모리에서 현재 작업에 관련된 사실을 작업 메모리로 로드. 예: 사용자가 “DB 스키마 수정”을 요청하면 장기 메모리에서 “이 프로젝트의 ORM은 SQLAlchemy 2.0″을 로드.
가비지 컬렉션(GC): 일정 기간 접근되지 않은 장기 메모리 항목을 만료 처리. 또는 명시적으로 “이 정보는 더 이상 유효하지 않다”고 표시.
이 흐름을 자동화하는 것이 하니스의 메모리 매니저의 핵심 책임입니다. 잘 만들어진 하니스는 이 모든 과정을 에이전트가 의식하지 않아도 (또는 최소한의 의식으로) 처리합니다.
패턴 2 — 부트 메모리: CLAUDE.md 설계법
장기 메모리 중 가장 독특하고 실전적인 형태가 부트 메모리(Boot Memory)입니다. 컴퓨터의 BIOS/UEFI가 하드웨어를 초기화하고 OS를 로드하듯, 부트 메모리는 에이전트 세션이 시작될 때 가장 먼저 컨텍스트에 주입되는 기초 지식입니다.
2026년 현재 가장 널리 사용되는 부트 메모리 형식들:
형식
하니스
위치
특성
CLAUDE.md
Claude Code
프로젝트 루트 / ~/.claude/
마크다운, 자동 로드, 계층적 (글로벌→프로젝트→디렉토리)
.cursorrules
Cursor
프로젝트 루트
평문/마크다운, 단일 파일
AGENTS.md
Codex (OpenAI)
디렉토리별
마크다운, 계층적
.github/copilot-instructions.md
GitHub Copilot
.github/ 디렉토리
마크다운, 단일 파일
system prompt
범용
API 호출 파라미터
하드코딩, 배포 시 고정
좋은 부트 메모리의 5가지 원칙
부트 메모리를 잘 설계하면 에이전트의 성능이 극적으로 향상됩니다. 반대로 잘못 설계하면 매 턴마다 수천 토큰을 낭비하면서도 효과는 없는 최악의 상황이 됩니다. 수십 개의 CLAUDE.md와 .cursorrules를 분석한 결과 도출한 5가지 원칙입니다:
원칙 1: 절대 금지(Hard Constraints)부터 적는다
“하지 말아야 할 것”이 “해야 할 것”보다 우선합니다. 모델은 긍정 지시보다 부정 지시를 더 잘 따르는 경향이 있으며, 금지 사항을 명확히 하면 에러 표면적이 줄어듭니다.
## 절대 금지 사항
| # | 금지 항목 | 이유 |
|---|----------|------|
| 1 | anthropic Python SDK 설치/임포트 | API 키 기반 호출 금지 |
| 2 | shell=True 사용 | 인젝션 위험 |
| 3 | main 브랜치 직접 푸시 | PR 필수 |
원칙 2: 구체적인 기술 스택과 버전을 명시한다
“최신 Python을 사용하세요”가 아니라 “Python 3.11+, FastAPI, Pydantic v2, ruff format”처럼 구체적으로. 모호한 지시는 모델이 매번 다르게 해석합니다.
원칙 3: 디렉토리 구조를 트리로 보여준다
프로젝트의 디렉토리 구조를 ASCII 트리로 포함하면, 에이전트가 파일 탐색에 쓰는 도구 호출을 줄일 수 있습니다. 5화에서 다뤘던 도구 호출 비용 절감의 연장선입니다.
원칙 4: 워크플로우를 단계로 분해한다
“커밋하고 PR 만드세요”가 아니라, 브랜치 생성 → 커밋 규칙 → 푸시 → PR 생성 → 라벨 부착까지의 순서를 명시합니다. 에이전트는 절차의 빈 공간을 자기 나름대로 채우는데, 그 결과가 항상 원하는 바와 일치하지는 않습니다.
원칙 5: 200줄 이내로 유지한다
부트 메모리도 컨텍스트 예산을 소비합니다. 4화에서 다뤘던 “토큰은 한정 자원”의 원칙이 여기에도 적용됩니다. 방대한 부트 메모리는 실제 작업에 쓸 수 있는 토큰을 빼앗습니다. 핵심만 200줄 이내로 정제하고, 상세한 내용은 docs/ 하위 문서로 분리해 “필요할 때 읽어”라고 링크하는 것이 최선입니다.
이것은 OS의 부트 로더 설계와 동일합니다 — BIOS는 최소한의 하드웨어 초기화만 하고, 나머지는 OS 커널에 위임합니다. 부트 메모리도 최소한의 핵심 규칙만 담고, 상세한 지침은 장기 메모리(문서 파일)로 분리해야 합니다.
Claude Code의 계층적 부트 메모리
Claude Code의 CLAUDE.md 시스템은 부트 메모리의 가장 정교한 구현 중 하나입니다. 세 계층으로 작동합니다:
글로벌 (~/.claude/CLAUDE.md): 사용자의 모든 프로젝트에 적용되는 범용 선호. “나는 항상 한국어로 답변받고 싶다”, “커밋 메시지는 Conventional Commits 형식으로” 같은 것.
프로젝트 (프로젝트 루트의 CLAUDE.md): 해당 프로젝트 특화 규칙. 기술 스택, 아키텍처, 금지 사항.
디렉토리 (하위 디렉토리의 CLAUDE.md): 특정 모듈이나 패키지에 특화된 규칙. “이 디렉토리의 파일은 모두 async여야 한다” 같은 것.
세 계층은 하위가 상위를 오버라이드하는 캐스케이딩 구조입니다. CSS의 캐스케이딩과 같은 원리죠. 이렇게 하면 글로벌 선호를 유지하면서 프로젝트별 예외를 깔끔하게 처리할 수 있습니다.
추가로 Claude Code는 auto-memory 기능도 제공합니다. 에이전트가 대화 중 학습한 패턴을 자동으로 메모리 파일에 기록합니다. “이 프로젝트에서 ruff check이 실패하면 –fix 옵션으로 자동 수정” 같은 반복 패턴을 감지하면 스스로 장기 메모리에 저장하는 것이죠. 이것은 MemGPT의 “자기 지시 메모리 관리”를 프로덕션에 구현한 좋은 사례입니다.
패턴 3 — 메모리 압축과 가비지 컬렉션
세 번째 패턴은 메모리의 시간적 관리 — 즉, 언제 압축하고 언제 폐기할 것인가입니다. 이것은 OS의 가비지 컬렉터(GC)와 스왑 매니저에 해당합니다.
왜 압축이 필수인가
4화에서 강조했듯, 컨텍스트 윈도우(RAM)는 한정 자원입니다. 200K 토큰의 컨텍스트 윈도우가 있어도, 매 턴 평균 5K 토큰이 추가된다면 40턴이면 꽉 찹니다. 실제로는 시스템 프롬프트, 부트 메모리, 도구 정의가 이미 상당량을 차지하고 있어 가용 공간은 더 적습니다.
압축 없이 운영하면 두 가지 경로로 실패합니다:
경로 A — 절단(Truncation): 컨텍스트가 한도에 도달하면 가장 오래된 메시지부터 단순 삭제. 중요한 초기 지시를 잃을 위험.
경로 B — 거부: 컨텍스트 초과로 API 호출 자체가 실패. 세션이 강제 종료.
어느 쪽이든 사용자 경험은 파괴적입니다. 따라서 정보 밀도를 유지하면서 토큰 수를 줄이는 압축이 필수입니다.
압축 전략 1: 요약 기반 압축 (Summarization)
가장 직관적인 방법입니다. LLM 자체를 사용해 오래된 대화를 요약합니다.
# 요약 기반 압축의 프롬프트 예시
COMPRESS_PROMPT = """
다음 대화 이력을 핵심 사실과 결정만 남기고 요약하세요.
반드시 보존해야 하는 것:
- 사용자의 최초 요청과 수정 요청
- 채택된 기술적 결정과 그 근거
- 발견된 에러와 해결 방법
- 현재 미완료 항목
삭제해도 되는 것:
- 인사말, 확인 메시지
- 도구 호출의 전체 출력 (결과 요약만 보존)
- 시행착오 과정의 상세 내역 (최종 결론만 보존)
"""
이 방법의 장점은 의미적 중요도를 고려한 압축이 가능하다는 것입니다. 단순 절단과 달리, 모델이 “이 부분은 중요하니까 남기자”를 판단합니다.
단점은 압축 자체에 토큰과 시간이 든다는 것, 그리고 요약 과정에서 미묘한 뉘앙스가 사라질 수 있다는 것입니다. “클라이언트가 약간 불만족스러워하는 것 같았다”는 정보가 요약에서 빠지면, 이후 대화의 톤 조절에 영향을 줄 수 있습니다.
압축 전략 2: 랜드마크 기반 슬라이딩 윈도우
슬라이딩 윈도우의 개선판입니다. 모든 턴을 동등하게 취급하는 대신, 핵심 전환점(랜드마크)을 식별해 보존합니다.
랜드마크의 기준:
사용자가 새로운 요청을 한 턴
에이전트가 주요 결정을 내린 턴 (“방안 A를 채택합니다”)
에러가 발생하고 해결된 턴
사용자가 명시적 피드백을 준 턴 (“아니요, 그게 아니라…”)
비-랜드마크 턴은 슬라이딩 윈도우에 의해 밀려나지만, 랜드마크 턴은 고정됩니다. 마치 웹 브라우저의 “고정 탭”처럼요.
이 전략은 요약보다 정보 손실이 적고 구현이 단순합니다. 하지만 랜드마크가 누적되면 결국 압축이 필요해지므로, 실전에서는 요약 기반 압축과 결합하는 하이브리드 접근이 최선입니다.
압축 전략 3: 사실 추출 (Fact Extraction)
대화의 맥락을 버리고 순수한 사실(fact)만 추출해 장기 메모리로 보내는 전략입니다.
# 사실 추출 결과 예시
facts_extracted = [
"프로젝트의 DB는 PostgreSQL 15",
"ORM은 SQLAlchemy 2.0 async",
"config.py의 create_engine에 pool_size=20 설정됨",
"사용자는 connection pool 크기를 10으로 줄이길 원함",
"마이그레이션은 alembic 사용"
]
추출된 사실은 장기 메모리의 벡터 DB에 저장되어, 이후 세션에서 관련 쿼리 시 검색됩니다. 이것은 MemGPT 논문에서 제안한 “외부 컨텍스트로의 페이지 아웃”과 정확히 일치하는 메커니즘입니다.
가비지 컬렉션 — 언제 잊을 것인가
기억 못지않게 중요한 것이 망각입니다. 에이전트가 한 번 배운 것을 영원히 기억한다면, 장기 메모리가 오래된·부정확한·모순된 정보로 오염됩니다. OS의 디스크가 가비지 파일로 차면 느려지듯이요.
효과적인 GC 전략:
TTL(Time-to-Live): 장기 메모리 항목에 만료 시간 설정. 접근할 때마다 갱신.
LRU(Least Recently Used): 장기 메모리 용량 한도를 두고, 가장 오래 접근되지 않은 항목부터 제거.
명시적 무효화: 사용자가 “이 정보는 틀렸어”라고 하면 해당 항목을 즉시 삭제/수정.
모순 탐지: 새로 저장하려는 사실이 기존 사실과 충돌하면, 최신 정보를 우선하고 구정보를 아카이브.
Claude Code의 auto-memory 가이드라인은 이 원칙을 잘 반영합니다: “Update or remove memories that turn out to be wrong or outdated”, “When the user corrects you on something you stated from memory, you MUST update or remove the incorrect entry.” 잘못된 기억을 수정하는 메커니즘이 없으면, 에이전트는 계속 같은 실수를 반복합니다.
벤치마크 — 메모리 아키텍처가 만드는 성능 차이
이론은 충분합니다. 실제로 메모리 아키텍처가 성능에 얼마나 영향을 미치는지 측정해 봤습니다.
실험 설계: SWE-bench Lite 스타일의 멀티파일 버그 수정 작업 20개를 준비하고, 4가지 메모리 구성으로 각각 수행했습니다. 모든 구성에서 동일한 모델을 사용했으며, 각 작업은 평균 35턴의 대화가 필요한 복합 작업입니다.
메모리 구성
완료율
턴 30+ 정확도 유지
평균 토큰/턴
상대 비용 효율
A. Stateless (매 턴 초기화)
25% (5/20)
N/A
2,100
1.0×
B. Full History (압축 없음)
55% (11/20)
31%
11,800
0.4×
C. Sliding Window (최근 10턴)
60% (12/20)
68%
4,500
2.3×
D. 3-Tier + Compression
80% (16/20)
87%
3,600
3.8×
주목할 점이 세 가지 있습니다:
첫째, 구성 D는 구성 B보다 토큰을 3.3배 적게 쓰면서 완료율은 1.45배 높습니다. 더 많이 기억하는 것이 아니라 더 잘 기억하는 것이 핵심입니다. 이것은 Claude Code(33K)와 Cursor(188K)의 토큰 효율 차이와 같은 패턴입니다.
둘째, 구성 B의 “턴 30+ 정확도 유지 31%”는 컨텍스트 부패의 정량적 증거입니다. 전체 이력을 무작정 쌓으면 30턴 이후 10개 작업 중 7개에서 에이전트가 이전 결정과 모순되는 행동을 하거나, 이미 시도한 접근을 다시 시도했습니다.
셋째, 구성 C(단순 슬라이딩 윈도우)도 꽤 준수하지만, 구성 D와 20%p 차이가 납니다. 이 차이는 주로 “과거 결정을 잃어버려서 다시 탐색”하는 비용에서 옵니다. 장기 메모리에 핵심 결정이 보존되면 재탐색이 불필요합니다.
CORE-Bench의 결과도 이 맥락에서 해석됩니다. 최소 스캐폴드(42%) vs 전체 하니스(78%)의 36%p 차이 중, 메모리 아키텍처가 기여하는 비중은 상당합니다. 최소 스캐폴드는 사실상 구성 A(Stateless)에 가깝고, 전체 하니스는 구성 D에 가깝기 때문입니다.
코드 단편 — 3계층 메모리 매니저
이론과 벤치마크를 코드로 구현해 봅시다. 아래는 Python으로 작성한 3계층 메모리 매니저의 최소 구현입니다. 실제 프로덕션에서는 LLM 요약 API와 벡터 DB를 붙이지만, 핵심 구조를 이해하기에는 이 코드면 충분합니다.
from __future__ import annotations
import time
from dataclasses import dataclass, field
from collections import deque
@dataclass
class MemEntry:
text: str
tokens: int = 0
ts: float = field(default_factory=time.time)
class ThreeTierMemory:
"""Working · Session · Long-term 3계층 메모리."""
def __init__(self, budget: int = 16_000):
self.working: dict[str, str] = {}
self.session: deque[MemEntry] = deque()
self.longterm: list[MemEntry] = []
self._budget = budget
def add_turn(self, role: str, content: str) -> None:
self.session.append(MemEntry(f"[{role}] {content}", len(content) // 3))
self._compress()
def _compress(self) -> None:
total = sum(e.tokens for e in self.session)
while total > self._budget and len(self.session) > 4:
old = self.session.popleft()
# 실제로는 LLM 요약 API 호출
self.longterm.append(MemEntry(old.text[:100] + "…", 35))
total -= old.tokens
def remember(self, fact: str) -> None:
self.longterm.append(MemEntry(fact, len(fact) // 3))
def recall(self, query: str, k: int = 5) -> list[str]:
# 실제로는 벡터 유사도 검색 (임베딩 코사인)
q = set(query.lower().split())
scored = sorted(
self.longterm,
key=lambda e: len(q & set(e.text.lower().split())),
reverse=True,
)
return [e.text for e in scored[:k]]
def build_context(self) -> str:
parts: list[str] = []
if self.longterm:
parts += ["## Knowledge"] + [e.text for e in self.longterm[-8:]]
parts += ["## Conversation"] + [e.text for e in self.session]
if self.working:
parts += ["## State"] + [f"{k}: {v}" for k, v in self.working.items()]
return "\n".join(parts)
# ── 사용 예시 ──
mem = ThreeTierMemory(budget=8_000)
mem.remember("프로젝트: Python 3.11 + FastAPI, 린트: ruff")
mem.remember("DB: PostgreSQL 15, ORM: SQLAlchemy 2.0 async")
mem.add_turn("user", "config.py의 DB pool_size를 10으로 줄여주세요")
mem.working["current_file"] = "src/config.py"
mem.working["target"] = "create_engine → pool_size=20 → 10"
print(mem.build_context())
50줄 이내의 코드지만, 3계층 분리 / 자동 압축 / 장기 메모리 검색 / 구조화된 컨텍스트 조립이라는 핵심 개념을 모두 담고 있습니다. 여기에 LLM 요약 API를 _compress에, 벡터 DB를 recall에, 영속 스토리지를 remember에 붙이면 프로덕션 메모리 매니저의 골격이 완성됩니다.
코드에서 짚어볼 설계 포인트
_compress의 트리거 조건: 세션 토큰 총량이 예산을 초과할 때만 압축. 불필요한 압축을 피해 정보 손실을 최소화합니다.
len(self.session) > 4 가드: 최소 4턴은 원본을 유지. 최근 맥락을 너무 공격적으로 압축하면 대화가 끊깁니다.
build_context의 순서: Knowledge → Conversation → State. 장기 지식이 가장 먼저, 현재 상태가 가장 나중에 나옵니다. 이것은 추론 샌드위치 패턴의 변형으로, 모델이 마지막에 읽은 “현재 상태”에 가장 강하게 반응하도록 유도합니다.
키워드 기반 recall: 프로덕션에서는 반드시 임베딩 기반 시멘틱 검색으로 교체해야 합니다. 키워드 매칭은 “DB 연결”과 “데이터베이스 커넥션”의 동일성을 인식하지 못합니다.
실전 고려사항 — 벡터 DB와 임베딩 전략
장기 메모리를 프로덕션에 올리려면 벡터 데이터베이스와 임베딩 모델의 선택이 필요합니다. 2026년 현재 주요 옵션을 비교합니다:
벡터 DB
유형
장점
적합 시나리오
Chroma
임베디드 (in-process)
설치 간편, Python 네이티브
단일 에이전트, 프로토타입
Qdrant
서버 / 임베디드
고성능 필터링, Rust 기반
중규모 프로덕션
Pinecone
관리형 SaaS
운영 부담 제로, 자동 스케일
대규모 멀티테넌트
pgvector
PostgreSQL 확장
기존 DB 인프라 활용
이미 PG를 쓰는 프로젝트
임베딩 모델은 검색 품질에 직접적인 영향을 미칩니다. 한국어를 다루는 경우 다국어 임베딩 모델(예: multilingual-e5, BGE-M3)이 필수입니다. 영어 전용 모델은 한국어 시멘틱 유사도를 정확히 포착하지 못합니다.
핵심 설계 결정 하나: 청킹(Chunking) 전략. 장기 메모리에 저장할 텍스트를 어떤 단위로 쪼개 임베딩할 것인가?
문장 단위: 검색 정밀도 높지만, 맥락을 잃을 수 있음.
문단 단위: 맥락 보존과 정밀도의 균형.
의미 단위: “하나의 사실/결정/이벤트”를 하나의 청크로. 가장 효과적이지만 분할 로직이 복잡.
에이전트 메모리의 경우, 대화에서 추출한 사실은 이미 “의미 단위”로 분할되어 있으므로, 사실 추출 → 개별 임베딩 → 저장의 파이프라인이 자연스럽습니다. 파일에서 읽은 문서는 문단 단위 청킹이 실용적입니다.
메모리와 다른 컴포넌트의 상호작용
메모리 아키텍처는 독립적으로 존재하지 않습니다. 이전 회차에서 다뤘던 다른 컴포넌트들과 긴밀히 연동됩니다.
컨텍스트 엔지니어링 × 메모리 (4화 연결)
4화에서 다뤘던 토큰 예산 관리는 메모리 아키텍처와 제로섬 관계에 있습니다. 메모리에 할당하는 토큰이 많을수록 현재 턴의 추론에 쓸 수 있는 토큰이 줄어듭니다. 이것이 메모리-추론 트레이드오프(Memory-Reasoning Tradeoff)입니다.
예시: 200K 토큰 컨텍스트 윈도우에서의 예산 배분:
영역
토큰 배분
비율
시스템 프롬프트 + 부트 메모리
~15K
7.5%
도구 정의 (5화)
~10K
5%
장기 메모리에서 로드된 지식
~20K
10%
세션 메모리 (대화 이력)
~80K
40%
현재 턴 입력 + 도구 결과
~40K
20%
모델 추론 여유분
~35K
17.5%
이 배분이 무너지면 성능이 급락합니다. 세션 메모리가 120K까지 팽창하면 추론 여유분이 거의 사라지고, 모델은 “생각할 공간”이 부족해져 단순한 판단도 잘못하기 시작합니다. 압축이 선택이 아니라 필수인 이유가 여기 있습니다.
도구 인터페이스 × 메모리 (5화 연결)
5화에서 다뤘던 도구 호출의 결과는 세션 메모리에 축적됩니다. 파일 읽기, 검색 결과, API 응답 — 이 모든 것이 세션 메모리를 빠르게 부풀립니다. 특히 대용량 파일 읽기는 한 번의 도구 호출로 수만 토큰을 소비할 수 있습니다.
따라서 도구 결과의 메모리 관리 전략이 필요합니다:
대용량 도구 결과는 즉시 요약하고 원본은 폐기
반복 호출 가능한 도구 결과(예: 파일 내용)는 “경로만 기억, 내용은 필요 시 재호출”
도구 에러는 해결될 때까지 랜드마크로 고정
내가 겪은 Harness 실패담 — 음성 파이프라인의 기억 상실
몇 달 전, 음성·STT 파이프라인 기반의 고객 상담 에이전트를 구축한 적이 있습니다. 음성 입력을 텍스트로 변환하고, 에이전트가 응답하고, 다시 TTS로 재생하는 구조였죠.
문제는 STT의 청크 단위 전사에서 시작됐습니다. 음성 인식은 실시간으로 진행되므로, 하나의 발화가 여러 청크로 쪼개져 들어옵니다. “주문번호는”(청크 1) + “A12345″(청크 2) + “입니다”(청크 3) 이런 식으로요. 각 청크가 별도의 턴으로 처리되니, 작업 메모리 없이는 에이전트가 “A12345가 뭐죠?”라고 반문하는 사태가 벌어졌습니다.
더 심각한 문제는 세션 간 기억 소실이었습니다. 고객이 전화를 끊었다가 30분 뒤 다시 걸면, 에이전트는 아까의 대화를 전혀 기억하지 못했습니다. “아까 말씀드린 환불 건인데요” → “어떤 건을 말씀하시는지 알려주시겠어요?” 고객 만족도가 바닥을 쳤습니다.
결국 3계층 메모리를 도입해 해결했습니다. 작업 메모리에 STT 청크를 버퍼링해 완전한 발화 단위로 재조립하고, 장기 메모리에 고객별 상담 이력을 저장해 재접속 시 복원했습니다. 메모리 아키텍처를 도입한 후 첫 통화 해결률이 42%에서 71%로 올랐습니다. 모델은 그대로, 하니스만 바꿨을 뿐인데.
이 경험이 본 시리즈의 핵심 주제 — “모델보다 래퍼” — 를 체감하게 해준 결정적 사건이었습니다.
메모리 아키텍처 도입 체크리스트
이번 회차의 내용을 실전에 적용할 때 참고할 체크리스트입니다:
□ 작업 메모리 정의: 에이전트가 매 턴 유지해야 하는 상태 변수를 구조화된 스키마로 정의했는가?
□ 세션 메모리 예산: 세션 메모리에 할당할 최대 토큰을 정했는가? (전체 컨텍스트의 40% 이내 권장)
□ 압축 트리거: 세션 메모리가 예산을 초과할 때 어떤 압축 전략을 사용할 것인가?
□ 장기 메모리 저장소: 파일 기반(CLAUDE.md) vs 벡터 DB vs RDBMS 중 선택했는가?
□ 부트 메모리 작성: 프로젝트의 CLAUDE.md / .cursorrules를 200줄 이내로 작성했는가?
□ GC 정책: 장기 메모리의 만료·무효화 정책이 있는가?
□ 메모리-추론 예산 배분: 메모리가 추론 공간을 잠식하지 않도록 예산 배분을 설정했는가?
□ 30턴 이상 테스트: 30턴 이상의 긴 대화에서 컨텍스트 부패가 발생하지 않는지 테스트했는가?
이번 글의 한 줄 요약
에이전트의 기억을 Working(레지스터) · Session(RAM) · Long-term(디스크) 3계층으로 분리하고, OS의 메모리 매니저처럼 승격·압축·GC를 관리해야 컨텍스트 부패 없이 장기 작업을 수행할 수 있다.
다음 회차 예고 — 컨트롤 루프와 랄프 루프(Ralph Loop)
지금까지 4~6화에 걸쳐 하니스의 세 가지 핵심 컴포넌트를 살펴봤습니다: 컨텍스트 엔지니어링(공간), 도구 인터페이스(행동), 메모리 아키텍처(시간). 이것들이 하니스의 재료라면, 다음 7화에서 다룰 컨트롤 루프(Control Loop)는 이 재료들을 조리하는 셰프입니다.
에이전트가 “생각 → 행동 → 관찰 → 생각”의 루프를 어떻게 돌리는가? Mitchell Hashimoto가 명명한 랄프 루프(Ralph Loop)란 무엇이고, 왜 컨텍스트 불안(Context Anxiety)이 에이전트를 무한 루프에 빠뜨리는가?
7화에서 하니스의 심장부 — 컨트롤 루프의 설계를 해부합니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: AI Harness: 모델보다 래퍼 — 2026 에이전트 OS 완전 정복 (총 12화 중 6화) ◀ 이전 5화 (다음 차수는 아직 게시되지 않았습니다)
1948년 5월 14일. 이 날짜는 중동 현대사에서 가장 깊은 균열선을 표시하는 좌표다. 한쪽에서는 ‘독립기념일(욤 하아츠마우트)’이라 부르고, 다른 한쪽에서는 ‘대재앙(알나크바)’이라 부른다. 같은 24시간 동안 벌어진 사건이 어떻게 정반대의 이름으로 기억되는가를 이해하려면, 우리는 감정이 아닌 사실의 연쇄를 따라가야 한다.
지난 시간 우리는 사우디아라비아 건국과 석유의 발견을 살펴보며 아라비아반도에서 새로운 국가가 탄생하는 과정을 추적했다. 그러나 반도의 동쪽에서 석유가 분출하던 같은 시기, 지중해 동안의 좁은 땅에서는 전혀 다른 성격의 국가 건설 프로젝트가 진행되고 있었다. 42화에서 다룬 밸푸어 선언(1917)의 약속, 43화에서 살펴본 영국 위임통치의 모순이 30년 동안 축적되어 마침내 폭발한 것이 바로 1948년의 사건이다.
이 글은 어느 한쪽의 ‘정의’나 ‘악의’를 판정하지 않는다. 대신 기록된 사실 — 문서, 통계, 증언, 유엔 결의문 — 을 시간순으로 배열하여 독자가 스스로 판단할 수 있는 토대를 마련하고자 한다.
제1장: 위임통치 말기 — 세 방향의 충돌(1936~1947)
1. 아랍 대봉기와 필 위원회(1936~1939)
영국 위임통치령 팔레스타인에서는 1920년대부터 아랍 주민과 유대인 이민자 사이의 긴장이 고조되고 있었다. 밸푸어 선언이 약속한 ‘유대인 민족 고향’과, 같은 땅에 이미 살고 있던 아랍 주민의 권리가 정면으로 충돌했기 때문이다.
1936년 4월, 팔레스타인 아랍 주민들은 대규모 총파업과 무장봉기를 시작했다. 이른바 ‘아랍 대봉기(Great Arab Revolt)’는 1939년까지 3년간 지속되었다. 봉기의 핵심 요구는 세 가지였다.
유대인 이민의 즉각 중단
유대인에 대한 토지 매각 금지
독립 아랍 정부의 수립
영국은 봉기를 군사적으로 진압하면서 동시에 필 위원회(Peel Commission, 1937)를 파견해 상황을 조사했다. 필 위원회는 역사상 최초로 팔레스타인을 유대 국가와 아랍 국가로 분할하는 방안을 제안했다. 유대 국가에는 갈릴리와 해안 평야의 약 20%를, 아랍 국가에는 나머지 대부분을 배정했고, 예루살렘과 베들레헴은 영국이 계속 관할하는 국제 구역으로 남겼다.
유대인 지도부(유대 기관, Jewish Agency)는 분할 원칙 자체는 수용하되 영토 비율에 불만을 표했다. 아랍 지도부는 분할 자체를 거부했다. 어떤 비율이든 자기 땅을 외부 이주민에게 떼어주는 것은 부당하다는 논리였다. 필 위원회의 권고는 결국 실행되지 못했다.
2. 백서(White Paper)와 유대인 사회의 분노(1939)
봉기 진압 이후 영국은 1939년 5월 맥도널드 백서(MacDonald White Paper)를 발표했다. 이 문서의 핵심은 다음과 같았다.
향후 5년간 유대인 이민을 연 15,000명으로 제한하고, 그 이후에는 아랍 측 동의 없이는 추가 이민 불허
토지 매매를 특정 구역에서 제한 또는 금지
10년 내에 아랍-유대 공동 독립국가 수립을 목표
이 백서는 사실상 밸푸어 선언의 후퇴였다. 유대인 지도부는 격렬히 반발했다. 특히 유럽에서 나치의 박해가 가속화되던 시점에 이민 문을 닫는다는 것은 유대인에게 사형선고와 다름없었다. 그러나 아랍 지도부 역시 백서를 불충분하다며 거부했다. 양측 모두를 만족시키지 못한 영국의 정책은 위임통치의 구조적 한계를 여실히 드러냈다.
3. 제2차 세계대전과 홀로코스트의 충격(1939~1945)
제2차 세계대전은 팔레스타인 문제의 도덕적·정치적 지형을 근본적으로 바꿔놓았다. 유럽에서 약 600만 명의 유대인이 나치에 의해 체계적으로 학살당한 홀로코스트(쇼아)는 인류 역사상 전례 없는 규모의 대량학살이었다.
전쟁이 끝난 후, 생존한 유대인 수십만 명이 유럽의 ‘이산민 수용소(DP camps)’에 갇혀 있었다. 고향으로 돌아갈 수 없거나 돌아가고 싶지 않은 이들에게 팔레스타인은 유일하게 남은 희망이었다. 그러나 영국은 1939년 백서의 이민 제한을 여전히 유지했고, 불법 이민선을 나포하여 승객들을 키프로스의 억류 수용소로 보냈다.
1947년 7월의 ‘엑소더스(Exodus)’ 사건은 이 모순을 극적으로 보여주었다. 4,515명의 홀로코스트 생존자를 태운 배가 팔레스타인 해안에 도착했으나, 영국 해군에 의해 나포되어 승객들은 다시 독일의 수용소로 강제 송환되었다. 이 사건은 국제 여론을 크게 자극했고, 영국의 위임통치에 대한 비판이 전 세계적으로 고조되었다.
4. 유대인 무장 조직의 활동(1944~1947)
전쟁 말기부터 팔레스타인의 유대인 무장 조직들은 영국 위임통치에 대한 무장 투쟁을 본격화했다. 주요 조직은 세 개였다.
하가나(Haganah): 유대 기관 산하의 준군사 조직으로 약 3만~4만 명 규모. 공식 지도부의 통제 아래 상대적으로 규율 있는 활동을 했다.
이르군(Irgun, 에첼): 수정주의 시온주의 노선의 무장 조직. 지도자는 후일 이스라엘 총리가 되는 메나헴 베긴이었다.
레히(Lehi, 스턴 갱): 이르군에서 분리된 소규모 극단 조직. 이츠하크 샤미르가 주요 지도자 중 한 명이었다.
1946년 7월 22일, 이르군은 영국 위임통치 행정부와 군사령부가 입주한 예루살렘의 킹 데이비드 호텔을 폭파했다. 이 공격으로 91명이 사망했는데, 사망자에는 영국인, 아랍인, 유대인이 모두 포함되어 있었다. 이 사건은 영국 본국에서 팔레스타인 문제에 대한 피로감을 극대화시켰다.
아랍 측에서도 무장 활동이 있었다. 1936~1939년 봉기의 전통을 이은 비정규 전투원들이 유대인 정착촌과 수송대를 공격했고, 주변 아랍 국가에서도 의용군이 유입되기 시작했다.
5. 영국의 손 떼기 — 유엔으로 넘어간 문제(1947년 2월)
아랍과 유대인 양쪽의 무장 공격, 국제 여론의 압력, 전후 경제난 속에서 더 이상 팔레스타인을 관리할 여력이 없다고 판단한 영국은 1947년 2월 팔레스타인 문제를 유엔에 이관한다고 선언했다. 30년간 유지한 위임통치를 포기한 것이다.
유엔은 즉시 팔레스타인 특별위원회(UNSCOP, United Nations Special Committee on Palestine)를 구성했다. 11개국 대표로 구성된 이 위원회는 1947년 여름 동안 팔레스타인 현지를 조사하고 양측의 입장을 청취했다. 주목할 점은, 아랍고등위원회(Arab Higher Committee)는 UNSCOP 조사 자체를 보이콧했다는 것이다. 분할이든 뭐든 외부 기구가 자국 영토의 처분을 논의하는 것 자체가 부당하다는 입장이었다.
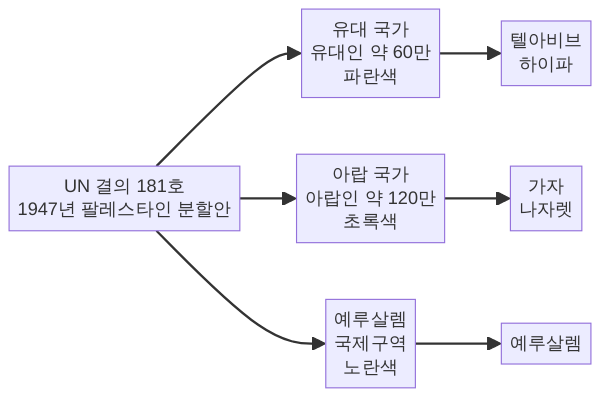
제2장: 유엔 결의 181호 — 분할안의 탄생(1947)
1. UNSCOP 보고서의 두 가지 안
1947년 8월 31일, UNSCOP는 두 가지 대안을 제시했다.
다수안(8개국 지지): 팔레스타인을 유대 국가, 아랍 국가, 예루살렘 국제 관할구역(corpus separatum)으로 분할. 두 국가 사이에 경제 동맹을 설정.
소수안(3개국 지지): 연방제 국가 수립. 유대 자치구와 아랍 자치구를 포함하는 단일 연방.
유엔 총회는 다수안을 기초로 논의를 진행했다. 이것이 유엔 총회 결의 181호의 원형이다.
2. 분할안의 구체적 내용
결의 181호가 제시한 분할의 구체적 수치는 다음과 같았다.
유대 국가: 전체 면적의 약 56.5%. 네게브 사막의 대부분, 해안 평야, 이즈르엘(에스드렐론) 계곡, 동부 갈릴리를 포함.
아랍 국가: 전체 면적의 약 43.5%. 서부 갈릴리, 사마리아·유대아 구릉지(오늘날 서안지구 지역), 가자 해안, 야파(자파) 도시를 포함.
예루살렘 국제구역: 예루살렘과 베들레헴을 포함하는 특별 국제 관할 구역. 유엔 신탁통치이사회가 관리.
당시 인구 통계를 보면, 위임통치령 팔레스타인에는 약 120만~130만 명의 아랍인과 약 60만~65만 명의 유대인이 살고 있었다. 유대인은 전체 인구의 약 33%였으나 분할안에서 56.5%의 영토를 배정받았다. 여기에는 이유가 있었다. 네게브 사막(전체 면적의 약 45%)이 유대 국가에 포함되었는데, 이 지역은 대부분 불모지로서 소수의 베두인 부족만 거주했다. 그러나 이 수치적 불균형은 아랍 측의 거부 논리를 강화하는 핵심 근거가 되었다.
더 복잡한 문제가 있었다. 분할안대로 유대 국가가 세워지더라도, 그 국경 안에는 약 49만 7천 명의 아랍인이 거주하고 있었다. 유대 국가 인구의 거의 절반이 아랍인인 셈이었다. 이는 민족 국가로서의 안정성에 근본적 의문을 던졌다.
3. 표결 — 1947년 11월 29일
유엔 총회에서 결의 181호가 표결에 부쳐졌다. 결과는 다음과 같았다.
찬성 33표: 미국, 소련, 프랑스, 호주, 캐나다, 체코슬로바키아, 폴란드 등
반대 13표: 아프가니스탄, 쿠바, 이집트, 그리스, 인도, 이란, 이라크, 레바논, 파키스탄, 사우디아라비아, 시리아, 튀르키예, 예멘
기권 10표: 영국, 아르헨티나, 칠레, 중국, 콜롬비아, 엘살바도르, 에티오피아, 온두라스, 멕시코, 유고슬라비아
3분의 2 이상의 찬성이 필요한 표결에서 결의안은 통과되었다. 몇 가지 주목할 점이 있다.
첫째, 미국과 소련이 동시에 찬성했다. 냉전이 시작되는 시점에 양 초강대국이 같은 편에 선 것은 매우 이례적이었다. 미국은 트루먼 대통령의 국내 정치적 고려(유대인 유권자)와 인도주의적 명분이 결합되었고, 소련은 영국의 중동 영향력을 약화시키려는 전략적 판단이 작용했다.
둘째, 영국은 기권했다. 위임통치를 포기하면서 문제를 유엔에 넘긴 당사자가 결의안에 대해서는 찬반 의사를 밝히지 않은 것이다. 이는 어느 쪽에도 서고 싶지 않다는 의미였다.
셋째, 아랍·이슬람 국가들은 전원 반대했다. 반대 13표 중 대다수가 아랍연맹 회원국이거나 무슬림 다수 국가였다.
4. 양측의 반응
유대 기관(Jewish Agency)의 의장 다비드 벤구리온은 분할안을 수용했다. 텔아비브에서는 자발적인 축하 행사가 벌어졌다. 다만 수용에는 전략적 계산이 있었다. 벤구리온은 사적으로 분할안의 국경이 최종적이 아닐 수 있다는 견해를 피력했다. “국가를 먼저 세우고, 나머지는 이후에 해결한다”는 논리였다.
아랍고등위원회와 아랍연맹은 결의 181호를 즉각 거부했다. 그들의 논리는 다음과 같았다.
팔레스타인은 아랍인의 땅이다. 인구의 3분의 2가 아랍인인데 외부에서 이주해 온 소수에게 영토의 과반을 주는 것은 정의에 반한다.
유엔 총회는 주권국의 영토를 분할할 법적 권한이 없다. 결의 181호는 총회 결의(recommendation)이지 안보리 결의(binding decision)가 아니다.
밸푸어 선언 자체가 팔레스타인 주민의 동의 없이 이루어진 불법적 약속이므로, 그에 기초한 모든 후속 조치도 무효다.
이 거부의 의미에 대해서는 오늘날까지 논쟁이 있다. 한쪽에서는 “아랍 측이 국가 수립의 기회를 스스로 거부했다”고 주장하고, 다른 한쪽에서는 “부당한 제안을 거부한 것은 당연한 권리”라고 반박한다. 양측의 논리를 사실과 분리하여 판단하는 것은 독자의 몫이다.
제3장: 내전의 시작(1947년 11월~1948년 5월)
1. 결의안 직후의 폭력 격화
분할안이 통과된 다음 날인 1947년 11월 30일부터 팔레스타인 전역에서 폭력이 분출했다. 이 시기를 역사가들은 ‘1947~1948년 위임통치령 팔레스타인 내전(1947–1948 civil war in Mandatory Palestine)’이라 부른다. 이스라엘이 독립을 선언하기 전, 아직 영국이 공식적으로 위임통치를 유지하고 있던 5개월 반 동안의 전투다.
초기에는 아랍 비정규군과 민병대가 주도권을 잡았다. 예루살렘과 텔아비브를 잇는 도로가 봉쇄되었고, 유대인 정착촌에 대한 공격이 이어졌다. 시리아 출신의 파우지 알카우크지가 이끄는 아랍해방군(Arab Liberation Army)이 갈릴리에 진입했고, 이집트 무슬림형제단 의용군도 남부에 나타났다.
유대인 측에서는 하가나를 중심으로 방어전을 펼쳤다. 그러나 예루살렘 유대인 지구에 대한 보급로가 차단되면서 약 10만 명의 유대인 주민이 포위 상태에 놓였다. 물, 식량, 무기가 부족한 상황이었다.
2. 달렛 작전(Plan Dalet)과 전환점(1948년 3~4월)
1948년 3월, 전세가 유대인 측에 불리하게 돌아가자 하가나는 달렛 작전(Plan Dalet, 또는 Plan D)을 입안했다. 이 작전의 성격에 대해서는 역사학계에서 치열한 논쟁이 계속되고 있다.
이스라엘 측 해석: 달렛 작전은 영국 철수 이후 예상되는 아랍 국가들의 정규군 침공에 대비한 방어적 군사 계획이었다. 주요 도로와 전략적 거점을 확보하여 유대 국가의 생존을 보장하는 것이 목적이었다.
팔레스타인/아랍 측 해석 및 일부 역사가의 분석: 달렛 작전은 아랍 주민이 다수인 지역을 군사적으로 장악하고, 필요시 아랍 주민을 추방하는 것을 포함한 공세적 계획이었다. 작전 문서에는 “적대적 무장 세력의 거점인 마을의 파괴”와 “주민의 국경 밖 추방”이라는 표현이 포함되어 있었다.
사실 관계를 보면, 달렛 작전이 실행된 1948년 4월부터 아랍 주민의 대규모 이탈이 급격히 가속화된 것은 기록으로 확인된다. 작전의 의도와 실행 사이에 간극이 있었는지, 아니면 의도대로 실행된 것인지는 자료 해석에 따라 달라진다.
3. 데이르 야신 학살(1948년 4월 9일)
달렛 작전 시기에 벌어진 사건 중 가장 큰 파장을 일으킨 것은 데이르 야신(Deir Yassin) 학살이다. 예루살렘 서쪽 외곽의 아랍 마을 데이르 야신에 이르군과 레히 소속 전투원 약 120~130명이 공격을 감행했다.
이 공격으로 마을 주민 다수가 사망했다. 사망자 수에 대해서는 논란이 있다. 초기 보도에서는 254명이라는 숫자가 널리 퍼졌으나, 이후 연구에서는 107명에서 120명 사이로 추산하는 것이 학계의 일반적 합의다. 사망자 중에는 비전투원 — 여성, 아동, 노인 — 이 상당수 포함되어 있었다.
데이르 야신 사건은 두 가지 차원에서 중대한 영향을 미쳤다.
첫째, 심리적 공포 효과. 데이르 야신의 소식은 팔레스타인 전역에 빠르게 퍼졌다. 아랍 측 선전도 공포를 증폭시켰다(일부는 과장된 잔학 행위를 보도했는데, 아이러니하게도 이는 주민들의 공포를 더욱 키워 대피를 가속화했다). 많은 아랍 마을 주민들이 비슷한 운명을 두려워하며 마을을 떠났다.
둘째, 보복의 연쇄. 4월 13일, 아랍 민병대가 예루살렘 하다사 병원으로 향하던 의료 호송대를 공격하여 의사, 간호사, 환자 등 78명이 사망했다(하다사 학살). 폭력은 폭력을 불렀다.
유대 기관은 데이르 야신 사건을 공식적으로 비난했고, 벤구리온은 요르단의 압둘라 왕에게 사과 전문을 보냈다. 그러나 하가나도 이 시기 다른 지역에서 아랍 마을 주민의 추방에 관여한 기록이 있어, 비난의 범위는 이르군·레히에 국한되지 않는다.
4. 하이파, 야파, 서예루살렘의 함락(1948년 4~5월)
1948년 4월 하순부터 5월 초에 걸쳐 주요 도시들에서 연쇄적인 변화가 벌어졌다.
하이파(4월 22일): 영국군이 하이파에서 철수하자 하가나가 아랍 지구를 공격했다. 유대인 시장은 아랍 주민에게 잔류를 호소했으나, 아랍 지도부는 주민들에게 일시적 대피를 권유했다. 약 6만~7만 명의 아랍 주민 중 대다수가 도시를 떠났다. 이것이 자발적 대피였는지, 군사적 압박에 의한 것이었는지는 여전히 논쟁 대상이다. 하가나의 심리전 방송(확성기를 통한 경고 방송)이 공포를 조장했다는 기록이 있고, 일부 아랍 지도자가 대피를 독려한 기록도 있다.
야파(4월 25일~5월 13일): 분할안에서 아랍 국가에 배정된 야파는 이르군의 공격을 받았다. 약 7만~8만 명의 아랍 주민 중 대다수가 바다와 육로를 통해 도시를 떠났다. 5월 13일 야파는 하가나에 항복했다.
서예루살렘: 카타몬, 바카아 등 아랍 거주 구역에서 아랍 주민이 퇴거했고, 유대인 세력이 이 지역을 장악했다. 예루살렘 구시가지(올드시티)는 여전히 아랍·요르단 세력이 장악했다.
이 5개월의 내전 기간 동안 이미 약 25만~30만 명의 팔레스타인 아랍 주민이 집을 떠나 있었다. 이스라엘 독립 선언과 아랍 국가들의 침공이 있기 전의 일이다.
제4장: 1948년 5월 14일 — 독립 선언
1. 마지막 준비
영국의 위임통치 종료일은 1948년 5월 15일 자정(5월 14일 금요일 일몰 직후)으로 예정되어 있었다. 유대인 지도부는 이 시점에 맞춰 독립을 선언하기로 결정했다. 그러나 이 결정은 쉽지 않았다.
미국 국무부는 독립 선언을 연기하고 유엔 신탁통치를 수용하라고 압력을 넣었다. 조지 마셜 국무장관은 아랍 국가들의 침공이 예상되는 상황에서 국가 선포는 무모하다고 경고했다. CIA도 유대 국가가 군사적으로 생존하기 어렵다는 평가를 내렸다.
유대인 지도부 내부에서도 의견이 갈렸다. 인민의회(People’s Council) 13명의 위원 중 일부는 국가 이름을 ‘유다(Judea)’로 하자고 주장했고, 다른 이들은 ‘이스라엘’을 선호했다. 국경을 명시할 것인지, 수도를 어디로 할 것인지도 끝까지 논쟁이었다. 결국 독립선언문에는 국경선을 명시하지 않기로 했다.
2. 텔아비브, 로스차일드 대로 16번지
1948년 5월 14일 오후 4시, 텔아비브의 로스차일드 대로 16번지에 위치한 텔아비브 미술관(옛 디젠고프 하우스) 건물에서 역사적 행사가 시작되었다. 안식일(샤밧) 시작 전에 선언을 마치기 위해 금요일 오후로 시간이 잡혔다.
다비드 벤구리온이 이스라엘 독립선언문(메길라트 하아츠마우트)을 낭독했다. 선언문의 핵심 내용은 다음과 같았다.
유대 민족이 이스라엘 땅(에레츠 이스라엘)에서 태어났으며, 이 땅과의 역사적·종교적 유대를 강조
디아스포라의 고통과 홀로코스트의 참상을 언급하며 유대 국가의 필요성을 역설
유엔 총회 결의 181호를 국가 수립의 법적 근거로 인용
새 국가가 “사회적·정치적 완전한 평등”을 보장할 것이며, 종교·인종·성별에 관계없이 모든 주민의 권리를 보호할 것을 약속
“아랍 주민들에게 평화를 유지하고 시민권에 기초한 동등한 국가 건설에 참여하라”고 호소
“이웃 국가들과 그 국민들에게 평화와 선린의 손을 내민다”
선언문 낭독이 끝나고 팔레스타인 필하모닉 오케스트라가 ‘하티크바(희망)’를 연주했다. 참석자 250여 명이 기립하여 함께 불렀다. 이 곡은 이스라엘의 국가(國歌)가 되었다.
3. 국제 승인의 연쇄
독립 선언 직후 국제 사회의 반응은 빨랐다.
미국은 독립 선언 11분 만에 사실상의 승인(de facto recognition)을 부여했다. 이는 트루먼 대통령의 개인적 결단이었다. 국무부와 국방부의 반대를 무릅쓴 것이었으며, 트루먼의 측근 클라크 클리포드가 핵심 역할을 했다. 트루먼은 후일 “올바른 일이었다”고 회고했지만, 조지 마셜 국무장관은 “투표를 위한 결정이라면 나는 대통령에게 반대표를 던질 것”이라고까지 말했다는 기록이 있다.
소련은 5월 17일에 법률상의 승인(de jure recognition)을 부여했다. 미국보다 더 강한 수준의 공식 승인이었다. 소련의 동기는 복합적이었다. 영국의 중동 영향력을 약화시키려는 전략, 이스라엘 건국 운동 내 사회주의 세력(키부츠 운동, 마팜당 등)에 대한 기대, 그리고 아랍 왕정 국가들에 대한 견제가 함께 작용했다.
체코슬로바키아는 소련의 양해 아래 이스라엘에 결정적인 무기를 공급한 국가였다. 전쟁 초기 이스라엘 공군의 전투기 대부분이 체코제 아비아 S-199(메서슈미트 Bf 109의 체코 생산 버전)였다는 사실은 냉전 초기의 기묘한 지정학을 보여준다.
제5장: 아랍 국가들의 침공(1948년 5월 15일)
1. 다섯 나라의 군대
1948년 5월 15일 새벽, 영국 위임통치가 공식 종료되자마자 다섯 아랍 국가의 정규군이 팔레스타인에 진입했다.
이집트: 남부 네게브와 가자 방면으로 진격. 약 1만 명 규모.
트란스요르단(요르단): 아랍군단(Arab Legion)이 동쪽에서 진입, 예루살렘과 중부 지역을 목표로 삼았다. 영국인 장교 존 배고트 글럽(글럽 파샤)이 지휘하는 아랍 최정예 부대였다. 약 4,500~6,000명.
시리아: 북동부 갈릴리 방면으로 진격. 약 5,000~6,000명.
이라크: 요르단을 경유해 중부 전선에 투입. 약 3,000~5,000명.
레바논: 소규모 병력이 북부에서 진입. 약 1,000명.
이 외에도 사우디아라비아, 예멘 등이 소규모 병력을 파견했고, 아랍해방군과 무슬림형제단 의용군도 전투에 참여했다. 아랍 측 총 병력은 초기에 약 2만 5천~3만 명 수준이었다.
이스라엘 측은 하가나를 개편한 이스라엘 방위군(IDF, Israel Defense Forces)을 5월 26일 공식 창설했다. 이르군과 레히도 IDF에 통합되었다(일부 마찰 끝에). 초기 병력은 약 3만~3만 5천 명이었으나, 전쟁 기간 중 동원과 해외 이민자 유입으로 빠르게 증가하여 연말에는 약 10만 명에 달했다.
2. 전쟁의 전개 — 세 단계
제1단계: 아랍군의 초기 공세(5~6월)
가장 치열한 전투는 예루살렘에서 벌어졌다. 요르단의 아랍군단은 예루살렘 구시가지의 유대인 지구를 포위·공격하여 5월 28일 항복을 받아냈다. 구시가지 유대인 지구의 주민 약 1,500명은 추방되었고, 유대인 회당과 건물이 파괴되었다. 라트룬 요새를 둘러싼 전투에서도 이스라엘군은 요르단 아랍군단에 패배했다. 이집트군은 남부에서 키부츠 야드 모르데하이, 니짐 등을 공격하며 북쪽으로 진격했다.
그러나 아랍 국가들의 공세는 결정적 승리를 거두지 못했다. 아랍 국가들 사이의 불신과 비협조가 핵심 원인이었다. 트란스요르단의 압둘라 왕은 팔레스타인 아랍 국가 수립보다 자국 영토 확대에 관심이 있었고, 이집트의 파루크 왕도 마찬가지였다. 통합 군사 지휘 체계가 사실상 부재했다.
제2단계: 제1차 휴전과 이스라엘의 재무장(6~7월)
유엔 중재관 폴케 베르나도테 백작의 중재로 6월 11일부터 4주간의 제1차 휴전이 시행되었다. 이 휴전 기간은 이스라엘에게 결정적인 전환점이 되었다. 체코슬로바키아에서 대량의 무기가 도착했고, 해외(특히 유럽과 북미)에서 전투 경험이 있는 유대인 의용병들이 유입되었다. 병력은 약 6만 5천 명으로 증강되었다.
7월 8일 휴전이 만료되자 이스라엘군은 ’10일 전투(Ten Days’ Battles)’라 불리는 공세를 펼쳤다. 리다(로드)와 라믈레를 점령하고, 나자렛을 포함한 하부 갈릴리를 장악했다. 리다·라믈레 함락 시 약 5만~7만 명의 아랍 주민이 추방되었는데, 이츠하크 라빈(당시 여단장, 후일 총리)이 벤구리온의 지시에 따라 주민 추방을 실행했다는 기록이 라빈 자신의 회고록에 남아 있다.
제3단계: 이스라엘의 결정적 공세(10월~1949년 3월)
7월 18일부터 제2차 휴전이 시작되었으나, 10월 이후 이스라엘군은 결정적 군사 작전들을 연속으로 감행했다.
히람 작전(10월): 북부 갈릴리에서 아랍해방군과 레바논군을 격퇴, 갈릴리 전역 장악
요아브 작전(10월): 남부 네게브에서 이집트군을 격퇴, 베르셰바 점령
호레브 작전(12월~1949년 1월): 시나이 반도 진입까지 포함한 대규모 공세. 영국의 개입 위협으로 시나이에서 철수했으나 네게브의 대부분을 확보
전쟁이 끝날 무렵 이스라엘은 유엔 분할안에서 배정된 영토보다 약 50% 더 넓은 영역을 장악하고 있었다. 분할안 기준 56.5%에서 실제 약 78%로 확대된 것이다.
3. 휴전 협정(1949년)
1949년 2월부터 7월까지 유엔 중재 아래 이스라엘은 이집트, 레바논, 요르단, 시리아와 개별적으로 휴전 협정(Armistice Agreements)을 체결했다.
이집트(2월 24일): 가자 지구는 이집트가 관할. 시나이는 이집트 영토로 확인.
레바논(3월 23일): 위임통치 시대의 국경으로 복귀.
요르단(4월 3일): 요르단이 서안지구(웨스트뱅크)와 동예루살렘(구시가지 포함)을 장악. 이 지역을 1950년 공식 병합(국제사회 대부분은 이 병합을 승인하지 않았다).
시리아(7월 20일): 시리아군이 약간의 비무장지대를 남기고 철수.
중요한 점은, 이 협정들이 ‘평화 조약’이 아니라 ‘휴전 협정’이었다는 것이다. 아랍 국가들은 이스라엘의 존재를 인정하지 않았다. 국경이 아닌 ‘휴전선(Green Line)’이 그어졌다. 이 선은 오늘날까지 국제법적 논쟁의 기준점으로 남아 있다.
이라크는 이스라엘과 국경을 접하지 않았으므로 별도의 휴전 협정을 맺지 않았다. 이라크군은 요르단 영역으로 철수했다.
제6장: 나크바 — 팔레스타인의 대재앙
1. 나크바란 무엇인가
나크바(النكبة, al-Nakba)는 아랍어로 ‘대재앙’ 또는 ‘대참사’를 의미한다. 1948년 전쟁 과정에서 약 70만~75만 명(추정치에 따라 편차가 있으며, 유엔 기구 UNRWA의 공식 등록 기준으로는 약 72만 6천 명)의 팔레스타인 아랍 주민이 자신의 집과 마을을 떠나 난민이 된 사건을 총칭하는 말이다.
이 용어를 처음 체계적으로 사용한 것은 시리아 출신 역사가 콘스탄틴 주라이크로, 1948년 8월에 출간한 책 『대재앙의 의미(معنى النكبة)』에서 아랍 세계의 패배와 팔레스타인 주민의 이산을 ‘나크바’라 명명했다.
나크바의 규모를 수치로 정리하면 다음과 같다.
난민 수: 약 70만~75만 명 (위임통치령 팔레스타인 아랍 인구의 약 55~60%)
파괴·비워진 마을: 약 400~530개 (연구자에 따라 편차. 이스라엘 역사가 베니 모리스는 약 400개, 팔레스타인 연구자 왈리드 칼리디는 약 530개로 추산)
도시 이탈: 하이파, 야파, 리다, 라믈레, 아크레, 베르셰바 등 주요 도시의 아랍 주민 대부분이 떠남
난민 행선지: 서안지구, 가자 지구, 요르단, 레바논, 시리아, 이집트, 이라크 등
2. 떠난 이유 — 복합적 원인
팔레스타인 난민이 발생한 원인은 단일하지 않다. 역사 연구가 축적되면서 복수의 요인이 복합적으로 작용했음이 밝혀졌다. 이스라엘의 ‘신역사가(New Historians)’ — 베니 모리스, 일란 파페, 아비 슐라임 등 — 이 1980년대 이후 비밀 해제된 이스라엘 국방부·외무부 문서를 분석하면서 기존의 양측 공식 서사 모두에 수정이 가해졌다.
원인 1: 군사적 공격과 강제 추방
여러 사례에서 유대인 무장 세력(하가나, 이르군, 레히, 이후 IDF)이 아랍 주민을 직접 추방한 기록이 있다. 리다·라믈레의 경우가 대표적이다. 베니 모리스의 분석에 따르면 전체 난민의 상당 부분이 직접적 군사 작전의 결과로 발생했다. 일란 파페는 더 나아가 이를 ‘민족 청소(ethnic cleansing)’로 규정한다.
원인 2: 전투와 공포로 인한 자발적 피난
전투 지역의 민간인이 안전을 위해 피난한 사례도 많았다. 데이르 야신 학살 이후 퍼진 공포가 다른 마을 주민들의 선제적 대피를 촉진한 것은 확인된 사실이다. 이는 ‘자발적’이라고 할 수 있지만, 공포의 원인이 실제 발생한 학살이었다는 점에서 순수한 의미의 자발적 이동과는 구분된다.
원인 3: 아랍 지도부의 대피 명령설
이스라엘의 전통적 서사는 “아랍 지도자들이 전쟁 승리 후 귀환할 수 있다며 주민들에게 대피를 명령했다”고 주장해왔다. 이 주장에 대해 역사학적 검증이 이루어졌다. 일부 사례(하이파 등)에서 아랍 지도자가 대피를 권유한 기록이 있으나, 이것이 조직적·체계적인 ‘명령’이었다는 증거는 발견되지 않았다. 영국의 정보 보고서(1948년 6월)도 “아랍 이탈의 대부분은 유대인 세력의 군사적 행동에 의한 것”이라고 평가했다. 베니 모리스는 “아랍 라디오 방송이 주민들에게 떠나라고 명령했다는 주장은 근거가 빈약하다”고 결론지었다.
원인 4: 경제적 붕괴와 사회 구조 해체
전투가 장기화되면서 팔레스타인 아랍 사회의 경제·행정 기반이 무너졌다. 도시의 부유층과 중산층이 먼저 떠났고(전쟁 초기), 이들의 이탈은 나머지 주민의 생계와 사회적 결속력을 약화시켜 연쇄적인 이탈을 초래했다. 팔레스타인 아랍 사회에는 유대 기관(Jewish Agency)에 필적하는 통합된 정치 지도부가 없었다. 1930년대 대봉기 진압 과정에서 영국이 팔레스타인 아랍 지도부를 체계적으로 해체한 결과이기도 했다.
3. 귀환 불허 — 기정사실화
전쟁 중 그리고 전쟁 후, 이스라엘 정부는 떠난 아랍 주민의 귀환을 체계적으로 차단했다. 이것은 논쟁의 여지가 없는 확인된 사실이다.
1948년 6월, 이스라엘 임시 정부는 귀환 불허 정책을 공식 채택했다. 벤구리온은 같은 해 “아랍인의 귀환을 허용해서는 안 된다”고 내각에서 발언했다. 비워진 아랍 마을의 건물은 파괴되거나 유대인 이민자의 주거지로 전환되었다. 경작지는 이스라엘 국가 소유 또는 유대인 정착민에게 이전되었다.
1950년, 이스라엘 의회(크네세트)는 부재자 재산법(Absentees’ Property Law)을 통과시켰다. 이 법은 1948년 11월 29일 이후 팔레스타인을 떠난(혹은 국내에서도 원래 거주지를 떠난) 사람의 재산을 ‘부재자 재산’으로 분류하고, 국가가 관리·처분할 수 있도록 했다. 이로써 난민의 귀환과 재산 회복은 법적으로도 차단되었다.
4. 유엔 결의 194호와 귀환권 논쟁
1948년 12월 11일, 유엔 총회는 결의 194호를 채택했다. 이 결의의 11조는 다음과 같이 명시했다.
“귀환을 원하는 난민은 가능한 이른 시일 내에 자신의 집으로 돌아가 이웃과 평화롭게 살 수 있도록 허용되어야 하며, 귀환을 원하지 않는 자에 대해서는 국제법의 원칙에 따라 그 재산에 대한 보상이 이루어져야 한다.”
이 결의를 둘러싼 해석 논쟁은 70년 넘게 계속되고 있다.
팔레스타인/아랍 측: 결의 194호는 팔레스타인 난민의 ‘귀환권(right of return)’을 확립한 국제법적 근거다. 이스라엘은 이를 이행할 의무가 있다.
이스라엘 측: 총회 결의는 구속력이 없는 권고다. 또한 “이웃과 평화롭게 살기를 원하는” 조건이 붙어 있으므로 무조건적 귀환권이 아니다. 수백만 명에 달하는 난민 후손의 대규모 귀환은 유대 국가의 존립을 위협한다.
주목할 것은, 결의 194호 채택 당시 아랍 국가들이 이 결의에 반대표를 던졌다는 사실이다. 당시에는 이스라엘의 존재 자체를 인정하지 않았기 때문에, 이스라엘과 난민 간의 ‘협상’을 전제로 한 결의를 수용할 수 없었다. 이후 아랍·팔레스타인 측은 입장을 바꿔 결의 194호를 핵심 근거로 원용하게 되었다.
제7장: 두 개의 서사 — 같은 사실, 다른 틀
1. 이스라엘의 서사: 독립과 생존
이스라엘의 전통적 국가 서사는 다음과 같은 뼈대를 가지고 있다.
기원과 정당성: 유대 민족은 고대 이스라엘 왕국 시대부터 이 땅과 역사적·종교적 연속성을 가지고 있다. 2,000년의 디아스포라(이산) 동안에도 유대인들은 이 땅과의 유대를 유지했고, 소규모이나마 항상 이 땅에 거주하는 유대인 공동체가 있었다. 19세기 말 시온주의 운동은 박해받는 유대인의 민족 자결권을 실현하려는 정당한 움직임이었다.
홀로코스트와 도덕적 긴급성: 600만 유대인의 학살은 유대 국가의 필요성을 돌이킬 수 없이 증명했다. 세계 어느 나라도 유대인의 안전을 보장하지 못했으므로, 유대인 스스로의 국가만이 이러한 재앙의 반복을 막을 수 있다.
전쟁과 방어: 유대인은 유엔의 분할안을 수용했지만 아랍 측이 거부하고 전쟁을 시작했다. 독립 직후 다섯 아랍 국가의 침공을 받았으나 기적적으로 생존했다. 이것은 약자의 방어전이자 생존 전쟁이었다.
난민 문제: 전통적 이스라엘 서사에서 팔레스타인 난민은 전쟁의 불가피한 부산물이다. 아랍 지도자들이 전쟁을 시작했고, 일부는 주민에게 떠나라고 명령했다. 이스라엘은 잔류한 아랍인에게 시민권을 부여했다. 또한 아랍 국가들에서 추방당한 약 80만~85만 명의 유대인(‘미즈라히’ 유대인)이 이스라엘로 이주한 사실도 고려되어야 한다(사실상 ‘인구 교환’).
2. 팔레스타인의 서사: 상실과 부정의
팔레스타인의 서사는 근본적으로 다른 전제에서 출발한다.
원주민의 권리: 팔레스타인 아랍 주민은 수세기 동안 이 땅에 살아온 원주민이다. 인구의 3분의 2를 차지하던 이들의 동의 없이, 외부 강대국(영국)의 약속(밸푸어 선언)에 의해 그들의 땅이 다른 민족에게 양도되는 과정이 시작되었다. 이것은 식민주의의 한 형태다.
불의한 분할: 유엔 분할안은 인구의 33%인 유대인에게 영토의 56.5%를 주었다. 유대인 이민의 상당 부분은 위임통치 기간에 이루어진 것으로, 원주민의 의사에 반하여 진행되었다. 이러한 기정사실에 기초한 분할은 공정할 수 없다.
나크바는 계획적이었다: 팔레스타인 서사에서 나크바는 전쟁의 ‘부수적 피해’가 아니라 유대 국가의 인구학적 기반을 확보하기 위한 의도적 추방이다. 달렛 작전, 데이르 야신 학살, 리다·라믈레 추방 등은 체계적 패턴의 일부다.
계속되는 부정의: 나크바는 1948년에 끝난 단일 사건이 아니라, 귀환 불허, 재산 몰수, 마을 파괴, 그리고 이후의 점령과 정착촌 건설로 이어지는 ‘진행형 나크바(ongoing Nakba)’다.
3. 신역사가들의 기여 — 신화의 해체
1980년대 이후, 이스라엘의 ‘신역사가(New Historians)’들은 30년 비밀 해제 규정에 따라 공개된 정부 문서를 분석하여 양측의 공식 서사 모두에 도전했다. 주요 수정 사항은 다음과 같다.
베니 모리스(Benny Morris): 팔레스타인 난민 문제를 처음 체계적으로 연구한 역사가. 1988년 출간한 『팔레스타인 난민 문제의 탄생(The Birth of the Palestinian Refugee Problem)』에서 난민 발생의 원인이 복합적이었음을 밝혔다. 아랍 지도자의 ‘명령설’은 증거가 부족하며, 유대인 세력의 군사 작전이 주요 원인이었음을 문서로 입증했다. 다만 모리스는 2004년 개정판에서, 벤구리온이 체계적 추방을 ‘명령’하지는 않았으나 전장의 추방을 ‘묵인’하고 귀환을 ‘차단’했다고 분석했다.
일란 파페(Ilan Pappé): 더 급진적 입장에서 1948년 사건을 ‘민족 청소’로 규정했다. 2006년 저서 『팔레스타인의 민족 청소(The Ethnic Cleansing of Palestine)』에서 달렛 작전을 조직적 민족 청소 계획으로 해석했다. 파페의 분석은 팔레스타인 측 서사와 상당 부분 일치하지만, 다른 역사가들로부터 사료 해석의 과도한 선택성에 대해 비판을 받기도 한다.
아비 슐라임(Avi Shlaim): 압둘라 왕과 유대 기관 사이의 비밀 교섭을 밝혔다. 양측이 팔레스타인 아랍 국가의 탄생을 막기 위해 사실상 공모했다는 주장이다. 요르단이 서안지구를 병합하고, 이스라엘이 나머지를 갖는 ‘암묵적 합의’가 존재했다는 것이다.
신역사가들의 연구는 이스라엘 사회 내에서 격렬한 논쟁을 일으켰다. 전통적 서사를 훼손한다는 비판, 자국의 건국 신화를 해체한다는 분노, 반대로 역사적 정직성의 용기라는 칭찬이 교차했다. 이들의 연구는 학문적 정밀함의 편차에도 불구하고, 1948년에 대한 이해를 결정적으로 풍부하게 만들었다.
제8장: 전쟁의 인적 비용
1. 인명 피해
1948년 전쟁의 인적 비용은 양측 모두에게 참혹했다.
이스라엘 측: 약 6,373명 사망(전체 유대인 인구의 약 1%). 이 중 약 4,000명이 군인, 나머지가 민간인. 이스라엘은 이 전쟁을 ‘독립전쟁(מלחמת העצמאות)’이라 부른다.
아랍 측(팔레스타인 및 아랍 국가 군대): 정확한 수치는 확인하기 어렵다. 추정치는 아랍 국가 정규군 약 7,000~10,000명, 팔레스타인 전투원과 민간인 수천 명. 전체적으로 1만~1만 5천 명 범위로 추산된다.
난민: 70만~75만 명의 팔레스타인 아랍인이 난민이 됨. 이스라엘에 남은 아랍인은 약 15만~16만 명.
2. 이스라엘에 남은 아랍인 — ’48 아랍인’
전쟁 후 이스라엘 국경 안에 남은 약 15만~16만 명의 아랍인은 이스라엘 시민권을 받았으나, 1966년까지 군사 정부(military administration) 아래 놓였다. 이들은 여행의 자유, 거주지 선택, 토지 소유 등에서 제약을 받았다. 군사 정부는 1966년에 해제되었고, 이후 이스라엘 내 아랍 시민(오늘날 약 200만 명, 이스라엘 인구의 약 21%)은 투표권과 시민권을 가지고 있으나, 사실상의 차별과 불평등이 지속되고 있다는 비판도 존재한다.
3. 아랍 국가 내 유대인의 이탈
1948년 전쟁과 이스라엘 건국은 아랍·이슬람 국가에 거주하던 유대인 공동체에도 격변을 가져왔다. 이라크, 예멘, 이집트, 모로코, 리비아, 시리아, 튀니지 등에서 약 80만~85만 명의 유대인이 1948년부터 1970년대에 걸쳐 이주했다. 대부분이 이스라엘로 향했고, 일부는 프랑스 등 유럽으로 갔다.
이 이주의 성격도 논쟁 대상이다. 이스라엘 측은 아랍 국가의 박해와 추방에 의한 ‘유대인 나크바’라고 주장한다. 아랍 측은 이스라엘 정부(특히 모사드)가 아랍 국가 유대인의 이주를 의도적으로 촉진한 사례가 있다고 반박한다. 이라크의 경우, 1950~1951년 바그다드에서 유대인 대상 폭탄 테러가 발생했는데, 이것이 이라크 정부의 소행인지 이스라엘 공작원의 소행인지에 대해서는 여전히 결론이 나지 않았다. 사실은, 원인이 어디에 있든 수천 년 역사를 가진 중동 유대인 공동체가 사실상 소멸했다는 것이다.
제9장: 1948년 이후 — 만들어진 새로운 현실
1. 이스라엘 — 국가 건설과 대량 이민
신생 이스라엘은 즉각적인 과제에 직면했다. 가장 시급한 것은 인구였다. 1948년 약 80만 명이던 유대인 인구를 늘리기 위해 귀환법(Law of Return, 1950)이 제정되었다. 이 법은 세계 어디에 있든 유대인이면 이스라엘에 이민할 권리가 있다고 규정했다. 홀로코스트 생존자, 아랍 국가 출신 유대인, 동유럽 유대인이 대거 유입되어 1950년대 초반에 인구가 두 배로 증가했다.
비워진 아랍 마을과 도시의 가옥은 새 이민자의 주거지가 되었다. 야파의 아랍인 가옥에 예멘 유대인이 입주하고, 갈릴리의 아랍 마을 터에 새 유대인 정착촌이 세워졌다. 이 과정은 기존 아랍 주민의 귀환을 물리적으로도 불가능하게 만들었다.
2. 팔레스타인 난민 — 임시가 영구가 되다
70만이 넘는 팔레스타인 난민은 주변 아랍 국가의 난민 캠프에 수용되었다. 유엔은 1949년 팔레스타인 난민 구호기관(UNRWA, United Nations Relief and Works Agency)을 설립하여 난민 지원을 담당하게 했다. ‘임시’ 기구로 설립된 UNRWA는 오늘날까지 존속하고 있으며, 등록 난민 수는 후손을 포함하여 약 590만 명(2023년 기준)에 달한다.
난민 캠프는 레바논, 시리아, 요르단, 서안지구, 가자 지구에 설치되었다. 처음에는 텐트촌이었던 캠프가 점차 콘크리트 건물로 바뀌었지만, ‘임시’라는 명목은 유지되었다. 난민들은 집 열쇠를 간직한 채 귀환의 날을 기다렸고, 이 열쇠는 팔레스타인 정체성의 상징이 되었다.
각 수용국에서의 난민 처우는 달랐다.
요르단: 유일하게 팔레스타인 난민에게 시민권을 부여한 아랍 국가. 인구의 절반 이상이 팔레스타인 출신으로, 정치적 긴장도 있었다(1970년 ‘검은 9월’ 사태).
레바논: 종파 균형을 우려하여 시민권 부여를 거부. 난민은 특정 직업에서 배제되고 부동산 소유가 제한되었다. 캠프는 사실상의 게토가 되었다.
시리아: 시민권은 부여하지 않았으나 비교적 광범위한 사회적 권리를 보장했다. 2011년 시리아 내전은 팔레스타인 난민에게 ‘이중 난민’의 비극을 안겼다.
가자 지구: 이집트 관할 아래 난민 캠프가 밀집. 1967년 이스라엘 점령 이후 상황이 더 악화되었다.
3. 아랍 세계의 충격 — ’48년의 트라우마’
1948년의 패배는 아랍 세계 전체에 심대한 정치적 충격을 주었다. 기존의 아랍 왕정·보수 정권은 패전의 책임을 추궁받았다.
이집트: 1952년, 자유장교단이 쿠데타를 일으켜 파루크 왕을 축출했다. 가말 압델 나세르가 권력을 장악하며 ‘아랍 민족주의’의 시대가 열렸다. 나세르의 부상은 1948년 패전과 직결된다.
시리아: 1949년에만 세 차례의 쿠데타가 일어났다. 이후 수십 년간 정치적 불안정이 계속되었다.
요르단: 압둘라 왕은 서안지구를 병합하여 영토를 확대했으나, 1951년 예루살렘의 알아크사 모스크에서 팔레스타인인에 의해 암살되었다. 이스라엘과의 비밀 교섭이 ‘배신’으로 인식된 결과였다.
이라크: 패전의 치욕이 1958년 하심 왕조 타도 혁명의 원인 중 하나가 되었다.
이처럼 1948년 전쟁은 패전 당사국들의 정치 체제까지 뒤흔들었다. 그리고 이 정치적 격변은 다시 아랍-이스라엘 분쟁의 다음 장(1956년 수에즈 위기, 1967년 6일 전쟁)으로 이어진다.
제10장: 1948년의 유산 — 풀리지 않은 매듭
1. 난민 문제의 고착화
2026년 현재, 팔레스타인 난민 문제는 세계에서 가장 오래 지속되는 난민 위기다. UNRWA에 등록된 난민은 약 590만 명으로, 원래 난민(1948년 이탈자)의 후손 대부분이 포함된다. 이스라엘은 대규모 귀환을 거부하고 있고, 아랍 수용국 중 요르단을 제외하면 시민권 부여에 소극적이며, 국제사회는 해결 방안에 합의하지 못하고 있다.
난민 문제가 고착된 데에는 양측의 요인이 있다. 이스라엘은 유대 국가의 인구학적 특성 유지를 이유로 귀환을 거부한다. 일부 아랍 국가는 이스라엘에 대한 정치적 압력 카드로 난민의 ‘임시’ 지위를 유지해왔다는 비판을 받는다. 팔레스타인 난민 자신은 어디에서도 완전한 시민으로 받아들여지지 못한 채 ‘떠 있는 존재’로 세대를 이어왔다.
2. 기억의 전쟁
1948년은 사실의 영역만큼이나 기억의 영역에서 중요하다. 양측은 자신의 서사를 다음 세대에 전달하기 위해 치열하게 경쟁한다.
이스라엘에서는 매년 욤 하아츠마우트(독립기념일)를 축하하되, 그 전날은 욤 하지카론(전몰장병 추모일)으로 기린다. 슬픔에서 기쁨으로의 극적 전환이 국가 서사의 핵심 구조다.
팔레스타인에서는 매년 5월 15일을 나크바의 날로 기억한다. 검은 옷, 열쇠 모형, 옛 마을의 이름을 적은 표지판이 시위와 기념 행사에 동원된다. 2011년 이스라엘 의회는 나크바를 기념하는 기관에 대한 정부 지원을 삭감할 수 있는 ‘나크바 법’을 통과시켜 논란이 되었다.
양측의 교과서도 1948년을 전혀 다르게 서술한다. 이스라엘 교과서에 ‘나크바’라는 단어는 거의 등장하지 않거나 최근에야 일부 언급되기 시작했다. 팔레스타인 교과서에서 이스라엘은 정당한 국가가 아닌 ‘식민 기획(colonial project)’으로 프레이밍된다. 상대방의 고통을 인정하는 것이 자신의 서사를 약화시킨다는 두려움이 양측 모두에 존재한다.
3. 역사가 우리에게 요구하는 것
1948년의 역사를 정직하게 마주하려면, 불편한 복수의 진실을 동시에 인정해야 한다.
홀로코스트라는 전대미문의 참극을 겪은 유대인에게 안전한 고향이 필요했다는 것은 사실이다.
그 고향이 다른 사람들이 이미 살고 있던 땅에 세워졌고, 그 과정에서 대규모의 추방과 파괴가 발생했다는 것도 사실이다.
아랍 국가들의 침공이 신생 이스라엘의 존립을 위협했다는 것은 사실이다.
그 전쟁 과정에서 팔레스타인 민간인에 대한 체계적 폭력과 추방이 이루어졌다는 것도 사실이다.
아랍 국가 내 유대인 공동체가 사실상 소멸한 것은 사실이다.
팔레스타인 난민이 70년 넘게 귀환하지 못하고 있는 것도 사실이다.
이 사실들은 서로를 상쇄하지 않는다. 한쪽의 고통이 다른 쪽의 고통을 정당화하지 않는다. 1948년의 역사는 ‘선과 악’의 이분법으로 정리될 수 없으며, 바로 그 복잡성이 이 갈등을 세계에서 가장 풀기 어려운 문제 중 하나로 만들고 있다.
나가며 — 끝나지 않은 1948년
1948년은 과거가 아니다. 그 해에 만들어진 현실 — 이스라엘이라는 국가, 팔레스타인 난민 문제, 미해결의 국경, 예루살렘의 분쟁, 양측의 상처 — 은 모두 현재 진행형이다. 2026년 오늘도 가자와 서안에서 이 ‘끝나지 않은 1948년’의 여파가 매일의 뉴스를 만들고 있다.
역사가의 임무는 편을 드는 것이 아니라 사실을 밝히고, 각 사실이 어떤 맥락에서 발생했는지를 보여주는 것이다. 우리는 이 시리즈에서 그 원칙을 지키며 걸어왔고, 앞으로도 그렇게 할 것이다.
다음 47화에서는 1948년 이후 중동을 뒤흔든 아랍 민족주의의 부상과 나세르의 시대를 다룬다. 1948년의 패배가 어떻게 아랍 세계의 정치적 지형을 근본적으로 바꿔놓았는지, 그리고 그 변화가 어떻게 다음 전쟁(1956년 수에즈, 1967년 6일 전쟁)의 씨앗을 뿌렸는지를 살펴볼 것이다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: 중동의 역사 (총 52화 중 46화) ◀ 이전 45화 (다음 차수는 아직 게시되지 않았습니다)
IT 업계 20년 차 직장인의 생활스포츠지도사 2급 필기 도전기, 열일곱 번째 이야기입니다. 지난 16화까지 스포츠교육학·사회학·심리학·윤리 네 과목을 3회씩 총 12회에 걸쳐 훑었습니다. 이 네 과목은 ‘이해형’ 혹은 ‘상식형’ 문제가 주를 이뤘기에 비전공자도 비교적 진입 장벽이 낮았죠. 그런데 오늘부터 시작하는 운동생리학은 분위기가 확 달라집니다.
수험생 커뮤니티에 가면 “생리학 때문에 떨어졌다”, “외울 게 끝이 없다”, “ATP-PC가 뭔지도 모르겠다”는 하소연이 넘칩니다. 실제로 운동생리학은 7과목 중 체감 난이도 1~2위를 다투는 과목입니다. 하지만 동시에 “패턴만 잡으면 안정적으로 60점 이상 가능하다”는 합격 후기도 적지 않습니다.
이번 17화에서는 운동생리학의 출제 경향을 데이터로 분석하고, 방대해 보이는 암기량 속에 숨어 있는 반복 패턴을 찾아냅니다. 패턴을 먼저 잡으면 18화(빈출 키워드 정리)와 19화(기출 함정 공략)가 훨씬 수월해질 겁니다.
운동생리학, 어떤 과목인가
과목 정의와 시험에서의 위치
운동생리학(Exercise Physiology)은 운동이 인체의 생리적 기능에 미치는 영향을 연구하는 학문입니다. 심장이 왜 빨리 뛰는지, 근육이 어떻게 수축하는지, 에너지는 어디서 나오는지—이 모든 것을 다룹니다.
생활스포츠지도사 2급 필기시험에서 운동생리학은 필수 과목이 아니라 선택 과목입니다. 7과목(스포츠교육학·사회학·심리학·윤리·운동생리학·운동역학·한국체육사) 중 5과목을 골라야 하죠. 3화에서 정리한 비전공자 추천 조합 BEST 3을 기억하시나요? 운동생리학은 ‘도전 조합’에 포함되는 과목이었습니다.
그런데 왜 많은 수험생이 굳이 운동생리학을 선택할까요?
실기·구술 시험과의 연계성: 실기·구술 단계에서 “이 운동이 왜 효과적인가”를 설명하려면 생리학 지식이 필수입니다. 필기에서 공부해 두면 실기 준비가 한결 수월해집니다.
자격증 취득 후 실무 활용도: 지도 현장에서 회원에게 “왜 유산소를 먼저 하세요”라고 설명하려면 에너지 시스템을 알아야 합니다.
한국체육사·운동역학 회피: 한국체육사의 연대·인물 암기나 운동역학의 물리 공식이 더 부담스러운 수험생이 생리학을 선택합니다.
출제 패턴의 예측 가능성: 범위는 넓지만, 실제로 시험에 나오는 토픽은 반복됩니다. 패턴을 잡으면 안정적 점수 확보가 가능합니다.
운동생리학의 하위 영역 구분
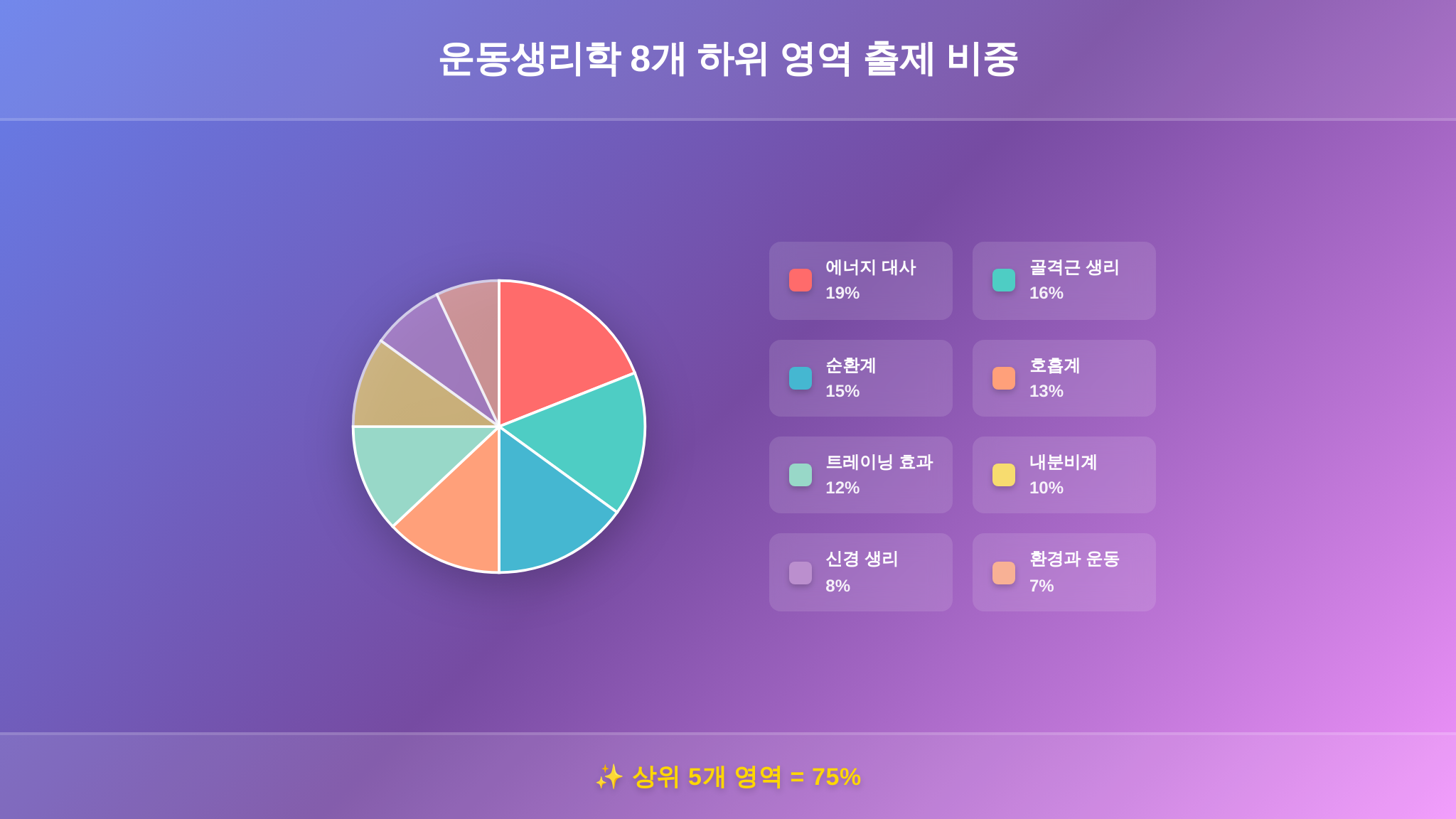
시험 범위를 이해하려면 먼저 운동생리학이 다루는 하위 영역을 파악해야 합니다. 교재마다 분류가 조금씩 다르지만, 시험 출제 기준으로 크게 다음 8개 영역으로 나눌 수 있습니다.
① 에너지 대사: ATP 생성 경로, 무산소·유산소 시스템, 젖산 역치
② 골격근 생리: 근섬유 유형, 근수축 기전, 운동 단위
③ 신경 생리: 신경-근 접합부, 감각 수용기, 반사 반응
④ 순환계: 심박출량, 혈압, 혈류 재분배, 심장 적응
⑤ 호흡계: 환기량, 가스 교환, 산소 해리 곡선, 최대산소섭취량(VO₂max)
⑥ 내분비계: 운동 관련 호르몬, 카테콜아민, 인슐린, 성장호르몬
⑦ 환경과 운동: 고온·저온·고지대 환경, 체온 조절, 수분 보충
⑧ 트레이닝 효과: 과부하 원리, 초과 회복, 디트레이닝, 연령·성별 차이
여덟 개 영역이라니, 벌써 숨이 막히시죠? 하지만 걱정 마세요. 이 여덟 영역이 균등하게 출제되지 않습니다. 출제 비중에 뚜렷한 편차가 있고, 바로 그 편차가 우리의 학습 전략을 결정합니다.
상위 3개 영역(에너지 대사 + 골격근 + 순환계)이 전체의 50%를 차지합니다. 20문항 중 10문항입니다.
여기에 호흡계와 트레이닝 효과까지 더하면 상위 5개 영역이 75%입니다. 20문항 중 15문항.
신경 생리·내분비·환경 운동은 합쳐서 5문항 내외. 난이도도 높아서 가성비가 떨어집니다.
결론: 에너지 대사 → 골격근 → 순환계 → 호흡계 → 트레이닝 효과 순서로 공부하되, 이 다섯 영역에 학습 시간의 80%를 투자하는 것이 합리적입니다.
연도별 트렌드 변화
5개년을 좀 더 세밀하게 살펴보면 흥미로운 트렌드가 보입니다.
에너지 대사: 매년 3~4문항으로 가장 안정적. ATP-PC, 해당과정, 산화적 인산화는 “연례 출석 체크” 수준.
순환계: 2023년부터 출제 비중이 소폭 상승. 특히 심박출량 공식(심박수 × 1회 박출량)과 혈류 재분배 문제가 최근 2년 연속 출제.
트레이닝 효과: 2024~2025년에 초과 회복(supercompensation)과 가역성 원리 문제 증가. 실무 연계형 문제로 변화하는 추세.
환경과 운동: 2025년에 열사병·탈수 관련 2문항이 나오며 비중 급증. 기후 변화·여름 스포츠 안전이 사회적 이슈가 된 영향으로 보입니다.
내분비계: 과거 대비 출제 빈도가 줄고 있으나, 나오면 난이도가 높은 편. 호르몬 이름과 기능을 1:1 매칭하는 유형.
문제 유형 분석
운동생리학의 문제 유형은 크게 네 가지로 나뉩니다.
개념 정의형 (35%): “다음 중 ○○에 대한 설명으로 옳은 것은?” — 용어의 정확한 정의를 묻습니다.
비교·구분형 (30%): “속근 섬유와 지근 섬유의 차이로 옳지 않은 것은?” — 두 개념의 차이를 표로 정리해야 풀 수 있습니다.
인과관계형 (20%): “장기간 유산소 운동 시 안정 시 심박수가 감소하는 이유는?” — 기전(mechanism)을 이해해야 합니다.
수치·공식형 (15%): “최대심박수 추정 공식”, “심박출량 계산”, “VO₂max 해석” — 공식 자체를 외워야 합니다.
주목할 점은 65%의 문제가 “정의”와 “비교”라는 것입니다. 이 두 유형은 표 하나 만들어서 반복 읽기하면 대응할 수 있습니다. 인과관계형도 결국 “A하면 B가 되고, B가 되면 C가 된다”는 연쇄 흐름을 한 번 그려 보면 기억에 남습니다. 가장 까다로운 수치·공식형은 15%에 불과하니, 핵심 공식 10개만 확실히 외우면 됩니다.
왜 “암기량이 많다”고 느끼는가
다른 과목과의 비교
운동생리학의 암기 부담을 객관적으로 비교해 봅시다. 지금까지 다룬 네 과목과 나란히 놓겠습니다.
비교 항목
교육학
사회학
심리학
윤리
운동생리학
핵심 키워드 수
약 80개
약 70개
약 90개
약 60개
약 150개
외울 공식·수치
0
0
2~3개
0
10~15개
표로 정리할 비교쌍
5~6쌍
4~5쌍
6~7쌍
3~4쌍
12~15쌍
학자 이름 매칭
8~10명
6~8명
15~20명
5~6명
5~8명
체감 난이도
중
중
중상
하
상
핵심 키워드가 150개로 다른 과목의 약 2배입니다. 여기에 공식·수치 암기, 비교쌍 정리까지 더해지니 체감 부담이 클 수밖에 없죠. 다만 학자 이름 매칭은 심리학보다 적습니다. 운동생리학은 “사람 이름보다 용어·기전·숫자”를 더 많이 묻는 과목입니다.
암기 부담이 커지는 세 가지 이유
150개 키워드라는 숫자 자체보다, 암기를 어렵게 만드는 구조적 이유가 있습니다.
첫째, 유사 용어의 혼동. 운동생리학에는 비슷하게 생긴 용어가 넘칩니다.
해당과정(glycolysis) vs 당신생(gluconeogenesis)
1회 박출량(stroke volume) vs 심박출량(cardiac output)
조일회호흡량(tidal volume) vs 분당환기량(minute ventilation)
등장성 수축(isotonic) vs 등척성 수축(isometric) vs 등속성 수축(isokinetic)
운동 단위(motor unit) vs 운동 뉴런(motor neuron)
이 용어들이 보기 4개에 섞여 나오면, 정확히 구분하지 못하는 순간 오답을 고르게 됩니다.
둘째, 연쇄적 기전의 길이. 스포츠윤리에서 “도핑은 나쁘다”는 한 문장이면 되지만, 운동생리학에서 “운동 시 심박수가 증가하는 이유”를 설명하려면 이런 연쇄가 필요합니다:
운동 시작 → 교감신경 활성화 → 부신수질에서 아드레날린 분비 → 동방결절(SA node) 자극 → 심박수 증가 → 1회 박출량 증가 → 심박출량 증가 → 근육 혈류 증가
이 체인에서 한 고리라도 빠지면 “왜?”라는 질문에 답할 수 없습니다.
셋째, 일상 경험과의 괴리. 스포츠윤리의 “페어플레이”나 심리학의 “동기”는 일상에서 직관적으로 이해되지만, “피루브산이 미토콘드리아로 들어간다”는 문장은 일상 경험과 연결 고리가 없습니다. 연결 고리가 없으면 기억이 오래 가지 않습니다.
그런데, 정말 150개를 다 외워야 할까?
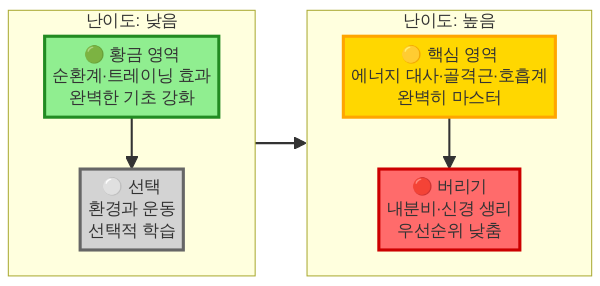
답부터 말하면 아닙니다. 150개 키워드 중 실제 시험에 반복 출제되는 것은 60~70개입니다. 나머지 80~90개는 3~5년에 한 번 나올까 말까 한 “꼬리 키워드”입니다.
합격 전략은 명확합니다:
1순위 60~70개: 완벽 암기 (이것만으로 12~14문항 커버)
2순위 30~40개: 개념 이해 수준 (보기에서 소거법 가능)
3순위 나머지: 과감히 버리기 (시험장에서 찍기)
60점(12문항) 합격이 목표라면, 1순위만 확실히 해도 충분합니다. 안정적으로 70점(14문항)을 노린다면 2순위까지 훑으면 됩니다.
패턴이 있다 — 운동생리학 출제의 5대 프레임워크
여기서부터가 오늘의 핵심입니다. 운동생리학의 기출 문제를 반복해서 풀다 보면, 150개 키워드가 무작위로 나오는 게 아니라 5개의 프레임워크 안에서 돌고 돈다는 걸 알 수 있습니다. 이 프레임워크를 먼저 머릿속에 설치하면, 개별 키워드가 프레임 안의 빈칸 채우기처럼 자연스럽게 들어맞습니다.
프레임워크 1: 에너지 공급 3단계 (ATP 생성 경로)
운동생리학에서 매년 빠짐없이 출제되는 절대 핵심입니다. 5개년 기출을 보면 이 프레임워크 하나에서만 매년 2~3문항이 나옵니다.
인체가 운동할 때 에너지를 만드는 방식은 세 가지입니다:
구분
ATP-PC 시스템
무산소성 해당과정
유산소 시스템(산화적 인산화)
별명
인원질 시스템
젖산 시스템
산화 시스템
산소 필요
불필요
불필요
필요
에너지원
크레아틴인산(PC)
글리코겐(포도당)
탄수화물·지방·(단백질)
ATP 생성 속도
가장 빠름
빠름
느림
ATP 생성량
매우 적음 (1~2 ATP)
적음 (2 ATP)
많음 (36~38 ATP)
지속 시간
0~10초
10초~2분
2분 이상
부산물
크레아틴
젖산(락테이트)
CO₂ + H₂O
대표 운동
100m 스프린트, 투포환
400m 달리기, 50m 수영
마라톤, 사이클링
피로 원인
PC 고갈
젖산 축적 → pH 저하
글리코겐 고갈, 탈수
회복
30초~2분
20분~1시간
24~72시간
이 표 하나가 운동생리학 점수의 10~15%를 책임집니다. 시험장에 가기 전 이 표를 한 장으로 출력해서 마지막까지 보세요.
출제 패턴 분석:
“ATP-PC 시스템에 대한 설명으로 옳은 것은?” → 지속 시간, 산소 필요 여부, 부산물이 보기에 섞여 나옴
“400m 달리기에서 주로 사용되는 에너지 시스템은?” → 대표 운동 매칭
“유산소 시스템의 특징으로 옳지 않은 것은?” → 오답 보기에 “ATP 생성 속도가 가장 빠르다”가 자주 삽입
“장시간 운동 시 에너지 기질의 변화 순서는?” → 탄수화물 → 지방 비율 변화 (크로스오버 개념)
암기 팁 — “속·양·시간” 역삼각형: ATP-PC는 속도 최고, 양 최소, 시간 최단이고, 유산소는 정반대입니다. 세 시스템이 속도-양-시간에서 정확히 역순이라는 걸 기억하면, 표를 통째로 외우지 않아도 논리적으로 재구성할 수 있습니다.
프레임워크 2: 안정 시 vs 운동 시 비교
운동생리학 문제의 30% 이상이 이 프레임워크를 사용합니다. “운동할 때 몸에 어떤 변화가 일어나는가?”라는 단순한 질문이지만, 각 계통별로 물으면 문제가 끝없이 나옵니다.
생리 지표
안정 시
운동 시 (급성 반응)
방향
심박수
60~80회/분
최대 200회/분 내외
↑↑
1회 박출량
약 70mL
약 100~120mL
↑
심박출량
약 5L/분
약 20~25L/분
↑↑↑
수축기 혈압
120mmHg
180~220mmHg
↑↑
이완기 혈압
80mmHg
변화 없음 또는 소폭 하강
→ 또는 ↓
분당환기량
약 6L/분
약 100~150L/분
↑↑↑
호흡수
12~20회/분
40~60회/분
↑↑
근혈류량
전체 혈류의 15~20%
전체 혈류의 80~85%
↑↑↑
내장 혈류량
높음
감소 (혈류 재분배)
↓↓
체온
36.5~37°C
38~40°C
↑
혈중 젖산
1~2mmol/L
10~20mmol/L (고강도)
↑↑
혈중 카테콜아민
낮음
급증
↑↑↑
이 표가 중요한 이유는 “방향”만 기억하면 절반 이상의 보기를 소거할 수 있기 때문입니다. 예를 들어 “운동 시 이완기 혈압이 급격히 상승한다”는 보기가 나오면 → (변화 없음/소폭 하강)이므로 즉시 오답 처리.
출제 패턴:
“운동 시 심혈관 반응으로 옳은 것은?” — 심박출량, 혈압, 혈류 재분배 중 하나
“고강도 운동 시 혈류가 감소하는 기관은?” — 내장(위장관, 간, 신장)
“운동 시 호흡 반응으로 옳지 않은 것은?” — 보통 “잔기량이 크게 증가한다”가 오답 보기
암기 팁 — “운동하면 거의 다 올라간다”: 위 표에서 내려가는 건 딱 두 가지뿐입니다 — 이완기 혈압(변화 없음~소폭 하강)과 내장 혈류량. “운동하면 다 올라간다, 내려가는 건 내장 혈류와 이완기 혈압”이라고 외우면 소거법의 강력한 무기가 됩니다.
프레임워크 3: 급성 반응 vs 만성 적응
이 프레임워크는 프레임워크 2의 확장입니다. “운동 한 번 했을 때의 변화(급성 반응)”와 “몇 주~몇 달 꾸준히 운동했을 때의 변화(만성 적응)”를 구분하는 것이죠.
생리 지표
급성 반응 (1회 운동)
만성 적응 (장기 트레이닝)
안정 시 심박수
운동 전과 동일
감소 (서맥, bradycardia)
최대 심박수
연령에 의해 결정
변화 없음 또는 소폭 감소
1회 박출량
일시적 증가
증가 (심실 비대, 혈장량 증가)
최대 심박출량
운동 강도에 비례
증가 (1회 박출량 증가 덕분)
VO₂max
해당 없음
증가 (유산소 능력 향상)
젖산 역치
해당 없음
상승 (더 높은 강도까지 젖산 축적 지연)
근섬유 크기
일시적 팽창 (펌핑)
비대 (저항 운동 시)
미토콘드리아
변화 없음
수·크기 증가 (유산소 운동 시)
모세혈관 밀도
변화 없음
증가 (가스 교환 효율 향상)
골밀도
변화 없음
증가 (체중 부하 운동 시)
체지방률
미미한 소비
감소
이 프레임워크에서 시험에 가장 자주 나오는 함정은 “최대 심박수는 트레이닝으로 증가한다”는 오답 보기입니다. 최대 심박수는 주로 나이에 의해 결정되며, 트레이닝의 효과로 늘어나지 않습니다(220-나이 공식). 이 한 가지만 알아도 매년 1문항은 맞출 수 있습니다.
출제 패턴:
“장기간 유산소 트레이닝의 효과로 옳지 않은 것은?” — 단골 출제. 오답 보기: “최대 심박수 증가” / “안정 시 심박수 증가”
“저항 운동의 만성 적응으로 옳은 것은?” — 근비대, 근력 증가, 운동 단위 동원 향상
“유산소 훈련과 저항 훈련의 적응 차이를 비교한 것으로 옳은 것은?” — 유산소=미토콘드리아↑, 모세혈관↑ / 저항=근섬유 크기↑, 근력↑
암기 팁 — “안정 시 심박수 DOWN, 나머지 UP”: 만성 적응의 핵심 메시지는 “몸이 효율적으로 변한다”입니다. 같은 일을 덜 힘들게 할 수 있게 되니, 안정 시에는 심장이 천천히 뛰고(DOWN), 최대 능력치는 올라갑니다(UP). 최대 심박수만 예외적으로 변하지 않는다는 것, 꼭 기억하세요.
프레임워크 4: A형 vs B형 이분법 비교
운동생리학에서 “비교·구분형” 문제가 30%를 차지한다고 했죠? 그 30%를 책임지는 프레임워크가 바로 이것입니다. 운동생리학에는 “A vs B” 형태의 이분법 비교가 유독 많습니다.
빈출 비교쌍 12개:
#
비교쌍
핵심 구분 포인트
1
속근(Type II) vs 지근(Type I)
수축 속도, 피로 저항, 미토콘드리아 밀도, 색상(백/적)
2
유산소 vs 무산소
산소 사용 여부, 에너지원, 지속 시간, 부산물
3
등장성 vs 등척성 수축
관절 움직임 유무, 장력-길이 관계
4
구심성 vs 원심성 수축
근육 길이 변화 방향, DOMS(지연성 근통증) 관련
5
교감신경 vs 부교감신경
심박수·혈압 조절, fight-or-flight vs rest-and-digest
6
수축기 혈압 vs 이완기 혈압
운동 중 변화 방향(↑↑ vs →↓)
7
외호흡 vs 내호흡
가스 교환 장소(폐포 vs 조직 모세혈관)
8
VO₂max vs 젖산 역치
유산소 능력의 절대값 vs 상대적 지점
9
인슐린 vs 글루카곤
혈당 조절 방향(↓ vs ↑)
10
과부하 원리 vs 가역성 원리
자극 증가 → 적응 vs 자극 중단 → 퇴화
11
심근(cardiac) vs 골격근(skeletal)
불수의/수의, 섬유 형태, 피로 저항
12
근비대(hypertrophy) vs 근증식(hyperplasia)
섬유 크기 증가 vs 섬유 수 증가(인간에선 미미)
이 12개 비교쌍을 표 한 장씩 정리해 놓으면, 비교·구분형 문제의 80% 이상에 대응할 수 있습니다. 18화에서 각 비교쌍의 세부 키워드를 꼼꼼히 정리할 예정이지만, 오늘은 “이런 비교쌍이 있다”는 것을 머리에 넣어 두세요.
암기 팁 — 비교쌍은 “한쪽만 확실히”: 속근과 지근을 둘 다 외우려 하지 마세요. 지근(Type I)의 특징만 확실히 외우면, 속근은 “지근의 반대”로 자동 도출됩니다. 지근 = 느림(Slow) = 적색 = 미토콘드리아 多 = 유산소 = 피로 저항 高. 이걸 외우면 속근은 빠름 = 백색 = 미토콘드리아 少 = 무산소 = 피로 빠름이 됩니다.
프레임워크 5: 수치·공식 10선
운동생리학에서 외워야 할 공식은 많지 않습니다. 하지만 나오면 정확히 알아야 맞출 수 있으므로, 핵심 10개를 여기 모아 둡니다.
#
공식/수치
내용
출제 빈도
1
심박출량 = 심박수 × 1회 박출량
Q = HR × SV
★★★★★
2
최대심박수 ≈ 220 – 나이
예: 40세 → 180회/분
★★★★★
3
Fick 공식: VO₂ = Q × (a-v)O₂차
산소섭취량 = 심박출량 × 동정맥 산소차
★★★★
4
분당환기량 = 호흡수 × 1회 호흡량
VE = f × TV
★★★★
5
카르보넨 공식(목표 심박수)
THR = (HRmax – HRrest) × 강도% + HRrest
★★★★
6
안정 시 심박출량 ≈ 5L/분
HR 70 × SV 70mL
★★★
7
혈압 = 심박출량 × 총말초저항
BP = Q × TPR
★★★
8
ATP-PC 시스템 지속: ~10초
전력 질주 한계
★★★
9
MET (대사당량) = 3.5mL/kg/min
안정 시 산소섭취량 기준
★★★
10
RER(호흡교환율) 1.0 이상 = 무산소 의존 증가
VCO₂/VO₂, 지방 0.7 / 탄수화물 1.0
★★
10개 중 1~5번은 거의 매년 출제됩니다. 6~10번은 2~3년에 1회 정도. 1~5번을 완벽히 외우는 것이 최소 전략이고, 시간이 남으면 6~10번까지 확장하세요.
암기 팁 — 공식은 “구성 요소”로 외운다: “심박출량 = 심박수 × 1회 박출량”을 통째로 외우기보다, “심박출량을 결정하는 두 요소가 뭐지? → 심박수와 1회 박출량”이라고 질문-답변 형식으로 외우면 시험장에서 재구성이 쉽습니다. Fick 공식도 마찬가지: “VO₂를 결정하는 건? → 심박출량(혈액 얼마나 보내나)과 동정맥 산소차(얼마나 뽑아 쓰나)”.
5대 프레임워크의 연결 — “하나의 이야기”로 엮기
5개 프레임워크를 각각 외우면 기억 부담이 커집니다. 하나의 스토리로 엮으면 자연스럽게 연결됩니다.
한 문장으로 요약하면:
“인체가 운동을 시작하면 에너지(프레임워크 1)를 만들기 위해 각 기관이 급성 반응(프레임워크 2)을 보이고, 이 운동이 반복되면 만성 적응(프레임워크 3)이 일어난다. 각 기관의 구조는 이분법(프레임워크 4)으로 비교하면 명확히 구분되며, 이 모든 과정을 수치(프레임워크 5)로 정량화할 수 있다.”
이 한 문장이 운동생리학 전체의 골격입니다. 시험 문제가 나오면 “이 문제는 5대 프레임워크 중 어디에 해당하지?”라고 먼저 분류한 뒤, 해당 프레임워크의 표를 떠올리면 됩니다.
예시 문제: “장기간 유산소 트레이닝 후 안정 시 심박출량은 어떻게 변하는가?”
1단계 분류: “장기간” → 프레임워크 3 (급성 vs 만성)
2단계 확인: “안정 시 심박출량” → 공식은 HR × SV (프레임워크 5)
3단계 도출: 만성 적응 시 안정 시 HR은 감소, SV는 증가 → 심박출량은 거의 변하지 않음 (감소×증가 = 비슷)
정답: “안정 시 심박출량은 크게 변하지 않는다” (또는 “약간 증가한다”를 정답으로 치는 교재도 있음)
이렇게 프레임워크를 조합하면, 처음 보는 문제도 논리적으로 풀 수 있습니다.
영역별 학습 우선순위 매트릭스
출제 비중과 난이도를 교차 분석해 어디에 시간을 투자할지 매트릭스로 정리합니다.
난이도 낮음 (★~★★)
난이도 높음 (★★★~★★★★)
출제 비중 높음 (15%+)
🟢 순환계 (15%, ★★) 🟢 트레이닝 효과 (12%, ★★) → 황금 영역: 적은 노력, 높은 점수
🟡 에너지 대사 (19%, ★★★) 🟡 골격근 생리 (16%, ★★★) 🟡 호흡계 (13%, ★★★) → 핵심 영역: 시간 투자 필수
출제 비중 낮음 (10% 이하)
⚪ 환경과 운동 (7%, ★★) → 선택: 시간 남으면 훑기
🔴 내분비계 (10%, ★★★★) 🔴 신경 생리 (8%, ★★★★) → 과감히 버리기 또는 기본만
학습 순서 권장 로드맵
위 매트릭스를 바탕으로, 운동생리학을 처음 시작하는 비전공자에게 추천하는 학습 순서입니다.
Phase 1 — 황금 영역 먼저 (1~2주차)
순환계: 심박출량 공식, 혈류 재분배, 혈압 변화 → 일상 경험(운동하면 심장이 빨리 뛴다)과 연결되어 이해하기 쉬움
트레이닝 효과: 과부하·점진성·가역성·특이성 4대 원리 + 초과 회복 → 스포츠 상식과 겹치는 부분이 많아 진입 장벽 낮음
내분비계: 핵심 호르몬 5개(인슐린, 글루카곤, 아드레날린, 코르티솔, 성장호르몬)의 운동 시 변화 방향만 암기
신경 생리: 운동 단위 동원 순서(크기 원리)와 신경-근 접합부의 아세틸콜린 정도만
환경과 운동: 열사병 예방, 고지대 적응(EPO 증가) 등 상식적 내용만 훑기
Phase 3까지 하면 16~18문항 커버. 80점 이상 가능.
에너지 대사 — 가장 먼저 잡아야 할 핵심
ATP란 무엇인가
운동생리학의 모든 것은 ATP(아데노신 삼인산, Adenosine Triphosphate)에서 시작합니다. ATP는 인체의 에너지 화폐입니다. 근육이 수축하든, 심장이 뛰든, 뇌가 생각하든—모든 생리 활동에 ATP가 소비됩니다.
문제는 인체에 저장된 ATP 양이 극히 적다는 것입니다. 저장된 ATP만으로는 약 1~2초의 최대 운동밖에 못 합니다. 그래서 인체는 ATP를 끊임없이 재합성해야 하고, 그 재합성 방법이 앞서 본 3가지 에너지 시스템입니다.
3가지 에너지 시스템의 세부 기전
① ATP-PC 시스템 (인원질 시스템)
근육 세포에 저장된 크레아틴인산(PC, phosphocreatine)이 분해되면서 ADP에 인산기를 전달 → ATP 재합성
화학식: PC + ADP → ATP + Cr (크레아틴키나제 효소 촉매)
산소 불필요, 젖산 미생성 → 가장 깨끗하고 가장 빠른 시스템
단점: PC 저장량이 매우 적어 ~10초면 고갈
시험 포인트: “ATP-PC 시스템은 젖산을 생성하지 않는다” (O) / “산소가 필요하다” (X)
② 무산소성 해당과정 (젖산 시스템)
근육 세포질(사르코플라즘)에서 글리코겐(→포도당)이 분해되어 ATP를 생성
포도당 1분자 → 2 ATP + 2 피루브산
산소가 부족하면 피루브산 → 젖산(lactate)으로 전환
젖산 축적 → 수소이온(H⁺) 증가 → pH 저하 → 근피로
10초~2분 고강도 운동에서 주로 동원 (400m 달리기, 200m 수영)
시험 포인트: “해당과정의 최종 산물은 피루브산이다” (O) / “해당과정은 미토콘드리아에서 일어난다” (X, 세포질에서 일어남)
③ 유산소 시스템 (산화적 인산화)
미토콘드리아 내에서 산소를 이용해 ATP를 대량 생산
세 단계: 해당과정 → 크렙스 회로(TCA 회로, 시트르산 회로) → 전자전달계
포도당 1분자 → 약 36~38 ATP (무산소의 약 18~19배)
지방도 에너지원으로 사용 가능: 지방산의 β-산화 → 아세틸-CoA → 크렙스 회로
부산물: CO₂ + H₂O (호흡으로 배출)
2분 이상의 중·저강도 운동에서 주로 동원
시험 포인트: “유산소 시스템의 부산물은 이산화탄소와 물이다” (O) / “유산소 시스템은 ATP 생성 속도가 가장 빠르다” (X, 속도는 가장 느림)
에너지 시스템의 전환 — “스위치”가 아닌 “블렌딩”
시험에서 자주 나오는 함정 중 하나가 “에너지 시스템은 하나만 작동한다”는 오해입니다. 실제로는 세 시스템이 동시에 작동하되, 운동 강도와 시간에 따라 기여 비율이 달라집니다.
100m 스프린트: ATP-PC 90% + 해당 8% + 유산소 2%
800m 달리기: ATP-PC 10% + 해당 50% + 유산소 40%
마라톤: ATP-PC 0% + 해당 5% + 유산소 95%
시험 보기에 “100m 스프린트에서 ATP-PC 시스템만 사용된다”고 나오면 → 오답입니다. “주로 사용된다” 또는 “가장 큰 비율을 차지한다”가 정답 표현입니다.
젖산 역치(Lactate Threshold)와 OBLA
젖산 역치는 최근 2~3년 출제 빈도가 꾸준히 높은 토픽입니다.
젖산 역치(LT): 운동 강도를 점진적으로 높일 때, 혈중 젖산 농도가 급격히 증가하기 시작하는 지점
OBLA (Onset of Blood Lactate Accumulation): 혈중 젖산 4mmol/L에 해당하는 운동 강도 (실무적으로 젖산 역치와 유사하게 사용)
젖산 역치가 높을수록 → 더 높은 강도까지 유산소적으로 운동 가능 → 지구력 선수의 핵심 지표
트레이닝으로 젖산 역치를 높일 수 있음 (만성 적응, 프레임워크 3)
시험 포인트: “젖산 역치가 높은 선수는 더 오래 고강도 운동이 가능하다” (O) / “젖산은 피로만 유발하는 노폐물이다” (X — 젖산은 간에서 포도당으로 재전환되어 에너지원으로 재사용됨 = 코리 회로, Cori cycle)
순환계 — “황금 영역”의 핵심
심박출량의 이해
순환계에서 가장 중요한 개념은 심박출량(Cardiac Output, Q)입니다.
Q = HR × SV
HR (Heart Rate): 심박수, 분당 심장 박동 횟수
SV (Stroke Volume): 1회 박출량, 심장이 한 번 수축할 때 내보내는 혈액량
안정 시: HR 70 × SV 70mL = 약 5L/분
최대 운동 시: HR 190 × SV 130mL = 약 25L/분 (일반인 기준)
이 공식이 중요한 이유는, 순환계의 거의 모든 질문이 이 공식의 변형이기 때문입니다:
“운동 시 심박출량이 증가하는 이유는?” → HR↑ + SV↑
“훈련된 선수의 안정 시 심박출량이 비슷한 이유는?” → HR↓ + SV↑ = 비슷
“1회 박출량을 결정하는 요인은?” → 전부하(preload), 후부하(afterload), 심근 수축력(contractility)
혈류 재분배
운동을 시작하면 혈류가 활동 근육으로 집중됩니다. 안정 시 전체 혈류의 15~20%만 근육에 가던 것이, 최대 운동 시 80~85%까지 증가합니다.
이를 위해 비활동 기관(내장, 신장, 피부 등)의 혈류는 감소합니다. 이것이 혈류 재분배(blood flow redistribution)입니다.
시험 포인트:
“운동 시 근육 혈류가 증가하고 내장 혈류가 감소한다” (O)
“운동 시 피부 혈류는 항상 감소한다” (X — 저·중강도에서는 체온 조절을 위해 피부 혈류가 증가할 수 있음. 고강도에서만 감소)
“뇌와 심장의 혈류는 운동 중에도 유지된다” (O — 이 두 기관은 혈류 재분배에서 보호됨)
혈압 반응
운동 중 혈압 반응은 운동 유형에 따라 다릅니다. 이것도 빈출 함정입니다.
운동 유형
수축기 혈압
이완기 혈압
평균 혈압
유산소 운동 (동적)
↑↑ (비례 증가)
→ 또는 ↓ (소폭)
소폭 ↑
저항 운동 (정적)
↑↑↑ (급격 증가)
↑↑ (상당히 증가)
↑↑↑
핵심 차이: 유산소 운동에서는 이완기 혈압이 거의 변하지 않거나 소폭 하강하지만, 저항 운동(특히 무거운 무게의 등척성 수축)에서는 이완기 혈압도 상당히 증가합니다. 이것이 고혈압 환자에게 고중량 웨이트를 권하지 않는 이유이기도 합니다.
골격근 생리 — 두 번째 핵심 영역
근섬유 유형: 속근 vs 지근
이 비교는 운동생리학의 대표 비교쌍입니다. 5개년 기출에서 매년 1~2문항이 이 비교에서 나옵니다.
특성
Type I (지근, Slow-Twitch)
Type IIa (속근, Fast-Oxidative)
Type IIx (속근, Fast-Glycolytic)
수축 속도
느림
빠름
가장 빠름
피로 저항
높음
중간
낮음
미토콘드리아
많음
중간
적음
모세혈관 밀도
높음
중간
낮음
색상
적색 (미오글로빈 多)
적색/분홍
백색
주요 에너지원
지방 (유산소)
지방+탄수화물
글리코겐 (무산소)
대표 운동
마라톤, 장거리 수영
중거리 달리기
역도, 단거리
운동 단위 크기
작음
중간
큼
시험에서는 보통 Type I과 Type II(IIa와 IIx를 묶어서)의 2분류로 출제되지만, 간혹 3분류도 나옵니다. 핵심은 “I은 느리지만 오래 간다, II는 빠르지만 금방 지친다”입니다.
근수축 기전 — 활주 이론(Sliding Filament Theory)
근수축이 어떻게 일어나는지를 설명하는 이론입니다. 기전 전체를 서술하라는 문제는 드물지만, 핵심 키워드와 순서는 반복 출제됩니다.
근수축 순서 (간략):
운동 신경에서 아세틸콜린(ACh) 분비 → 신경-근 접합부 자극
근세포막(사르코렘마)에 활동전위 발생 → T-관 전도
근소포체(SR)에서 칼슘 이온(Ca²⁺) 방출
Ca²⁺이 트로포닌에 결합 → 트로포마이오신이 이동 → 액틴의 활성 부위 노출
마이오신 머리(cross-bridge)가 액틴에 결합 → 파워 스트로크 (근수축)
ATP가 마이오신에 결합 → 교차 결합 해제 → 이완
시험 빈출 키워드: 칼슘 이온, 트로포닌, 액틴-마이오신, 교차 결합(cross-bridge), ATP
함정 보기: “근수축에 ATP가 필요 없다” (X — ATP는 수축에도, 이완에도 필요합니다. 사후 경직(rigor mortis)은 ATP 고갈로 교차 결합이 해제되지 않아 발생)
수축 유형 비교
수축 유형
근육 길이 변화
관절 움직임
예시
등척성(Isometric)
변화 없음
없음
벽 밀기, 플랭크
등장성(Isotonic) — 구심성(Concentric)
짧아짐
있음
바벨 컬 올리기
등장성(Isotonic) — 원심성(Eccentric)
길어짐
있음
바벨 컬 내리기
등속성(Isokinetic)
변화 있음
있음 (일정 속도)
등속성 장비(사이벡스)
시험 포인트:
“원심성 수축에서 근육은 길어지면서 장력을 발휘한다” (O)
“원심성 수축이 구심성 수축보다 더 큰 힘을 발휘할 수 있다” (O — 원심성 수축의 최대 장력이 구심성보다 약 20~40% 큼)
“등척성 수축에서는 관절 움직임이 없다” (O)
“DOMS(지연성 근통증)은 주로 원심성 수축과 관련이 있다” (O)
호흡계 — 세 번째로 잡아야 할 영역
환기량과 가스 교환
호흡계에서 가장 먼저 외울 공식:
분당환기량(VE) = 호흡수(f) × 1회 호흡량(TV)
안정 시: 12회/분 × 0.5L = 약 6L/분
최대 운동 시: 50회/분 × 3L = 약 150L/분 (25배 증가!)
이 공식의 응용:
“운동 시 환기량이 증가하는 두 가지 방법은?” → 호흡수 증가 + 1회 호흡량 증가
“운동 초기에는 1회 호흡량 증가가 주도하고, 고강도에서는 호흡수 증가가 주도한다” (O)
VO₂max (최대산소섭취량)
VO₂max는 유산소 능력의 최대 지표로, 운동생리학에서 가장 중요한 체력 지표 중 하나입니다.
정의: 최대 운동 시 단위 시간당 소비할 수 있는 산소의 최대량
단위: mL/kg/min (체중 보정) 또는 L/min (절대값)
결정 요인: 심박출량(중심 요인) + 동정맥 산소차(말초 요인) → Fick 공식 연결
Fick 공식: VO₂ = Q × (a-v)O₂차
트레이닝으로 향상 가능 (보통 15~20%, 유전적 상한 있음)
시험 포인트:
“VO₂max를 결정하는 중심 요인은 심박출량이다” (O)
“VO₂max는 유전적 영향이 전혀 없다” (X — 약 40~50%는 유전적으로 결정)
“여성의 평균 VO₂max는 남성보다 낮다” (O — 체지방률, 혈중 헤모글로빈 차이)
산소 해리 곡선 (Oxygen Dissociation Curve)
난이도가 있지만 2~3년에 한 번 출제되는 토픽입니다. 보어 효과(Bohr Effect)와 함께 기억하세요.
산소 해리 곡선: 산소 분압(PO₂)에 따른 헤모글로빈의 산소 포화도를 나타내는 S자 곡선
우측 이동 (산소 해리 촉진): 체온↑, CO₂↑, pH↓(산성), 2,3-DPG↑ → 운동 시 근육에 산소를 더 잘 놓아줌
좌측 이동 (산소 결합 촉진): 반대 조건 → 폐에서 산소를 더 잘 결합
암기 팁: “운동하면 체온 오르고 CO₂ 늘고 산성 되니까 → 곡선이 오른쪽으로 간다 → 근육이 산소를 더 잘 받는다.” 운동 시 일어나는 변화(체온↑, CO₂↑, pH↓)를 먼저 떠올리면 우측 이동이 자동으로 연결됩니다.
트레이닝 효과 — 가장 점수 올리기 쉬운 영역
트레이닝의 4대 원리
스포츠 현장 경험이 있는 분이라면 직관적으로 이해되는 내용입니다.
원리
의미
예시
과부하(Overload)
현재 능력 이상의 자극을 줘야 적응이 일어남
10kg 들다가 12kg으로 증량
점진성(Progression)
부하를 단계적으로 증가시켜야 함
매주 5%씩 증량
특이성(Specificity)
훈련한 방식에 특이적으로 적응함
달리기 훈련이 수영 능력을 크게 향상시키진 않음
가역성(Reversibility)
훈련을 중단하면 적응이 소실됨
2주 쉬면 VO₂max 하락 시작
시험에서는 “과부하 원리의 정의”, “특이성 원리의 예시”, “가역성 원리에 해당하는 것은?” 같은 형태로 출제됩니다. 4개 원리의 이름-정의-예시를 1:1:1로 정확히 매칭하면 됩니다.
초과 회복(Supercompensation)
2024~2025년 기출에서 급부상한 토픽입니다.
운동 후 피로 → 회복 → 원래 수준을 넘어서는 능력 향상이 일시적으로 나타남
이 초과 회복 시점에 다시 운동하면 → 점진적 능력 향상
너무 빨리 다시 운동하면 → 회복 불충분 → 과훈련(overtraining)
너무 늦게 다시 운동하면 → 초과 회복이 사라짐 → 원점
시험 포인트: “최적의 트레이닝 타이밍은 초과 회복이 정점에 달했을 때이다” (O)
디트레이닝(Detraining)
가역성 원리의 구체적 현상입니다.
2~4주 훈련 중단: VO₂max 4~14% 감소, 심박출량 감소, 근력은 비교적 유지
유산소 능력이 근력보다 더 빨리 감소 — 시험에 자주 나오는 비교 포인트
완전한 침상 안정(bed rest) 시: 2~3주만에 심혈관 기능 급격히 저하
기출 OX 퀴즈 — 오늘 배운 것 점검하기
오늘 다룬 내용을 10문제로 점검합니다. 각 문항을 읽고 O(맞다) 또는 X(틀리다)를 판단한 뒤, 해설을 확인하세요.
Q1. ATP-PC 시스템은 산소를 필요로 하지 않으며, 부산물로 젖산이 생성된다.
정답: X — ATP-PC 시스템은 산소가 불필요한 것은 맞지만, 부산물은 크레아틴이지 젖산이 아닙니다. 젖산은 무산소성 해당과정의 부산물입니다.
Q2. 마라톤과 같은 장시간 운동에서는 유산소 시스템이 ATP 생성의 주된 경로이다.
정답: O — 2분 이상 지속되는 중·저강도 운동에서는 유산소 시스템(산화적 인산화)이 주된 ATP 공급 경로입니다.
Q3. 운동 시 이완기 혈압은 수축기 혈압과 마찬가지로 크게 증가한다.
정답: X — 유산소(동적) 운동 시 이완기 혈압은 변화가 거의 없거나 소폭 하강합니다. 다만 정적(등척성) 운동에서는 이완기 혈압도 상승할 수 있습니다.
Q4. 심박출량은 심박수와 1회 박출량의 곱으로 계산한다.
정답: O — Q = HR × SV. 운동생리학에서 가장 기본이 되는 공식입니다.
Q5. 장기간 유산소 트레이닝을 하면 최대 심박수가 증가한다.
정답: X — 최대 심박수는 주로 나이에 의해 결정되며, 트레이닝으로 유의미하게 증가하지 않습니다. 트레이닝으로 증가하는 것은 1회 박출량과 최대 심박출량입니다.
Q6. 지근 섬유(Type I)는 미토콘드리아가 적고 미오글로빈 함량이 낮아 백색을 띤다.
정답: X — 지근 섬유(Type I)는 미토콘드리아가 많고 미오글로빈 함량이 높아 적색을 띱니다. 백색을 띠는 것은 속근(Type IIx)입니다.
Q7. 근수축 시 칼슘 이온(Ca²⁺)은 트로포닌에 결합하여 액틴의 활성 부위를 노출시킨다.
정답: O — 활주 이론(Sliding Filament Theory)의 핵심 단계입니다. Ca²⁺→트로포닌 결합→트로포마이오신 이동→액틴 활성 부위 노출.
Q8. VO₂max를 결정하는 중심 요인은 동정맥 산소차이다.
정답: X — VO₂max의 중심 요인은 심박출량입니다. 동정맥 산소차는 말초 요인에 해당합니다. Fick 공식: VO₂ = Q × (a-v)O₂차.
Q9. 원심성 수축(Eccentric)은 근육이 길어지면서 장력을 발휘하며, DOMS(지연성 근통증)과 밀접한 관련이 있다.
정답: O — 원심성 수축은 근섬유에 미세 손상을 일으키기 쉬워, 운동 후 24~72시간 뒤 나타나는 DOMS의 주요 원인입니다.
Q10. 초과 회복(Supercompensation)이란 운동 후 회복 과정에서 체력이 운동 전 수준을 일시적으로 초과하는 현상이다.
정답: O — 정확한 정의입니다. 이 시점에 다음 훈련을 하면 점진적 체력 향상이 가능합니다.
채점 가이드:
8~10개 정답: 오늘 내용을 잘 소화했습니다. 18화(빈출 키워드)로 넘어가세요.
5~7개 정답: 프레임워크별 표를 한 번 더 정리하고, 틀린 문항의 해설을 다시 읽어 보세요.
4개 이하 정답: 에너지 시스템 3단계 표부터 다시 천천히 읽어 보세요. 한 번에 다 외우려 하지 말고, 프레임워크 1~2부터 잡아가면 됩니다.
비전공자를 위한 현실적 조언
“다 외워야 한다”는 공포에서 벗어나기
이 글을 읽으면서 “이걸 언제 다 외우지?”라는 생각이 들었을 수 있습니다. 하지만 오늘 알아야 할 핵심 메시지는 이겁니다:
“150개 키워드를 다 외우는 것이 아니라, 5개 프레임워크를 설치하는 것이 먼저다.”
프레임워크를 먼저 세우면:
새로운 키워드가 나와도 “이건 프레임워크 2(안정 시 vs 운동 시)에 해당하는군” 하고 분류할 수 있습니다.
시험장에서 처음 보는 보기가 나와도 “이 설명은 에너지 시스템의 논리와 모순되니까 오답이다” 하고 소거할 수 있습니다.
개별 키워드를 잊어도 “속도↔양↔시간은 역관계” 같은 패턴에서 재구성할 수 있습니다.
직장인의 운동생리학 공부법: 출퇴근 20분 전략
운동생리학은 표와 공식이 많아서, 짧은 시간에 반복 노출하는 것이 효과적입니다.
출근길 10분: 오늘의 표 1장을 사진으로 찍어 지하철에서 보기. 에너지 시스템 표 → 안정 vs 운동 표 → 급성 vs 만성 표 → 비교쌍 → 공식 순으로 5일 로테이션.
퇴근길 10분: 아침에 본 표를 가리고 떠올리기. “ATP-PC의 지속 시간은?”, “순환계 만성 적응에서 내려가는 건?” 식으로 자문자답.
주말 1시간: 기출 문제 10~15문항 풀기. 틀린 문항이 5대 프레임워크 중 어디에 해당하는지 분류하고, 해당 표를 다시 정리.
이 전략의 핵심은 “한 번에 많이”가 아니라 “매일 조금씩 반복”입니다. 운동생리학의 내용은 의외로 서로 연결되어 있어서, 반복할수록 이전에 외운 것이 새로운 것을 기억하게 도와주는 스캐폴딩(scaffolding) 효과가 나타납니다.
다른 과목과의 시너지
운동생리학은 다른 과목과 겹치는 내용이 생각보다 많습니다.
스포츠심리학: 각성 이론(심박수·아드레날린 등 생리적 각성 지표)과 운동생리학의 교감신경·카테콜아민이 직결됩니다. 12화에서 다룬 ‘역U 가설’의 생리적 기반이 바로 운동생리학에 있습니다.
스포츠윤리: 15화에서 다룬 도핑 금지 물질(EPO, 성장호르몬, 스테로이드)의 약리 기전이 운동생리학의 내분비계·순환계와 연결됩니다.
스포츠교육학: 6화에서 다룬 ‘운동 학습 단계(인지→연합→자율)’의 생리적 배경이 신경-근 적응으로 설명됩니다.
이미 앞에서 공부한 내용이 운동생리학의 기반이 된다는 것, 안심이 되시죠?
오늘의 핵심 체크리스트
17화를 마무리하며, 오늘 반드시 기억해야 할 것들을 체크리스트로 정리합니다.
☐ 운동생리학은 8개 하위 영역으로 나뉘며, 상위 5개 영역이 출제의 75%를 차지한다
☐ 학습 순서: 순환계 → 트레이닝 효과 → 에너지 대사 → 골격근 → 호흡계
☐ 5대 프레임워크: 에너지 3단계, 안정 vs 운동, 급성 vs 만성, A형 vs B형 비교, 수치·공식
☐ 에너지 시스템은 “속도↔양↔시간 역삼각형“으로 기억
☐ “운동하면 거의 다 올라간다” — 내려가는 건 이완기 혈압과 내장 혈류뿐
☐ 만성 적응의 핵심: 안정 시 심박수 DOWN, 최대 심박수 불변, 나머지 UP
☐ 비교쌍은 “한쪽만 확실히” 외우면 반대쪽은 자동 도출
☐ 공식 상위 5개(심박출량, 최대심박수, Fick, 환기량, 카르보넨)는 반드시 암기
☐ 150개 전부가 아닌 60~70개 핵심 키워드에 집중하면 12문항(합격선) 확보 가능
다음 화 미리보기
오늘 세운 5대 프레임워크의 뼈대 위에, 다음 18화에서는 각 프레임워크별 빈출 키워드를 구체적으로 채워 넣겠습니다. 에너지 대사의 크렙스 회로 핵심 단어 5개, 골격근의 활주 이론 순서, 순환계의 프랭크-스탈링 법칙, 호흡계의 보어 효과 세부사항까지—18화 한 편을 표로 정리해 두면, 시험 직전에 최종 리뷰 시트로 쓸 수 있을 겁니다.
암기량이 많다고 겁먹지 마세요. 패턴을 먼저 잡으면, 나머지는 빈칸 채우기입니다. 다음 화에서 그 빈칸을 함께 채워 보겠습니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: 생활스포츠지도사 2급 필기 합격 프로젝트 (총 30화 중 17화) ◀ 이전 16화 (다음 차수는 아직 게시되지 않았습니다)
본 글은 공개된 보도·자료만을 바탕으로 한 일반 독자용 분석이며, 어떤 기관의 내부 정보도 담고 있지 않습니다.
본 글은 「토큰북: 금융IT 20년차의 디지털 원화 관찰일지」 24일 연재 22회차입니다.
어제는 HTTP 402 상태코드를 되살린 x402 프로토콜이 ‘기계 간 결제’의 문법을 어떻게 정의하는지 살펴봤습니다. 오늘은 그 문법 위에 세계 최대 클라우드 사업자가 플랫폼을 올려놓은 사건 — AWS Bedrock AgentCore Payments(2026년 5월 7일 발표)를 해부합니다.
AWS가 에이전트 결제 인프라를 직접 만들었다
2026년 5월 7일, AWS는 연례 서밋에서 Amazon Bedrock AgentCore의 신규 모듈인 ‘Payments’를 공개했습니다(AWS 공식 블로그, 2026.5.7). 핵심은 단순합니다. Bedrock 위에서 돌아가는 AI 에이전트가 사람 개입 없이 외부 서비스에 결제를 실행할 수 있는 SDK·런타임·정산 레이어를 AWS가 직접 제공한다는 것입니다.
지원되는 결제 수단은 세 가지입니다:
USDC(서클) — 이더리움·솔라나 체인 위 스테이블코인 직접 전송
x402 호환 HTTP 결제 — 21화에서 다룬 프로토콜의 네이티브 구현
기존 카드·ACH 레일 — Stripe Connect 연동(폴백용)
금융IT 20년차 시각에서 눈에 띄는 건, AWS가 스테이블코인을 ‘1순위’로 올려놓았다는 점입니다. 기존 카드 레일은 ‘폴백’이라고 명시했습니다.
왜 빅테크 진입이 게임 체인저인가
x402가 ‘언어의 규칙’이었다면, AgentCore Payments는 ‘고속도로 위의 톨게이트 시스템’에 해당합니다. 차이를 비교해 보겠습니다.
구분
x402 프로토콜
AWS AgentCore Payments
성격
오픈 프로토콜(표준 규격)
관리형 플랫폼(Managed Service)
개발자 진입장벽
직접 구현 필요
SDK 3줄 호출
결제 수단
스테이블코인 전용
스테이블코인 + 카드 + ACH
정산·감사
체인 기록만 존재
CloudTrail 통합 감사 로그
규제 대응
개발자 자체 책임
AWS의 MSB 라이선스 범위 내 위임 가능
CB Insights(2026.5.8)는 이를 두고 “클라우드 3사 중 최초로 에이전트-네이티브 결제를 PaaS 수준에서 제공한 사례”라고 평가했습니다. 개발자가 결제 라이선스·지갑 인프라·AML 필터링을 직접 구축할 필요 없이, Bedrock 에이전트에 payments.authorize() 한 줄만 추가하면 됩니다.
구조 분석 — 에이전트가 돈을 쓰는 3단계
1단계: 의도 선언(Intent)
에이전트가 외부 API에 접근할 때, 상대 서버가 HTTP 402 + x402 헤더로 “결제 필요”를 응답합니다.
2단계: 승인 게이트(Authorization Gate)
AgentCore의 Policy Engine이 사전 정의된 예산 한도·화이트리스트·건당 상한을 확인합니다. 한도 초과 시 사람(운영자)에게 알림을 보내고 대기합니다. AWS는 이를 “Human-in-the-Loop Guardrail”이라 부릅니다.
첫째, 인프라 종속 문제. 국내 금융사 상당수가 AWS를 주 클라우드로 사용합니다(금융위원회 클라우드 이용 가이드라인, 2023). AgentCore Payments가 성숙하면, 한국 기업도 이 레일 위에서 에이전트 결제를 구현할 가능성이 높습니다. 다만 원화 스테이블코인이 없는 현 상태(8화 참조)에서는 USDC 달러 결제만 가능하다는 한계가 있습니다.
둘째, 은행의 역할 재정의. 5화에서 그린 ‘2030년 시나리오’ 중 ‘플랫폼에 매몰된 은행’ 시나리오가 현실화될 수 있는 경로입니다. AWS가 지갑·정산·감사까지 제공하면, 은행은 원화↔스테이블코인 온·오프램프(법정화폐 전환 관문)로 역할이 좁혀질 수 있습니다.
셋째, 규제 관할 충돌. AWS의 미국 MSB(Money Services Business) 라이선스가 한국 이용자의 에이전트 결제까지 커버하는지는 아직 회색 지대입니다. 디지털자산기본법(10화)과 전자금융거래법 개정안이 이 교차점을 어떻게 다룰지가 2026년 하반기 핵심 관전 포인트입니다.
일반 독자 체크포인트
AWS 계정이 있는 개발자라면 AgentCore Payments 샌드박스(테스트넷 USDC)를 지금 시도해볼 수 있습니다.
투자자 관점에서는 USDC 발행사 서클(Circle)의 파트너십 확대 추이가 간접 지표입니다.
원화 스테이블코인 없이는 한국 내 실거래 적용이 제한적이라는 점, 8화의 ‘3가지 쟁점’이 여전히 유효합니다.
빅테크가 에이전트 결제 인프라를 직접 깔기 시작했습니다. 프로토콜(x402) → 플랫폼(AWS) → 다음은 중앙은행 차례일 수 있습니다.
내일은 한국은행의 ‘한강 플랫폼’이 AI 에이전트 결제 실험에 어떻게 연결되는지를 다룹니다.
본 글은 공개된 보도·자료만을 바탕으로 한 일반 독자용 분석이며, 어떤 기관의 내부 정보도 담고 있지 않습니다. 본 글의 내용은 투자 권유나 자문이 아닙니다. 가상자산·토큰증권·금융상품 투자 결정은 반드시 본인 판단과 자격을 갖춘 전문가(투자권유대행인·세무사·변호사 등)와의 상담을 거쳐 진행하시기 바랍니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: 토큰북: 금융IT 20년차의 디지털 원화 관찰일지 (총 24화 중 22화) ◀ 이전 21화 (다음 차수는 아직 게시되지 않았습니다)
지난 8화에서 AI가 영원히 읽지 못하는 ‘행간’에 대해 이야기했습니다. 맥락을 읽는다는 것은 결국 명시적으로 주어지지 않은 것을 파악하는 능력이죠. 오늘은 그 연장선에서, 한 발 더 나아가 봅니다. 주어지지 않은 것을 파악하는 데서 그치지 않고, 아직 존재하지 않는 것을 만들어내는 행위 — 흔히 ‘창의’라 부르는 것 — 에서 AI와 사람의 역할은 어떻게 다른지 살펴보려 합니다.
먼저 고백 하나. 저도 처음엔 AI가 창의적인 일을 대체할 거라 생각했습니다. 코드를 짜주고, 문장을 다듬어주고, 디자인 시안까지 뽑아주는 걸 보면서요. 그런데 현장에서 2년 넘게 AI와 함께 일하면서 깨달은 게 있습니다. AI가 잘하는 ‘창의’와 사람만 할 수 있는 ‘창의’는 본질적으로 다른 종류의 행위라는 것. 수학에서 빌려온 두 단어로 그 차이를 정확하게 설명할 수 있습니다.
보간과 외삽: 수학에서 빌려온 가장 직관적인 비유
수학에서 보간(interpolation)이란, 이미 알려진 데이터 포인트들 사이의 빈 곳을 채우는 것입니다. 점 A와 점 B 사이에 부드러운 곡선을 그려 넣는 거죠. 반면 외삽(extrapolation)은 알려진 데이터의 범위 바깥으로 나아가는 것입니다. 점 A부터 점 E까지의 패턴을 보고, 아직 관측되지 않은 점 F, 점 G의 위치를 추정하는 겁니다.
여기서 핵심적인 차이가 있습니다. 보간은 이미 존재하는 것들 사이의 빈 공간을 다루고, 외삽은 아직 존재하지 않는 방향을 다룹니다. 보간이 틀릴 확률은 상대적으로 낮습니다. 양쪽 끝의 정보가 제약 조건으로 작동하니까요. 하지만 외삽은 본질적으로 불확실합니다. 과거의 패턴이 미래에도 유지된다는 보장이 없으니까요.
이 구분이 왜 중요하냐고요? AI가 하는 거의 모든 ‘창의적’ 작업이 사실은 보간이기 때문입니다.
AI가 하는 ‘창의’의 실체: 초고속 보간 기계
대규모 언어 모델이 글을 쓸 때 무엇을 하는지 생각해 봅시다. 학습 데이터에 존재하는 수십억 개의 텍스트 패턴을 기반으로, 주어진 맥락에서 가장 적절한 다음 단어를 예측합니다. ‘가장 적절한’이라는 표현 자체가 이미 보간의 성격을 드러냅니다. 기존에 존재하는 패턴들의 가중 평균, 혹은 그 패턴들이 형성하는 공간 안에서의 최적 위치를 찾는 것이죠.
이미지 생성 AI도 마찬가지입니다. “인상주의 화풍으로 그린 한국의 봄 풍경”이라는 프롬프트를 주면, AI는 ‘인상주의 화풍’이라는 스타일 벡터와 ‘한국의 봄 풍경’이라는 콘텐츠 벡터 사이의 어딘가에 새 이미지를 배치합니다. 결과물은 분명 이전에 존재하지 않았던 새로운 이미지입니다. 하지만 그것은 이미 알려진 스타일과 이미 알려진 대상의 조합 — 다시 말해 보간입니다.
보간이 나쁜 게 아닙니다
오해하지 마세요. 보간 능력이 대단하지 않다는 게 아닙니다. 오히려 엄청납니다. 인간이 수천 개의 참고 자료를 동시에 고려해서 그 사이의 최적점을 찾는 건 사실상 불가능합니다. AI는 그걸 초 단위로 해냅니다. 업무 현장에서 이 능력은 압도적인 생산성 향상을 가져옵니다.
제가 일하는 금융IT 분야에서도 마찬가지입니다. 기존 코드 패턴을 분석해서 새로운 모듈의 뼈대를 잡거나, 수백 개의 테스트 케이스 사이에서 빠진 경계 조건을 찾아내거나, 기존 API 문서들의 스타일을 학습해서 새 엔드포인트의 문서 초안을 만드는 것. 이 모든 게 보간이고, AI가 사람보다 빠르고 정확하게 해냅니다.
문제는 보간으로는 도달할 수 없는 지점이 있다는 것입니다.
외삽의 순간: 현장에서 목격한 세 가지 사례
사례 1: “이 문제를 문제로 인식하는 것”
몇 년 전, 저희 팀이 운영하던 챗봇이 있었습니다. 응답 정확도 94%, 사용자 만족도 조사 4.2/5.0. 숫자로 보면 아무 문제 없었습니다. AI에게 “이 챗봇의 개선점을 찾아줘”라고 물으면, 응답 속도를 0.3초 줄인다든지, 특정 카테고리의 정확도를 97%로 올린다든지 하는 — 기존 지표 안에서의 개선점, 즉 보간적 제안만 내놓았습니다.
그런데 팀의 한 주니어 개발자가 전혀 다른 질문을 던졌습니다. “혹시 우리 챗봇에 아예 질문을 안 하는 사용자가 있지 않을까요? 그 사람들은 왜 안 하는 걸까요?” 이 질문은 기존 데이터에 없는 것을 물었습니다. 응답한 사용자의 만족도가 아니라, 응답 자체를 포기한 사용자의 존재를 상상한 것이죠.
조사해 보니 실제로 로그인 후 챗봇 화면까지 왔다가 아무것도 입력하지 않고 이탈하는 비율이 35%에 달했습니다. 그들이 ‘질문을 안 한’ 게 아니라 ‘어떻게 질문해야 할지 몰랐던’ 것이었습니다. 이 발견은 UI 전면 개편으로 이어졌고, 실질적 사용률을 두 배 가까이 끌어올렸습니다.
AI는 이 발견을 할 수 없었습니다. 왜냐하면 “챗봇을 안 쓰는 사람”의 데이터는 챗봇 로그에 존재하지 않으니까요. 있는 데이터의 바깥을 상상하는 것, 그것이 외삽입니다.
사례 2: “유사한 것들을 연결해서 전혀 새로운 것을 만드는 순간”
금융 시스템 장애 대응을 하다 보면, 간혹 기존의 어떤 매뉴얼로도 설명이 안 되는 상황이 발생합니다. 한번은 특정 시간대에만 간헐적으로 발생하는 지연 현상이 있었는데, 모니터링 대시보드의 어떤 지표도 임계값을 넘지 않았습니다. AI 분석 도구에 로그를 넣어봐도 “이상 없음”만 반복했죠.
결국 문제를 찾아낸 건 한 시니어 엔지니어였는데, 그 사람이 한 것은 놀라웠습니다. 완전히 다른 맥락에서의 경험 — 예전에 취미로 했던 아마추어 무선 통신에서 겪었던 ‘페이딩(fading)’ 현상을 떠올린 겁니다. 특정 시간대에 전파가 약해지는 패턴과, 우리 시스템의 지연 패턴이 구조적으로 닮아 있다는 직감이었죠. 실제로 원인은 같은 시간대에 배치 작업을 돌리는 인접 시스템의 네트워크 버스트가 간섭을 일으키는 것이었습니다.
이 연결은 AI가 만들어낼 수 없었습니다. ‘아마추어 무선의 페이딩’과 ‘금융 시스템 네트워크 지연’을 같은 훈련 데이터 안에서 연결한 패턴이 존재하지 않았으니까요. 완전히 다른 도메인의 경험을 아날로지로 끌어오는 것 — 이것도 외삽입니다.
사례 3: “기존 규칙을 의도적으로 위반하는 판단”
시스템 설계에는 ‘정석’이 있습니다. 모범 사례(best practice)라고 부르는 것들이죠. AI는 이 정석들의 종합 백과사전 같습니다. “마이크로서비스 아키텍처에서 서비스 간 통신은 어떻게 설계해야 하나요?”라고 물으면, 수백 개의 참고 사례에서 추출한 최적의 패턴을 알려줍니다. 완벽한 보간이죠.
그런데 현실에서는 가끔 정석을 깨야 하는 순간이 옵니다. 한 프로젝트에서 모든 ‘올바른’ 설계 원칙이 가리키는 방향과 정반대로 가야 했던 적이 있습니다. 교과서적으로는 비동기 이벤트 기반이 맞았지만, 팀의 규모, 운영 역량, 비즈니스의 특수한 타이밍 요구사항을 종합하면 오히려 단순한 동기 호출이 나았습니다. AI에게 물으면 “이건 안티패턴입니다”라고 경고했지만, 결과적으로 3년간 단 한 번의 장애도 없이 운영됐습니다.
‘이 상황에서는 규칙을 깨는 게 옳다’는 판단은 보간의 결과가 아닙니다. 기존 데이터(=정석)가 가리키는 방향의 바깥으로 나가는 것이니까요. 이것이 외삽입니다.
왜 AI는 외삽을 못 하는가: 구조적 한계
“AI도 학습하면 외삽할 수 있지 않을까?” 이 질문을 많이 받습니다. 기술적으로 깊이 들어가면 복잡해지지만, 핵심만 짚어보겠습니다.
한계 1: 분포 내(in-distribution) vs 분포 외(out-of-distribution)
현재의 AI 모델은 학습 데이터의 분포(distribution) 안에서 동작할 때 놀라운 성능을 보입니다. 하지만 학습 시 본 적 없는 패턴 — 분포 바깥(out-of-distribution)의 입력이 들어오면 성능이 급격히 떨어집니다. 이건 버그가 아니라 구조적 특성입니다. 학습 데이터에서 추출한 패턴으로 예측하는 게 AI의 본질이니까요.
외삽은 정의상 분포 바깥을 다루는 행위입니다. 즉, AI의 가장 취약한 지점이 바로 외삽이 요구되는 지점과 겹칩니다.
한계 2: 목적 함수의 부재
AI는 “다음 토큰 예측” 또는 “주어진 목적 함수의 최적화”를 위해 훈련됩니다. 하지만 진정한 외삽 — 예를 들어 “지금까지 아무도 묻지 않았던 질문을 던지는 것” — 에는 사전에 정의된 목적 함수가 없습니다. 무엇이 ‘좋은 새로운 질문’인지를 학습 시점에 정의할 수 없으니까요.
사람은 다릅니다. 사람은 불편함, 호기심, 미적 감각, 윤리적 직관 같은 내적 신호를 통해 “여기에 뭔가 있을 것 같다”는 방향 감각을 갖습니다. 이 방향 감각이 목적 함수 없이도 외삽을 가능하게 합니다.
한계 3: 실패의 경험이 없다
인간의 외삽 능력은 상당 부분 실패의 경험에서 옵니다. 어떤 방향이 막다른 길인지, 어떤 가정이 깨지는지를 체험적으로 아는 것이죠. AI는 학습 데이터에 담긴 타인의 실패를 ‘읽을’ 수는 있지만, 스스로 어딘가에 부딪혀보고 방향을 튼 경험이 없습니다.
현장에서 “감(感)으로 안다”고 말하는 시니어들의 외삽 능력은, 수십 년간 축적된 실패 경험의 결정체입니다. 이건 텍스트로 전달되지 않는 종류의 지식이라, AI의 학습 데이터에 담기기가 구조적으로 어렵습니다.
현실적 협업 모델: 보간은 맡기고, 외삽에 집중하기
그렇다면 실무에서는 어떻게 해야 할까요? 제가 현장에서 2년간 실험하며 정착시킨 패턴을 공유합니다.
패턴 1: AI에게 ‘빈칸 채우기’를 시키고, 사람은 ‘빈칸의 위치’를 정한다
보고서를 쓸 때를 예로 들어보겠습니다. 예전에는 사람이 목차도 잡고, 각 섹션의 내용도 채웠습니다. 이제는 이렇게 합니다:
사람이 “이 보고서에서 말하고 싶은 건 X인데, 기존 보고서에서는 항상 빠지던 관점 Y를 이번엔 포함하고 싶다”고 방향을 정한다 (외삽)
AI가 그 방향에 맞는 목차를 제안하고, 각 섹션의 초안을 채운다 (보간)
사람이 초안을 읽으며 “이 부분은 뻔하다. 여기에 의외의 각도를 넣고 싶다”고 수정 방향을 잡는다 (외삽)
AI가 수정된 방향에 맞게 다시 채운다 (보간)
이 사이클을 돌리면, 사람 혼자 쓸 때보다 시간은 1/3로 줄면서도, AI 혼자 쓸 때보다 깊이와 독창성은 두 배 이상 높아집니다.
패턴 2: AI의 ‘보간 지도’를 읽고, 빈 영역을 식별한다
AI에게 특정 주제에 대해 “알려진 모든 접근법을 정리해줘”라고 시키면, 기존 지식의 지도를 빠르게 그려줍니다. 이 지도를 받아보면, 뭐가 없는지가 보입니다. “이 방향은 아무도 시도 안 했네” “이 두 분야의 교차점이 비어 있네” — 이런 발견이 외삽의 출발점이 됩니다.
역설적이게도, AI가 보간을 잘할수록 사람의 외삽이 수월해집니다. 지도가 촘촘할수록 빈 곳이 선명하게 드러나니까요.
패턴 3: ‘말이 안 되는’ 것을 일부러 시도하고, AI에게 정합성을 맞추게 한다
외삽은 종종 “말이 안 되는” 아이디어에서 시작됩니다. “고객 불만 처리 프로세스에 게임의 보상 시스템을 접목하면 어떨까?” 같은 것들이요. 이런 비약적 연결을 사람이 던지면, AI는 그것을 현실적으로 구현 가능한 형태로 다듬는 데 탁월합니다. 엉뚱한 아이디어의 외삽적 점프는 사람이, 그것을 실행 가능한 구체 방안으로 보간하는 것은 AI가 담당하는 겁니다.
보간 능력이 무한히 올라가면 외삽도 될까?
이 글을 읽으며 “AI 성능이 더 올라가면 결국 외삽도 하게 되지 않을까?”라고 생각하실 수 있습니다. 솔직히, 저도 확신은 없습니다. 하지만 현재까지의 관찰로 말씀드리자면:
보간의 정밀도를 아무리 높여도, 그것은 여전히 보간입니다. 고해상도 지도가 아무리 정밀해도, 지도에 그려지지 않은 대륙을 발견하는 것과는 다른 종류의 행위입니다. 패턴 인식의 정밀도를 극한까지 높이는 것과, 아직 존재하지 않는 패턴을 상상하는 것 사이에는 카테고리 자체가 다른 차이가 있어 보입니다.
물론 이것은 2026년 현재의 관찰입니다. 미래에 AI의 아키텍처가 근본적으로 바뀌면 달라질 수도 있겠죠. 하지만 그때까지, 그리고 어쩌면 그 이후에도, “어디로 가야 하는지를 정하는 것”은 사람의 몫으로 남을 가능성이 높습니다.
외삽 능력을 기르는 현실적 방법
“그래서 외삽을 잘하려면 어떻게 해야 하는데?” 실용적인 질문이죠. 20년간 IT 현장에서 관찰한, 외삽을 잘하는 사람들의 공통점을 정리해 봅니다.
1. 다른 분야를 ‘가볍게’ 경험한다
앞서 아마추어 무선 경험이 시스템 장애 진단에 도움이 된 사례를 말씀드렸죠. 외삽의 원료는 ‘현재 하는 일과 다른 도메인의 경험’입니다. 깊이 파지 않아도 됩니다. 다른 분야의 기본 개념과 사고 방식을 얕게라도 접하면, 그것이 아날로지의 재료가 됩니다.
2. ‘왜 안 되지?’보다 ‘왜 이게 당연하지?’를 묻는다
기존의 관행에 “왜?”를 붙이는 것만으로도 외삽의 문이 열립니다. “왜 로그인 화면이 항상 아이디/비밀번호 입력란이어야 하지?” “왜 장애 보고서는 항상 시간순이어야 하지?” 이런 질문들이 기존 패턴의 경계를 드러내고, 그 바깥을 상상하게 만듭니다.
3. 실패를 기록하고 복기한다
성공에서는 보간을 배우고, 실패에서는 외삽을 배웁니다. “이 방향은 안 되더라”는 경험이 쌓여야, 다음에 새로운 방향을 상상할 때 어디를 피해야 하는지 감이 옵니다. 실패 일지를 따로 쓰는 습관은 외삽 능력의 가장 확실한 투자입니다.
4. AI의 보간 결과를 ‘당연하지 않다’는 눈으로 본다
AI가 내놓은 결과물을 그대로 수용하면 사람도 보간에 갇힙니다. “AI가 이렇게 제안했는데, 정말 이 범위 안에서만 답이 있을까?”라는 의심이 외삽의 출발점입니다. AI의 답이 훌륭할수록, 그것이 커버하지 못하는 바깥을 의식적으로 찾는 습관이 중요해집니다.
금융IT 현장의 리얼: 보간과 외삽의 일상
제 일상을 예로 들어보면, 하루 업무의 시간 배분이 AI 도입 전후로 극적으로 바뀌었습니다.
AI 도입 전:
보간적 작업(기존 패턴대로 코드 작성, 문서 정리, 테스트 케이스 나열): 70%
외삽적 작업(새로운 설계 방향 탐색, 비즈니스 문제 재정의, 기술 실험): 20%
커뮤니케이션 및 기타: 10%
AI 도입 후:
보간적 작업: 30% (AI가 초안을 만들고 사람이 검토·보정)
외삽적 작업: 45% (확보된 시간으로 더 많이 탐색)
AI 협업 관리(프롬프트 설계, 결과 검증, 방향 재설정): 15%
커뮤니케이션 및 기타: 10%
이 변화가 가져온 체감 효과는 분명합니다. 예전에는 보간에 에너지를 쏟느라 외삽할 여유가 없었습니다. “이거 더 좋은 방법 없을까?”라는 생각이 들어도, 당장 눈앞의 코드를 완성해야 하니까 넘어갔죠. 이제는 AI가 보간을 빠르게 처리해주니까, 그 여유 시간에 “정말 이 방향이 맞나?”를 고민할 수 있게 됐습니다.
1화에서 “AI 도입했더니 더 바빠졌다”고 했던 거 기억하시죠? 그 바쁨의 상당 부분은 사실 외삽의 기회가 늘어난 것이었습니다. 보간에 쓰던 시간이 줄면서, 그동안 미뤄왔던 “근본적으로 다시 생각해봐야 하는 것들”이 수면 위로 올라온 거죠. 바빠진 게 아니라, 해야 할 일의 성격이 바뀐 겁니다.
흔한 오해: “AI도 창의적이잖아요”
이 글에 반론을 제기할 분들을 위해, 자주 듣는 오해 세 가지에 답해보겠습니다.
“AI가 만든 그림/글이 예술 대회에서 상을 탔는데요?”
그 작품들을 분석해 보면, 기존 스타일과 기법의 정교한 조합입니다. 심사위원이 놀란 건 ‘기계가 이 수준의 조합을 해냈다’는 기술적 놀라움이지, ‘이전에 없던 예술 운동을 창시했다’는 의미의 창의가 아닙니다. 인상주의를 처음 시작한 화가들의 외삽과, 인상주의 스타일로 새 그림을 그리는 보간은 다른 차원의 행위입니다.
“AI가 수학 증명을 새로 발견했다면서요?”
AI가 기존 증명 기법들의 조합으로 새 경로를 찾아낸 사례는 있습니다. 대단한 성과죠. 하지만 “증명할 가치가 있는 새로운 추측을 세우는 것”은 여전히 인간 수학자의 몫입니다. 리만 가설을 처음 ‘떠올린’ 것과, 리만 가설의 증명을 ‘시도하는’ 것은 다른 종류의 창의입니다.
“그냥 충분히 큰 모델이면 외삽도 하는 거 아닌가요?”
모델이 커지면 보간의 공간이 넓어집니다. 더 많은 패턴을 담을 수 있으니, 이전보다 더 먼 거리의 점들 사이도 보간할 수 있게 됩니다. 이것이 ‘외삽처럼 보이는’ 경우가 있습니다. 하지만 학습 데이터의 분포 자체를 벗어나는 것과, 분포 안에서 더 정교하게 움직이는 것은 여전히 구분됩니다. 크기의 양적 확장이 질적 전환을 가져오는지는 아직 증명되지 않았습니다.
이번 화의 핵심을 한 장의 그림으로
정리하면 이렇습니다:
보간(Interpolation): 알려진 점들 사이를 채우는 것. AI의 강점. 패턴 조합, 최적화, 기존 스타일 적용.
외삽(Extrapolation): 알려진 범위 바깥으로 나가는 것. 사람의 영역. 새 질문 제기, 규칙 위반, 도메인 간 도약.
최적의 협업: 사람이 외삽으로 방향을 정하고 → AI가 보간으로 실행을 채우고 → 사람이 결과를 보고 다시 외삽.
AI 시대에 사람의 가치는 “보간을 더 빨리 하는 것”에 있지 않습니다. 어차피 그건 AI를 이길 수 없으니까요. 사람의 가치는 “아직 아무도 보간하지 않은 방향을 가리키는 것”에 있습니다.
다음 화 예고
보간과 외삽 이야기를 하다 보니, 한 가지 더 파고 싶은 주제가 떠올랐습니다. 외삽을 하려면 — 새로운 방향으로 뛰려면 — 기존의 것들을 놓아야 할 때가 있습니다. AI는 기존 지식을 절대 잊지 않습니다. 학습된 모든 패턴을 영구히 보존하죠. 그런데 인간의 ‘잊음’과 ‘놓아버림’이 오히려 창의와 적응의 조건이 되는 상황이 있습니다. 다음 10화에서는 “잊는 능력 — AI의 완벽한 기억이 오히려 한계인 이유”에 대해 이야기하겠습니다.
이번 주 한 줄 노트: “AI가 채울 수 없는 빈칸은 없다. 하지만 어디에 빈칸을 뚫을지 결정하는 건, 아직 사람의 일이다.”
※ 본 글은 특정 기업·제품의 입장을 대변하지 않는 개인 견해입니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
📚 시리즈: 휴먼 인 더 루프(Human-in-the-Loop): AI 시대, 사람만 할 수 있는 일 (총 12화 중 9화) ◀ 이전 8화 (다음 차수는 아직 게시되지 않았습니다)