텍스트만 다루는 RAG, 실무에서는 절반밖에 못 쓴다
RAG(Retrieval-Augmented Generation)가 업무 현장에 빠르게 퍼지고 있습니다. 사내 문서에 질문하면 AI가 답변해 주는 시스템, 한 번쯤 써보셨거나 도입을 검토하고 계실 겁니다. 그런데 막상 실무 문서를 RAG에 넣어보면 기대와 다른 결과를 맞닥뜨리게 됩니다.
재무 보고서의 매출 추이 차트, 기술 문서의 아키텍처 다이어그램, 연구 논문의 실험 결과 표, 제품 카탈로그의 사진과 스펙 테이블. 우리가 실무에서 다루는 문서의 상당 부분은 텍스트가 아닌 시각적 요소에 핵심 정보가 담겨 있습니다. 기존 텍스트 기반 RAG는 이런 정보를 통째로 무시하거나 잘못 해석합니다.
“2024년 3분기 매출이 얼마야?”라고 물었을 때, 답이 본문 텍스트에는 없고 표에만 적혀 있다면? 기존 RAG는 “관련 정보를 찾을 수 없습니다”라고 답하거나 엉뚱한 숫자를 내놓습니다. 이 문제를 정면으로 해결하는 것이 바로 멀티모달 RAG입니다.
이 글에서는 이미지, 표, 차트, 수식이 포함된 복합 문서를 RAG 시스템에서 제대로 처리하는 방법을 실전 관점에서 다룹니다. 개념 이해부터 아키텍처 설계, 도구 선택, 구현 전략, 성능 최적화까지 한 흐름으로 정리했습니다.

멀티모달 RAG란 무엇이고, 왜 필요한가
기존 RAG의 구조적 한계
일반적인 RAG 파이프라인은 크게 세 단계로 이루어집니다. 문서를 텍스트로 변환해서 청크로 나누고, 각 청크를 벡터 임베딩으로 변환해 벡터 데이터베이스에 저장한 뒤, 사용자 질문과 유사한 청크를 검색해서 LLM에 컨텍스트로 전달하는 흐름입니다.
이 과정에서 문제가 되는 지점은 첫 번째 단계, 즉 문서를 텍스트로 변환하는 과정입니다. PDF에서 텍스트만 추출하면 표의 행·열 구조가 무너지고, 차트의 데이터 포인트는 아예 사라지며, 이미지 속 정보는 존재하지 않는 것처럼 취급됩니다. 문서의 레이아웃 정보—어떤 텍스트가 어떤 이미지를 설명하는지, 표의 헤더와 셀이 어떻게 대응하는지—도 함께 날아갑니다.
실제로 기업 내부 문서의 정보 분포를 조사한 연구들에 따르면, 비즈니스 문서에서 핵심 데이터의 40~60%가 표, 차트, 다이어그램 같은 비텍스트 요소에 담겨 있습니다. 텍스트만 다루는 RAG는 문서 정보의 절반을 버리고 시작하는 셈입니다.
멀티모달 RAG의 정의
멀티모달 RAG는 텍스트뿐 아니라 이미지, 표, 차트, 수식, 레이아웃 정보까지 함께 인덱싱하고 검색에 활용하는 확장된 RAG 시스템입니다. 단순히 이미지를 텍스트로 설명하는 수준을 넘어, 시각 정보 자체를 벡터 공간에 매핑하거나 구조화된 데이터로 변환해서 정확한 검색과 답변을 가능하게 합니다.
핵심 차이를 정리하면 다음과 같습니다.
- 입력 처리: 텍스트 추출에 그치지 않고, 문서의 시각적 구조를 보존하며 각 요소(텍스트 블록, 표, 이미지, 캡션)를 개별적으로 파싱합니다.
- 임베딩: 텍스트 임베딩만 쓰는 대신, 비전-언어 모델(VLM)이나 멀티모달 임베딩 모델을 활용해 이미지와 텍스트를 동일한 벡터 공간에 배치합니다.
- 검색: 텍스트 질문으로 이미지를 찾거나, 이미지로 관련 텍스트를 찾는 크로스 모달 검색이 가능합니다.
- 생성: LLM에 텍스트 컨텍스트와 함께 이미지나 표 데이터를 전달해, 시각 정보를 반영한 답변을 생성합니다.
실무에서 체감하는 차이
멀티모달 RAG가 만드는 실질적인 변화를 몇 가지 시나리오로 살펴보겠습니다.
첫째, 재무 보고서 분석입니다. “지난 분기 대비 영업이익률 변화를 설명해 줘”라고 물으면, 기존 RAG는 본문에 명시된 숫자만 찾습니다. 멀티모달 RAG는 보고서의 손익계산서 표와 추이 차트까지 분석해서, 표에서 정확한 수치를 뽑고 차트의 트렌드를 함께 설명합니다.
둘째, 기술 문서 검색입니다. “이 시스템의 데이터 흐름을 알려 줘”라는 질문에 아키텍처 다이어그램을 찾아내고, 다이어그램의 구성 요소와 연결 관계를 해석해서 답변에 포함시킵니다.
셋째, 제품 카탈로그나 매뉴얼입니다. “이 부품의 규격이 뭐야?”라고 물으면 스펙 테이블에서 해당 행을 정확히 찾아 답합니다. 제품 사진과 함께 “이 사진에 나온 부품의 호환 모델을 찾아 줘” 같은 복합 질의도 처리할 수 있습니다.
멀티모달 RAG의 핵심 아키텍처
멀티모달 RAG 시스템을 구축하려면 기존 RAG 파이프라인의 각 단계를 확장해야 합니다. 크게 네 가지 계층으로 나눠서 설계하는 것이 실무적으로 효과적입니다.
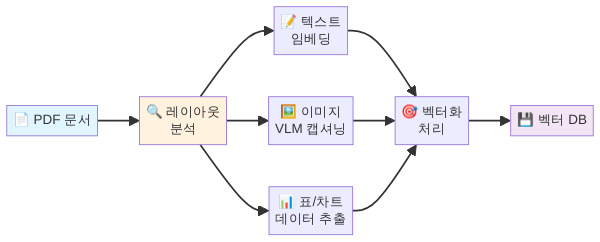
1계층: 문서 파싱과 요소 분리
가장 중요하면서도 까다로운 단계입니다. 원본 문서(PDF, DOCX, PPTX, 스캔 이미지 등)에서 텍스트, 표, 이미지, 캡션, 제목 계층 등의 요소를 구조적으로 분리해야 합니다.
이 단계에서 쓸 수 있는 접근법은 크게 세 가지입니다.
규칙 기반 파싱은 PDF의 내부 구조(폰트 크기, 좌표, 선 정보)를 읽어서 요소를 분류하는 방식입니다. pdfplumber, tabula-py 같은 라이브러리가 여기에 해당합니다. 디지털 네이티브 PDF(텍스트가 직접 포함된 PDF)에서는 빠르고 정확하지만, 복잡한 레이아웃이나 스캔 문서에서는 한계가 뚜렷합니다.
레이아웃 분석 모델은 문서 이미지를 입력으로 받아 각 영역의 종류(제목, 본문, 표, 그림, 캡션 등)를 딥러닝으로 판별합니다. Unstructured, Docling, Layout Parser 같은 도구가 이 범주에 속합니다. 2025년 이후 이 분야의 모델 정확도가 크게 올라서, 현재 실무에서 가장 널리 쓰이는 접근법입니다.
비전-언어 모델(VLM) 직접 활용은 문서 페이지 이미지를 통째로 멀티모달 LLM에 넣어 구조를 파악하는 방법입니다. 별도의 파싱 파이프라인 없이 모델이 직접 “이 페이지에서 표를 찾아 마크다운으로 변환해 줘”라는 식으로 처리합니다. 정확도는 높지만 비용과 속도 면에서 대량 문서 처리에는 부담이 됩니다.
실무에서는 레이아웃 분석 모델을 기본으로 쓰고, 복잡한 표나 차트는 VLM으로 보완하는 하이브리드 접근이 가장 효율적입니다.
2계층: 요소별 임베딩 생성
분리된 요소들을 벡터 공간에 매핑하는 단계입니다. 요소의 유형에 따라 서로 다른 임베딩 전략을 적용합니다.
텍스트 블록은 기존과 동일하게 텍스트 임베딩 모델(OpenAI text-embedding-3, Cohere embed-v4, 오픈소스 bge-m3 등)로 처리합니다.
표는 두 가지 전략 중 하나를 선택합니다. 하나는 표를 마크다운이나 HTML로 변환한 뒤 텍스트 임베딩을 적용하는 방식이고, 다른 하나는 표의 이미지 자체를 멀티모달 임베딩 모델로 처리하는 방식입니다. 전자가 검색 정확도가 더 높은 경우가 많아 일반적으로 권장됩니다. 표를 마크다운으로 변환할 때는 원본의 행·열 구조를 최대한 보존하는 것이 핵심입니다.
이미지는 멀티모달 임베딩 모델을 사용합니다. CLIP 계열, SigLIP, 혹은 최신 비전-언어 임베딩 모델이 텍스트와 이미지를 동일한 벡터 공간에 배치해, 텍스트 질문으로 관련 이미지를 검색하는 것이 가능합니다. 혹은 이미지를 VLM으로 설명(캡셔닝)한 뒤 그 설명 텍스트를 임베딩하는 방법도 있습니다.
차트는 조금 특별합니다. 차트 이미지를 그대로 임베딩하는 것보다, 차트에서 데이터를 추출(deplot, chart-to-table)한 뒤 테이블 형태로 변환해서 인덱싱하는 편이 수치 질문에 대한 답변 정확도가 훨씬 높습니다. 최근에는 ChartInstruct 같은 차트 전용 이해 모델도 등장해서 선택지가 넓어졌습니다.
3계층: 하이브리드 검색
멀티모달 RAG에서 검색 단계는 단순 벡터 유사도 검색만으로는 부족합니다. 다양한 유형의 요소를 효과적으로 찾으려면 하이브리드 검색 전략이 필수입니다.
구체적으로는 다음 세 가지를 조합합니다.
- 밀집 벡터 검색(Dense Retrieval): 시맨틱 유사도 기반. 의미적으로 관련된 텍스트와 이미지를 찾습니다.
- 희소 벡터 검색(Sparse Retrieval): BM25 같은 키워드 매칭. 정확한 용어·수치·코드명을 찾을 때 강점입니다. 표에서 특정 제품명이나 숫자를 검색할 때 특히 유용합니다.
- 메타데이터 필터링: 문서 이름, 페이지 번호, 요소 유형(텍스트/표/이미지), 날짜 등의 메타데이터로 검색 범위를 좁힙니다. “2024년 연간 보고서의 표에서 찾아 줘”라는 질의를 처리하려면 이 필터가 있어야 합니다.
세 가지 검색 결과를 RRF(Reciprocal Rank Fusion)나 가중 합산으로 통합해 최종 검색 결과를 만듭니다. Weaviate, Qdrant, Milvus 같은 최신 벡터 데이터베이스들은 이런 하이브리드 검색을 네이티브로 지원합니다.
4계층: 멀티모달 컨텍스트 생성
검색된 요소들을 LLM에 전달해 최종 답변을 생성하는 단계입니다. 여기서 핵심은 텍스트와 시각 정보를 어떻게 조합해서 프롬프트에 담을 것인가입니다.
멀티모달 LLM(GPT-4o, Claude Sonnet/Opus, Gemini 등)을 사용한다면 검색된 이미지를 그대로 프롬프트에 포함시킬 수 있습니다. 표는 마크다운 형태로, 차트는 이미지와 추출된 데이터 테이블을 함께 넣는 것이 답변 품질을 높입니다.
텍스트 전용 LLM을 써야 하는 상황이라면, 이미지와 차트를 VLM으로 먼저 설명 텍스트로 변환한 뒤 프롬프트에 포함합니다. 정확도는 조금 떨어지지만, 비용이 낮고 오픈소스 LLM과 결합하기 좋습니다.
어느 방식이든 프롬프트에는 각 컨텍스트의 출처 정보(문서명, 페이지, 요소 유형)를 명시하는 것이 중요합니다. LLM이 답변에서 출처를 인용할 수 있고, 사용자가 원본을 확인할 수 있어야 실무에서 신뢰를 얻습니다.
실전 구현: 표와 이미지를 제대로 처리하는 전략
아키텍처를 이해했으니, 가장 자주 마주치는 두 요소—표와 이미지—를 실전에서 어떻게 처리하는지 구체적으로 살펴보겠습니다.
표(Table) 처리 전략
표는 멀티모달 RAG에서 가장 중요하면서도 가장 까다로운 요소입니다. 비즈니스 문서에서 정량적 정보의 대부분은 표에 담겨 있기 때문입니다.
추출 단계에서는 표의 구조를 정확히 보존하는 것이 최우선입니다. 셀 병합, 다단 헤더, 중첩 표 같은 복잡한 구조를 처리해야 합니다. Docling은 TableFormer 모델을 내장해서 복잡한 표 구조도 비교적 정확하게 추출합니다. Unstructured는 다양한 전략(hi_res, fast, ocr_only)을 제공하는데, 표가 많은 문서에서는 hi_res 전략이 필수입니다.
변환 단계에서 표를 어떤 형태로 저장할지 결정합니다. 실험적으로 가장 좋은 결과를 보이는 형식은 마크다운 테이블입니다. HTML 테이블도 좋지만, 토큰 소비가 마크다운보다 많습니다. CSV는 구조가 단순한 표에서는 괜찮지만, 복잡한 헤더나 병합 셀을 표현하기 어렵습니다.
인덱싱 단계에서 중요한 팁이 있습니다. 표를 통째로 하나의 청크로 임베딩하면 검색 정확도가 떨어집니다. 대신 두 가지 보완 전략을 씁니다.
- 표 요약 생성: 표 전체를 LLM에 넣어 “이 표는 무엇에 관한 것이고, 어떤 데이터를 담고 있는가”에 대한 요약을 생성합니다. 이 요약을 임베딩해서 검색에 사용하고, 실제 LLM 컨텍스트에는 원본 표를 전달합니다. 이 패턴을 요약 임베딩 + 원본 전달 전략이라고 부릅니다.
- 행 단위 분할: 큰 표는 헤더를 각 청크에 반복 포함하면서 여러 행 그룹으로 분할합니다. 예를 들어 100행짜리 표를 20행씩 5개 청크로 나누되, 각 청크에 컬럼 헤더를 항상 포함합니다.
두 전략을 결합하면, 사용자가 “삼성전자의 2024년 매출”을 물었을 때 표 요약으로 관련 표를 찾고, 행 단위 청크에서 정확한 데이터 행을 집어낼 수 있습니다.
이미지 처리 전략
문서 속 이미지는 크게 세 종류로 나뉘고, 각각 다른 처리가 필요합니다.
정보성 이미지(다이어그램, 플로우차트, 아키텍처도)는 이미지 자체에 구조적 정보가 담겨 있습니다. 이런 이미지는 VLM으로 상세한 설명을 생성해야 합니다. 단순히 “시스템 아키텍처 다이어그램”이라고 요약하면 검색에서 잡히지 않습니다. “사용자 요청이 API Gateway를 거쳐 인증 서비스에 도달하고, 인증 후 주문 서비스와 결제 서비스로 분기되는 마이크로서비스 아키텍처를 나타내는 다이어그램”처럼 구성 요소와 관계를 명시해야 합니다.
데이터 시각화(차트, 그래프)는 앞서 언급한 대로 데이터 추출이 핵심입니다. 파이 차트에서는 각 항목의 비율을, 선 그래프에서는 시계열 데이터를, 막대 차트에서는 카테고리별 값을 추출해서 테이블로 변환합니다. 이미지와 추출 데이터를 함께 저장해 두면 시각적 트렌드 질문과 정확한 수치 질문 모두에 대응할 수 있습니다.
장식적 이미지(로고, 배경, 구분선)는 정보 가치가 낮으므로 필터링합니다. 이미지 크기(너무 작거나 극단적인 종횡비), 위치(페이지 상단/하단 고정), 반복 패턴 등을 기준으로 자동 분류할 수 있습니다.
이미지 임베딩에는 두 가지 선택지가 있습니다. CLIP/SigLIP 계열 모델로 이미지를 직접 임베딩하거나, VLM이 생성한 설명 텍스트를 텍스트 임베딩 모델로 처리하는 방식입니다. 전자는 시각적 유사성 검색에 강하고, 후자는 의미적 검색에 강합니다. 실무에서는 두 임베딩을 모두 생성해서 하이브리드 검색에 활용하는 것이 가장 안정적입니다.
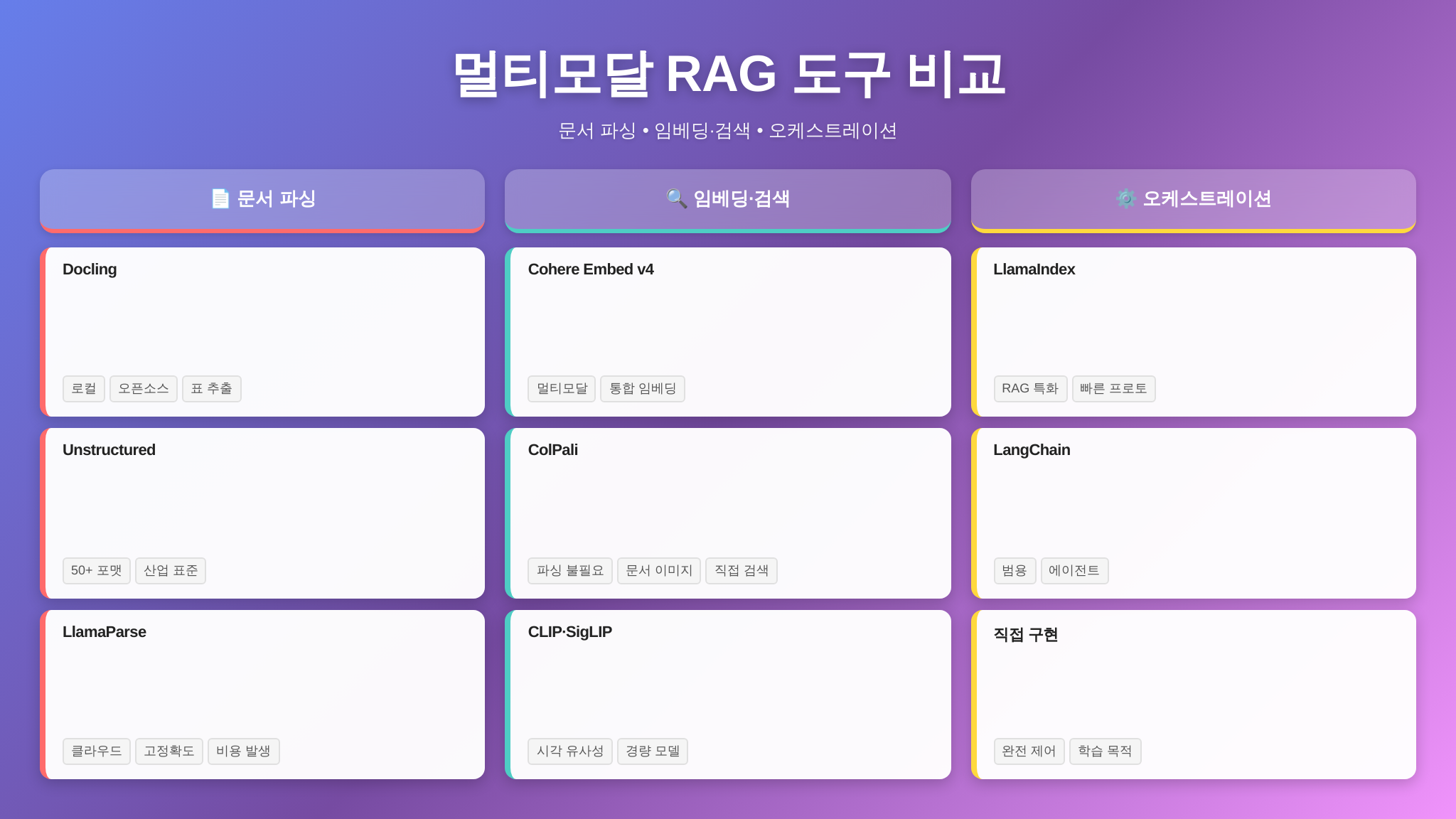
도구와 프레임워크 선택 가이드
멀티모달 RAG를 구현할 때 모든 것을 밑바닥부터 만들 필요는 없습니다. 2026년 현재, 파이프라인의 각 단계를 담당하는 성숙한 도구들이 갖춰져 있습니다. 목적과 환경에 맞는 도구를 고르는 것이 첫 번째 의사결정입니다.
문서 파싱 도구
Docling은 IBM이 오픈소스로 공개한 문서 변환 라이브러리입니다. PDF, DOCX, PPTX, 이미지, HTML 등 다양한 포맷을 지원하며, 내장된 TableFormer 모델이 표 추출에 특히 강합니다. 설치가 간단하고(pip install docling) 로컬에서 돌릴 수 있어서, 외부 API 없이 파싱해야 하는 환경에 적합합니다. 출력을 마크다운이나 JSON 구조로 변환하는 기능이 내장되어 있어 후속 파이프라인과의 연결도 편리합니다.
Unstructured는 멀티모달 RAG 파싱 분야의 사실상 표준 도구입니다. 50여 가지 파일 포맷을 지원하고, 문서의 각 요소를 Title, NarrativeText, Table, Image, ListItem 등의 타입으로 분류합니다. hi_res 파싱 전략에서는 내부적으로 레이아웃 분석 모델(YOLOX 기반)을 사용해 시각적 요소를 정확하게 잡아냅니다. SaaS API와 오픈소스 라이브러리 모두 제공하므로 환경에 따라 선택할 수 있습니다.
LlamaParse는 LlamaIndex 팀이 만든 클라우드 기반 문서 파서입니다. 복잡한 PDF(다단 레이아웃, 교차 참조, 학술 논문)에서 높은 정확도를 보입니다. 내부적으로 멀티모달 LLM을 활용하기 때문에 파싱 품질이 우수하지만, API 호출 비용이 발생하고 문서를 외부 서버로 전송해야 해서 보안 민감 문서에는 적합하지 않을 수 있습니다.
임베딩과 검색
Cohere Embed v4는 2026년 현재 멀티모달 임베딩의 강력한 선택지입니다. 텍스트, 이미지, 혼합 콘텐츠를 하나의 모델로 임베딩할 수 있어 파이프라인이 단순해집니다. 문서의 이미지와 텍스트를 동일한 벡터 공간에 넣을 수 있다는 것이 가장 큰 장점입니다.
ColPali/ColQwen은 문서 이미지를 통째로 임베딩하는 접근법으로, 파싱 단계를 아예 건너뛰는 “파싱 없는 RAG”를 가능하게 합니다. 문서 페이지 이미지를 패치 단위로 임베딩하고, 질문과 매칭해서 관련 페이지를 찾습니다. 파싱의 복잡성을 제거하는 대신, 찾아낸 페이지에서 정확한 답변을 뽑으려면 결국 멀티모달 LLM이 필요합니다.
벡터 데이터베이스는 Weaviate, Qdrant, Milvus 중에서 고르면 대부분의 요구를 충족합니다. 세 도구 모두 하이브리드 검색(밀집 + 희소), 멀티벡터 저장, 메타데이터 필터링을 지원합니다. 로컬 개발에는 Chroma나 LanceDB처럼 임베디드 방식으로 동작하는 가벼운 옵션도 좋습니다.
오케스트레이션 프레임워크
LangChain과 LlamaIndex는 멀티모달 RAG 파이프라인을 구성하는 양대 프레임워크입니다. 두 프레임워크 모두 멀티모달 문서 로더, 멀티모달 임베딩, 멀티모달 LLM 통합을 지원합니다.
LlamaIndex는 RAG에 특화된 추상화가 잘 돼 있어서, 멀티모달 RAG 파이프라인을 빠르게 프로토타이핑하기 좋습니다. MultiModalVectorStoreIndex 같은 전용 인덱스가 이미지와 텍스트를 함께 관리합니다.
LangChain은 더 범용적이고 유연해서, 커스텀 파이프라인이 필요하거나 에이전트 기반 RAG로 확장할 계획이라면 적합합니다. LCEL(LangChain Expression Language)로 멀티모달 체인을 선언적으로 구성할 수 있습니다.
소규모 프로젝트나 학습 목적이라면 프레임워크 없이 직접 구현하는 것도 고려해 보세요. 파싱 도구 + 임베딩 API + 벡터 DB + LLM API를 직접 연결하면 전체 흐름을 깊이 이해할 수 있고, 프레임워크의 추상화가 오히려 디버깅을 어렵게 만드는 상황을 피할 수 있습니다.
성능 최적화와 실무 팁
멀티모달 RAG 시스템을 만드는 것과 실무에서 쓸 만한 품질로 끌어올리는 것은 다른 문제입니다. 프로토타입에서 프로덕션으로 가는 과정에서 주의할 점들을 정리합니다.
청킹 전략의 재설계
멀티모달 문서에서 청킹은 단순히 텍스트를 일정 길이로 자르는 것 이상입니다. 요소 인식 청킹(element-aware chunking)이 필요합니다.
기본 원칙은 간단합니다. 표, 이미지, 코드 블록은 절대로 중간에서 자르지 않는다. 이 요소들은 하나의 단위로 유지하고, 주변 텍스트(제목, 캡션, 앞뒤 설명 문단)를 함께 묶어서 하나의 청크로 만듭니다.
Unstructured의 chunk_by_title 옵션이 이 개념을 잘 구현합니다. 문서의 제목 계층(h1, h2, h3)을 경계로 청크를 나누되, 같은 섹션 안의 표와 이미지는 해당 섹션의 텍스트와 함께 묶습니다.
청크 하나에 너무 많은 정보가 들어가면 검색 정확도가 떨어지고, 너무 적으면 맥락이 부족해집니다. 멀티모달 문서에서는 1000~2000 토큰 범위가 경험적으로 좋은 출발점입니다. 다만 큰 표는 이 범위를 초과할 수 있으므로, 표 전용 청킹 규칙(앞서 설명한 행 단위 분할)을 별도로 적용합니다.
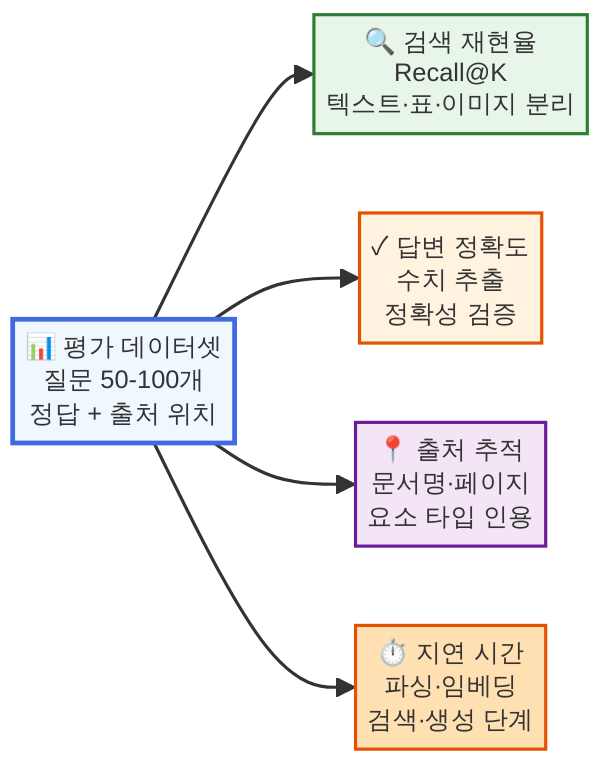
검색 품질 평가
멀티모달 RAG의 성능을 측정하려면 텍스트 RAG보다 더 체계적인 평가가 필요합니다. 다음 지표를 모니터링하세요.
- 검색 재현율(Recall@K): 관련 문서 중 상위 K개에 포함된 비율. 표와 이미지 요소를 각각 따로 측정하는 것이 중요합니다. 텍스트는 잘 찾지만 표를 못 찾는 시스템이라면, 표 임베딩 전략을 개선해야 합니다.
- 답변 정확도(Correctness): 특히 수치 데이터를 다루는 질문에서 정확한 숫자를 내놓는지 확인합니다. 표에서 “1,234,567”을 “약 120만”으로 바꾸는 것은 비즈니스 맥락에서 받아들일 수 없습니다.
- 출처 추적 가능성(Traceability): 답변의 근거가 된 문서, 페이지, 요소(표/이미지/텍스트)를 사용자가 확인할 수 있는지. 실무에서 신뢰 확보에 필수적입니다.
- 지연 시간(Latency): 이미지 처리와 멀티모달 LLM 호출이 추가되면 응답 시간이 길어집니다. 사용자 체감에 영향을 주는 수준인지 모니터링합니다.
평가 데이터셋은 실제 업무 문서에서 만드는 것이 가장 효과적입니다. 각 부서에서 자주 묻는 질문 50~100개를 모으고, 정답과 정답이 위치한 문서 요소를 표기해 둡니다. 이 데이터셋을 파이프라인 변경 시마다 자동으로 돌려서 회귀를 잡습니다.
비용과 속도 최적화
멀티모달 RAG는 텍스트 전용 RAG보다 비용이 높습니다. 이미지 처리, VLM 호출, 멀티모달 임베딩 등 각 단계에서 추가 비용이 발생합니다. 다음 전략으로 비용을 관리하세요.
파싱 결과 캐싱: 같은 문서를 반복 파싱하지 않도록, 파싱 결과를 파일 해시 기반으로 캐싱합니다. 문서가 업데이트되지 않았다면 이전 파싱 결과를 재사용합니다.
단계적 처리: 모든 이미지에 VLM 캡셔닝을 적용하면 비용이 급증합니다. 먼저 이미지를 분류해서(정보성/장식적) 정보 가치가 있는 이미지만 VLM으로 처리합니다. 단순 로고나 배경은 메타데이터만 기록하고 넘어갑니다.
로컬 모델 활용: 파싱과 임베딩 단계에서 오픈소스 모델을 로컬에 배포하면 API 호출 비용을 크게 줄일 수 있습니다. Docling은 완전히 로컬에서 동작하고, ColPali 계열 모델도 GPU 하나면 충분히 추론할 수 있습니다. 최종 답변 생성 단계에서만 상용 LLM을 쓰는 하이브리드 구성이 비용 효율적입니다.
비동기 인덱싱: 문서 업로드와 인덱싱을 분리해서, 사용자는 문서를 올린 즉시 기존 인덱스로 질의할 수 있게 하고, 새 문서의 멀티모달 파싱과 인덱싱은 백그라운드에서 진행합니다.
자주 겪는 문제와 해결책
실무에서 멀티모달 RAG를 운영하다 보면 반복적으로 마주치는 문제들이 있습니다.
표의 행·열이 뒤섞이는 문제는 파서의 표 추출 정확도가 원인입니다. 같은 문서를 두세 가지 파서로 처리해 보고 결과를 비교하세요. 특히 셀 병합이 있는 표는 Docling의 TableFormer가 다른 도구보다 나은 경우가 많습니다. 그래도 안 되면 해당 표를 이미지로 캡처해서 VLM에 직접 마크다운 변환을 요청하는 폴백 전략을 두세요.
차트에서 수치를 잘못 읽는 문제는 차트 데이터 추출 과정의 오차입니다. DePlot이나 ChartInstruct의 출력을 원본과 대조해서 오차 범위를 파악하고, 오차가 큰 유형의 차트(예: 3D 차트, 이중 축 차트)는 수동 보정 파이프라인을 추가하거나 LLM의 답변에 “차트에서 추출한 근사값”임을 명시하도록 프롬프트를 설계합니다.
이미지 설명이 너무 일반적인 문제는 VLM에 주는 캡셔닝 프롬프트를 개선하면 해결됩니다. 단순히 “이 이미지를 설명해 줘” 대신 “이 이미지는 기술 문서의 일부입니다. 이미지에 포함된 모든 구성 요소, 텍스트 레이블, 화살표의 방향과 의미, 데이터 값을 상세히 기술하세요”처럼 구체적인 지시를 줍니다. 문서의 맥락(제목, 앞뒤 문단)을 함께 전달하면 설명의 품질이 한 단계 올라갑니다.
지금 시작한다면: 단계별 도입 로드맵
멀티모달 RAG를 처음 도입하려는 분들을 위해 실용적인 단계별 접근법을 제안합니다. 한꺼번에 완벽한 시스템을 만들려 하지 말고, 점진적으로 확장하는 것이 핵심입니다.
1단계: 표부터 시작하세요. 대부분의 비즈니스 문서에서 가장 먼저 해결해야 할 것은 표입니다. 기존 텍스트 RAG 파이프라인에 Unstructured나 Docling의 표 추출 기능만 추가해도 답변 정확도가 눈에 띄게 올라갑니다. 표를 마크다운으로 변환해서 텍스트 청크와 함께 인덱싱하는 것이 첫 발걸음입니다.
2단계: 이미지 캡셔닝을 붙이세요. 정보성 이미지를 VLM으로 텍스트 설명으로 변환하고, 이 설명을 인덱싱에 포함합니다. 이미지 자체를 벡터로 임베딩하는 것은 이후에 해도 됩니다. 텍스트 설명만으로도 “아키텍처 다이어그램에서 인증 흐름을 설명해 줘” 같은 질문에 대응할 수 있습니다.
3단계: 멀티모달 임베딩으로 전환하세요. Cohere Embed v4 같은 멀티모달 임베딩 모델을 도입해서 이미지와 텍스트를 통합 벡터 공간에 배치합니다. 이 단계에서 크로스 모달 검색(텍스트로 이미지 찾기, 이미지로 텍스트 찾기)이 가능해집니다.
4단계: 차트 데이터 추출과 하이브리드 검색을 추가하세요. 차트 전용 처리 파이프라인과 밀집·희소 하이브리드 검색을 도입해서 수치 질문의 정확도를 높입니다.
각 단계마다 평가 데이터셋으로 성능을 측정하고, 실제 사용자의 피드백을 반영해서 다음 단계로 넘어갑니다. 실무에서는 1~2단계만으로도 기존 텍스트 RAG 대비 체감 품질이 크게 향상되는 경우가 많습니다.
마무리: 문서의 전체를 이해하는 RAG로
멀티모달 RAG는 “문서의 텍스트만 읽는” 한계를 넘어 “문서 전체를 이해하는” 시스템을 가능하게 합니다. 표의 정확한 수치, 차트의 트렌드, 다이어그램의 구조적 정보까지 AI가 활용할 수 있게 되면, RAG 시스템의 실무 가치가 본질적으로 달라집니다.
모든 것을 한 번에 완벽하게 구현할 필요는 없습니다. 현재 가장 문제가 되는 요소—많은 경우 표—부터 해결하고, 효과를 확인하면서 점진적으로 확장하세요. 도구와 모델은 빠르게 발전하고 있어서, 올해 상반기 기준으로도 실무 적용에 충분한 성숙도에 도달했습니다.
기존 RAG에서 “답을 못 찾겠다”는 피드백이 반복된다면, 답이 텍스트가 아닌 표나 이미지에 숨어 있을 가능성이 높습니다. 멀티모달 RAG로의 전환이 그 문제의 실질적인 해법이 될 것입니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.