서비스를 운영하다 보면 누구나 한 번쯤은 이런 경험을 하게 됩니다. 새벽에 알림이 울려 대시보드를 열어봤더니 CPU 사용률이 치솟아 있는데, 도대체 어떤 요청이 문제인지 알 수 없는 상황. 로그를 뒤져봐도 에러 메시지는 없고, 메트릭만 빨간색으로 반짝이고 있죠. 결국 여러 서버를 돌아다니며 로그를 하나하나 grep 하다가 두 시간이 훌쩍 지나버립니다.
이런 상황이 반복된다면, 지금 여러분의 시스템에는 모니터링은 있지만 관측성(Observability)이 없는 것입니다. 모니터링은 미리 정해둔 지표가 임곗값을 넘으면 알림을 보내는 것이고, 관측성은 시스템 외부에서 내부 상태를 추론할 수 있게 해주는 능력입니다. 모니터링이 “무엇이 고장났는가”를 알려준다면, 관측성은 “왜 고장났는가”까지 답할 수 있게 해줍니다.
2026년 현재, 마이크로서비스와 클라우드 네이티브 아키텍처가 보편화되면서 관측성은 선택이 아닌 필수가 되었습니다. 서비스 하나가 수십 개의 컨테이너에 분산되어 동작하는 환경에서 전통적인 모니터링만으로는 문제를 진단할 수 없기 때문이죠. 그리고 이 관측성의 세계에서 사실상 표준으로 자리 잡은 것이 바로 OpenTelemetry입니다. 이 글에서는 OpenTelemetry를 중심으로 관측성의 핵심 개념부터 실제 구축 방법, 비용 최적화 전략까지 실전에서 바로 써먹을 수 있는 내용을 다뤄보겠습니다.
관측성의 세 기둥: 로그, 메트릭, 트레이스
관측성을 이야기할 때 빠지지 않고 등장하는 것이 바로 세 기둥(Three Pillars)입니다. 로그, 메트릭, 트레이스 — 이 세 가지 텔레메트리 데이터가 관측성의 토대를 이룹니다. 각각의 역할이 다르고, 셋이 합쳐졌을 때 비로소 시스템을 입체적으로 이해할 수 있게 됩니다.
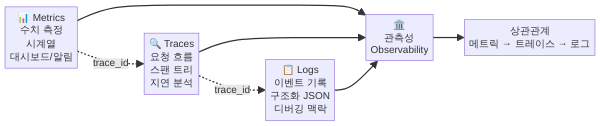
로그(Logs): 무슨 일이 일어났는가
로그는 가장 익숙한 텔레메트리 데이터입니다. 애플리케이션이 특정 시점에 발생한 이벤트를 텍스트 형태로 기록한 것이죠. “2026-05-31T09:15:23Z ERROR 주문 처리 실패: 재고 부족 (product_id=A1234)” 같은 형태가 전형적인 로그입니다.
로그의 강점은 맥락이 풍부하다는 점입니다. 에러 메시지, 스택 트레이스, 요청 파라미터 등 디버깅에 필요한 세부 정보를 담을 수 있습니다. 하지만 단점도 명확합니다. 비정형(unstructured) 로그는 검색과 집계가 어렵고, 대량으로 쌓이면 저장 비용이 급격히 늘어납니다.
그래서 현대적인 관측성 환경에서는 구조화 로그(Structured Logging)를 사용합니다. JSON 형태로 로그를 남기면 필드 단위로 검색·필터링·집계가 가능해집니다. 예를 들어 {“level”:”error”, “service”:”order-api”, “trace_id”:”abc123″, “message”:”재고 부족”}처럼 기록하면, 나중에 특정 trace_id로 해당 요청의 전체 경로를 추적할 수 있게 됩니다.
메트릭(Metrics): 얼마나 잘 동작하는가
메트릭은 시간에 따른 수치 데이터입니다. CPU 사용률, 메모리 점유율, 요청 처리 시간(latency), 초당 요청 수(throughput), 에러율 같은 것들이죠. 로그가 개별 이벤트를 기록한다면, 메트릭은 전체적인 추세와 패턴을 보여줍니다.
메트릭의 가장 큰 장점은 저장 효율입니다. 1분마다 하나의 숫자를 기록하기 때문에 수천 개의 메트릭을 수년간 보관해도 용량이 크지 않습니다. 또한 대시보드에서 실시간으로 시각화하기에 최적이고, 임곗값 기반 알림 설정도 자연스럽습니다.
관측성 관점에서 메트릭이 특히 중요한 이유는 RED 메서드와 USE 메서드 같은 체계적인 프레임워크가 있기 때문입니다. RED(Rate, Errors, Duration)는 서비스 수준에서 상태를 파악하는 데 쓰이고, USE(Utilization, Saturation, Errors)는 인프라 리소스 상태를 진단하는 데 활용됩니다. 이 두 가지를 함께 보면 “느린 건 알겠는데 왜 느린지 모르겠다”는 상황을 크게 줄일 수 있습니다.
트레이스(Traces): 요청이 어떻게 흘러갔는가
분산 트레이싱은 마이크로서비스 환경에서 관측성의 핵심입니다. 하나의 사용자 요청이 여러 서비스를 거치며 처리되는 과정을 시각적으로 추적할 수 있게 해줍니다. API 게이트웨이 → 주문 서비스 → 재고 서비스 → 결제 서비스 → 알림 서비스로 이어지는 요청 흐름에서 어디서 지연이 발생하는지, 어디서 에러가 나는지를 한눈에 파악할 수 있죠.
트레이스는 스팬(Span)이라는 단위로 구성됩니다. 각 스팬은 하나의 작업 단위를 나타내며, 시작 시간, 종료 시간, 상태, 속성(attributes) 등을 포함합니다. 스팬들은 부모-자식 관계로 연결되어 하나의 트레이스 트리를 형성합니다. 이 트리를 워터폴(Waterfall) 차트로 시각화하면, 전체 요청 중 어떤 단계에서 시간이 가장 많이 소요되는지 직관적으로 알 수 있습니다.
세 기둥의 상관관계가 진짜 힘이다
로그, 메트릭, 트레이스 각각도 유용하지만, 진정한 관측성의 힘은 이 셋이 상관관계(Correlation)로 연결될 때 발휘됩니다. 메트릭 대시보드에서 에러율 급증을 발견하면 해당 시간대의 트레이스로 넘어가서 실패한 요청을 찾고, 그 트레이스에 연결된 로그에서 구체적인 에러 원인을 확인하는 것이죠. trace_id라는 하나의 식별자가 로그와 트레이스를 관통하며, 메트릭에는 exemplar라는 기능으로 특정 데이터 포인트를 대표 트레이스와 연결합니다.
이런 상관관계가 바로 “왜 고장났는가”에 답할 수 있는 관측성의 본질입니다. 그리고 이 세 가지 데이터를 일관된 방식으로 수집·전송하는 표준이 바로 OpenTelemetry입니다.
OpenTelemetry: 관측성의 사실상 표준
OpenTelemetry(줄여서 OTel)는 CNCF(Cloud Native Computing Foundation)가 관리하는 오픈소스 관측성 프레임워크입니다. 2019년에 OpenTracing과 OpenCensus 두 프로젝트가 합쳐져 탄생했으며, 2026년 현재 Kubernetes 다음으로 CNCF에서 가장 활발한 프로젝트로 성장했습니다.
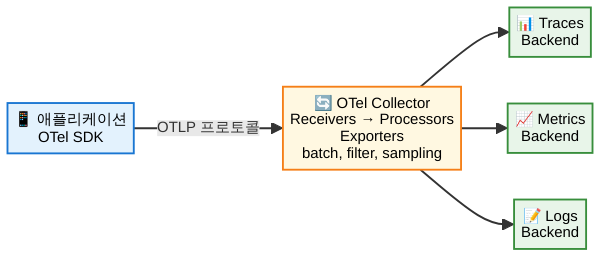
왜 OpenTelemetry인가
OpenTelemetry가 등장하기 전에는 각 관측성 벤더마다 자체 에이전트, 자체 SDK, 자체 프로토콜을 사용했습니다. Datadog 에이전트, New Relic 에이전트, Jaeger 클라이언트, Zipkin 라이브러리… 벤더를 바꾸려면 계측(instrumentation) 코드를 전부 뜯어고쳐야 했죠. 이것은 사실상 벤더 종속(Vendor Lock-in)이었습니다.
OpenTelemetry는 이 문제를 해결합니다. 계측은 OTel SDK로 한 번만 하고, 수집한 데이터를 어디로 보낼지는 설정만 바꾸면 됩니다. Jaeger에서 Grafana Tempo로, 혹은 Datadog으로 백엔드를 자유롭게 전환할 수 있습니다. 이런 유연성 덕분에 대부분의 관측성 벤더들이 OTel을 공식 지원하게 되었고, 사실상 업계 표준이 된 것입니다.
OpenTelemetry의 핵심 구성 요소
OTel은 크게 세 가지 구성 요소로 이루어져 있습니다.
첫 번째는 API와 SDK입니다. API는 언어별로 제공되는 인터페이스로, 애플리케이션 코드에서 텔레메트리 데이터를 생성하는 방법을 정의합니다. SDK는 이 API의 구현체로, 데이터 처리, 배치 전송, 샘플링 등 실제 동작을 담당합니다. Python, Java, Go, JavaScript, .NET, Rust 등 주요 언어를 모두 지원합니다.
두 번째는 자동 계측(Auto-instrumentation)입니다. 코드를 한 줄도 수정하지 않고 텔레메트리를 수집할 수 있게 해주는 기능입니다. Python의 경우 opentelemetry-instrument 명령어 하나로 Flask, Django, FastAPI, requests, SQLAlchemy 같은 라이브러리의 호출을 자동으로 추적합니다. Java는 javaagent 방식으로 동작하며, Node.js도 자동 계측을 지원합니다. 자동 계측만으로도 서비스 간 호출, DB 쿼리, HTTP 요청 등 대부분의 외부 통신을 트레이싱할 수 있습니다.
세 번째는 OpenTelemetry Collector입니다. 관측성 데이터의 허브 역할을 하는 독립 프로세스입니다. 애플리케이션이 보낸 텔레메트리 데이터를 받아서(Receiver), 변환·필터링·보강하고(Processor), 최종 백엔드로 전달합니다(Exporter). Collector를 사이에 두면 애플리케이션은 백엔드의 종류를 몰라도 되고, Collector 설정만 바꿔서 데이터 경로를 자유자재로 제어할 수 있습니다.
OTLP: 텔레메트리의 공용어
OpenTelemetry Protocol(OTLP)은 OTel이 정의한 텔레메트리 데이터 전송 프로토콜입니다. gRPC와 HTTP 두 가지 전송 방식을 지원하며, 로그, 메트릭, 트레이스 세 종류의 데이터를 모두 하나의 프로토콜로 전송할 수 있습니다. 대부분의 관측성 백엔드가 OTLP를 네이티브로 지원하기 때문에, OTLP로 데이터를 보내기만 하면 어떤 백엔드든 연결할 수 있습니다.
실전 구축: 오픈소스 관측성 스택 한 번에 올리기
이론은 충분히 살펴봤으니, 이제 실제로 관측성 환경을 구축해보겠습니다. 상용 SaaS를 쓰면 간편하지만 비용이 만만치 않죠. 여기서는 완전히 무료인 오픈소스 도구들로 로컬 환경에 관측성 스택을 세팅하는 방법을 다룹니다. 사이드 프로젝트나 소규모 팀이라면 이 구성으로 충분히 실용적인 관측성을 확보할 수 있습니다.
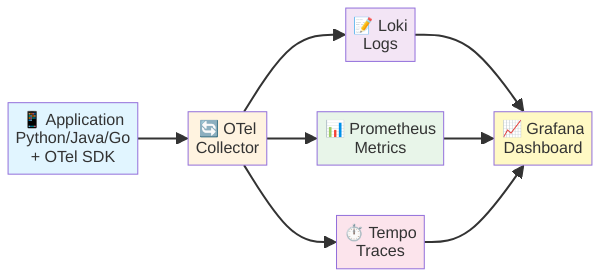
스택 구성: Grafana LGTM
오픈소스 관측성 스택으로 가장 많이 쓰이는 조합은 Grafana가 주도하는 LGTM 스택입니다.
- Loki — 로그 집계 시스템. Prometheus에서 영감을 받아 설계되었으며, 로그 내용 자체는 인덱싱하지 않고 레이블만 인덱싱하여 저장 비용을 획기적으로 낮춥니다.
- Grafana — 시각화 대시보드. 메트릭, 로그, 트레이스를 하나의 UI에서 모두 조회하고, 상관관계를 탐색할 수 있습니다.
- Tempo — 분산 트레이스 백엔드. 오브젝트 스토리지에 트레이스를 저장하므로 운영이 간편하고 비용 효율적입니다.
- Mimir(또는 Prometheus) — 메트릭 저장소. 소규모라면 Prometheus 단독으로, 대규모라면 장기 보관과 수평 확장이 가능한 Mimir를 사용합니다.
여기에 OpenTelemetry Collector를 앞단에 놓으면 애플리케이션에서 보내는 모든 텔레메트리 데이터를 하나의 엔드포인트로 수신한 뒤 각 백엔드로 분배할 수 있습니다.
Docker Compose로 로컬에 띄우기
실전 환경에서는 Kubernetes에 Helm Chart로 배포하는 것이 일반적이지만, 로컬에서 빠르게 시작하려면 Docker Compose가 최적입니다. 핵심 구성 요소를 살펴보겠습니다.
먼저 OpenTelemetry Collector의 설정 파일(otel-collector-config.yaml)입니다. Collector가 어떤 데이터를 받아서 어디로 보낼지 정의하는 핵심 파일이죠.
Receiver 섹션에서는 OTLP 프로토콜의 gRPC(4317 포트)와 HTTP(4318 포트)를 모두 열어둡니다. 애플리케이션이 어떤 방식으로 데이터를 보내든 수신할 수 있게 하기 위해서입니다.
Processor 섹션에서는 batch processor를 설정합니다. 텔레메트리 데이터를 건건이 보내면 네트워크 오버헤드가 크기 때문에, 일정 시간(예: 5초) 또는 일정 건수(예: 1024건) 동안 모아서 한꺼번에 전송합니다. 이 설정 하나로 네트워크 효율이 크게 개선됩니다.
Exporter 섹션에서는 각 백엔드의 엔드포인트를 지정합니다. 트레이스는 Tempo(tempo:4317)로, 메트릭은 Prometheus remote write 엔드포인트로, 로그는 Loki(loki:3100)로 보내도록 설정합니다.
마지막으로 Pipeline 섹션에서 이 세 가지를 연결합니다. traces, metrics, logs 각각에 대해 receiver → processor → exporter 파이프라인을 정의하면 데이터 흐름이 완성됩니다.
애플리케이션 계측: Python 예시
실제 애플리케이션에 OpenTelemetry를 적용하는 방법을 Python FastAPI 기준으로 살펴보겠습니다. 가장 빠른 방법은 자동 계측입니다.
우선 필요한 패키지를 설치합니다. opentelemetry-distro와 opentelemetry-exporter-otlp를 pip로 설치하고, opentelemetry-bootstrap -a install 명령을 실행하면 현재 환경에 설치된 라이브러리(FastAPI, httpx, SQLAlchemy 등)에 맞는 자동 계측 패키지가 자동으로 설치됩니다.
그 다음 애플리케이션을 실행할 때 opentelemetry-instrument 명령을 앞에 붙여주면 됩니다. 환경변수로 서비스 이름, Collector 엔드포인트, 로그 내보내기 활성화 여부 등을 지정합니다.
이것만으로도 HTTP 요청/응답, DB 쿼리, 외부 API 호출 등에 대한 트레이스가 자동으로 생성됩니다. 코드를 한 줄도 수정하지 않았는데 Grafana에서 요청 흐름을 추적할 수 있게 되는 것이죠.
물론 자동 계측만으로는 비즈니스 로직 수준의 세밀한 추적이 어렵습니다. 특정 함수의 실행 시간을 측정하거나, 주문 ID 같은 비즈니스 속성을 스팬에 추가하고 싶다면 수동 계측을 함께 사용합니다. OTel SDK의 tracer를 가져와서 with 구문으로 커스텀 스팬을 만들고, set_attribute로 원하는 속성을 추가하면 됩니다. 자동 계측이 큰 틀을 잡아주고, 수동 계측으로 비즈니스 맥락을 보강하는 것이 가장 효과적인 패턴입니다.
Grafana에서 상관관계 탐색하기
데이터가 수집되기 시작하면, Grafana에서 진정한 관측성을 체험할 수 있습니다. Grafana의 강점은 데이터소스 간 연결입니다.
Prometheus 데이터소스의 Exemplar 기능을 활성화하면, 메트릭 그래프 위에 작은 점들이 나타납니다. 이 점을 클릭하면 해당 시점의 대표 트레이스로 바로 이동합니다. “응답 시간 99퍼센타일이 왜 이렇게 높지?” → 클릭 → 느린 요청의 전체 경로를 워터폴 차트로 확인 → 특정 DB 쿼리에서 800ms가 걸린 것을 발견. 이 흐름이 가능해집니다.
Tempo의 트레이스 상세 화면에서는 각 스팬에 연결된 로그를 바로 조회할 수 있습니다. trace_id가 로그의 필드에 포함되어 있기 때문에, Loki에서 해당 trace_id로 필터링한 로그가 자동으로 표시됩니다. 에러가 발생한 스팬을 클릭하면 그 시점에 기록된 에러 로그와 스택 트레이스를 즉시 확인할 수 있습니다.
이러한 메트릭 → 트레이스 → 로그의 드릴다운 경로가 바로 관측성이 모니터링과 근본적으로 다른 점입니다. 미리 정해둔 대시보드만 보는 것이 아니라, 문제를 발견한 지점에서 출발하여 원인까지 자유롭게 탐색할 수 있는 것이죠.
관측성 데이터 비용 최적화 전략
관측성을 도입한 뒤 가장 흔하게 마주치는 문제가 바로 데이터 폭증입니다. 모든 요청의 모든 스팬을 저장하고, 모든 로그를 보관하고, 수천 개의 메트릭 시계열을 유지하다 보면 저장 비용과 쿼리 성능 모두 감당하기 어려워집니다. 특히 SaaS 관측성 플랫폼을 사용하는 경우 데이터량에 비례하여 과금되기 때문에, 최적화 없이는 말 그대로 비용 폭탄을 맞을 수 있습니다.

트레이스 샘플링: 모든 것을 저장할 필요는 없다
트레이스는 관측성 데이터 중 가장 용량이 큽니다. 초당 수천 건의 요청을 처리하는 서비스에서 모든 트레이스를 저장하면 하루에 수 기가바이트가 쌓이죠. 하지만 실제로 분석에 필요한 트레이스는 전체의 극히 일부입니다. 여기서 샘플링이 등장합니다.
헤드 기반 샘플링(Head-based Sampling)은 가장 단순한 방식입니다. 요청이 시작되는 시점에 “이 트레이스를 수집할지 말지”를 확률적으로 결정합니다. 예를 들어 샘플링 비율을 10%로 설정하면, 10개 중 1개의 트레이스만 저장됩니다. 구현이 간단하고 예측 가능하지만, 중요한 에러 트레이스가 버려질 수 있다는 단점이 있습니다.
테일 기반 샘플링(Tail-based Sampling)은 이 문제를 해결합니다. 트레이스의 모든 스팬이 완료된 후에 샘플링 여부를 결정하는 방식입니다. 에러가 포함된 트레이스, 응답 시간이 비정상적으로 긴 트레이스는 100% 보관하고, 정상적인 트레이스는 낮은 비율로만 저장합니다. OpenTelemetry Collector의 tail_sampling processor를 사용하면 이를 쉽게 구현할 수 있습니다.
테일 기반 샘플링의 정책 예시를 보겠습니다. 에러 상태 코드가 포함된 트레이스는 무조건 보관, 응답 시간이 2초를 초과하는 트레이스도 무조건 보관, 특정 서비스(결제 서비스 등)의 트레이스는 50%를 보관, 나머지는 5%만 보관. 이런 식으로 중요한 데이터는 놓치지 않으면서 전체 저장량을 크게 줄일 수 있습니다.
다만 테일 기반 샘플링은 Collector가 트레이스의 모든 스팬을 메모리에 잠시 보관해야 하므로, Collector의 리소스 사용량이 늘어난다는 점을 고려해야 합니다. 대규모 트래픽 환경에서는 Collector를 두 단계로 분리하여, 첫 번째 단계에서 데이터를 수집하고 두 번째 단계에서 샘플링을 수행하는 구성을 권장합니다.
로그 최적화: 레벨과 구조가 핵심
로그 비용을 줄이는 가장 효과적인 방법은 로그 레벨 관리입니다. 프로덕션 환경에서 DEBUG 레벨 로그를 남기면 데이터량이 10배 이상 늘어날 수 있습니다. 기본은 INFO 이상으로 설정하고, 특정 모듈만 디버깅이 필요할 때 동적으로 레벨을 낮추는 방식이 효율적입니다.
로그 필터링과 변환도 OpenTelemetry Collector에서 처리할 수 있습니다. filter processor를 사용하면 특정 조건의 로그를 드롭하거나, transform processor로 불필요한 필드를 제거하거나, attributes processor로 민감 정보를 마스킹할 수 있습니다. 이렇게 Collector 단계에서 데이터를 정제하면 백엔드 저장소의 부하와 비용을 효과적으로 관리할 수 있습니다.
Loki를 사용한다면 레이블 설계에도 주의를 기울여야 합니다. Loki는 레이블 조합별로 스트림을 생성하는데, 레이블의 카디널리티(고유 값의 수)가 너무 높으면 스트림 수가 폭증하여 성능이 저하됩니다. service, environment, level 정도의 저카디널리티 레이블만 인덱스에 사용하고, request_id나 user_id 같은 고카디널리티 값은 로그 본문에 구조화 필드로 남기는 것이 좋습니다.
메트릭 최적화: 카디널리티 관리
메트릭에서 가장 주의해야 할 것은 카디널리티 폭발(Cardinality Explosion)입니다. 메트릭의 레이블에 사용자 ID, 세션 ID, 요청 경로(파라미터 포함) 같은 고유 값을 넣으면 시계열 수가 기하급수적으로 늘어납니다. 예를 들어 HTTP 요청 메트릭에 전체 URL 경로를 레이블로 넣으면, /users/1, /users/2, … /users/100000 각각이 별도의 시계열이 되어 Prometheus가 메모리 부족으로 죽을 수 있습니다.
해결책은 URL 패턴을 정규화하는 것입니다. /users/12345를 /users/{id}로 변환하여 레이블에 넣으면 시계열 수를 극적으로 줄일 수 있습니다. OpenTelemetry의 HTTP 관련 계측 라이브러리들은 대부분 이런 정규화를 기본으로 지원합니다.
또한 불필요한 메트릭 드롭도 효과적입니다. 자동 계측이 생성하는 메트릭 중 실제로 사용하지 않는 것들이 있을 수 있습니다. Collector의 filter processor나 Prometheus의 metric_relabel_configs로 불필요한 메트릭을 저장 전에 제거하면 스토리지 비용을 절약할 수 있습니다.
관측성 도입 시 흔한 실수와 대처법
관측성을 처음 도입하는 팀에서 자주 저지르는 실수들이 있습니다. 미리 알고 피하면 시행착오를 크게 줄일 수 있습니다.
실수 1: 모든 것을 한꺼번에 도입하려고 한다
로그, 메트릭, 트레이스를 동시에 모든 서비스에 적용하려는 것은 거의 확실히 실패합니다. 대신 점진적 접근을 권합니다. 가장 효과가 큰 하나부터 시작하세요. 마이크로서비스 환경이라면 분산 트레이싱부터, 모놀리식이라면 구조화 로그부터 시작하는 것이 보통입니다. 한 가지를 안정화한 뒤 다음을 추가하면 학습 곡선도 완만하고, 각 단계에서 가시적인 성과를 얻을 수 있습니다.
실수 2: 대시보드만 만들고 알림을 설정하지 않는다
아무리 훌륭한 대시보드를 만들어도 아무도 24시간 지켜보지 않습니다. 관측성의 가치는 문제가 생겼을 때 빠르게 인지하고 빠르게 진단하는 데 있습니다. 핵심 SLI(Service Level Indicator)에 대한 알림을 반드시 설정하세요. 에러율이 1%를 넘으면, P99 응답 시간이 3초를 넘으면, 큐 적체량이 1000건을 넘으면 — 이런 구체적인 조건으로 알림을 만들어야 합니다.
실수 3: 계측 코드를 비즈니스 로직에 깊이 심는다
관측성 코드가 비즈니스 로직과 뒤엉키면 유지보수가 어려워집니다. OpenTelemetry의 자동 계측을 최대한 활용하고, 수동 계측이 필요한 경우에도 데코레이터, 미들웨어, 컨텍스트 매니저 같은 래핑 패턴으로 분리하세요. 계측 코드는 언제든 제거하거나 변경할 수 있어야 합니다.
실수 4: 관측성을 개발 초기가 아닌 장애 후에 도입한다
“아직 서비스가 작은데 관측성까지 필요한가”라는 생각은 자연스럽지만, 관측성은 서비스가 작을 때 도입하는 것이 훨씬 쉽습니다. 서비스가 복잡해진 뒤에 사후적으로 계측을 추가하려면 코드 베이스 전체를 훑어야 하고, 이미 발생한 장애의 원인은 과거 데이터가 없어서 분석이 불가능합니다. OpenTelemetry의 자동 계측 덕분에 초기 도입 비용은 매우 낮으니, 가능한 한 빨리 시작하는 것이 현명합니다.
2026년 관측성 트렌드: 주목할 만한 흐름
마지막으로 관측성 분야에서 주목할 만한 최신 트렌드를 간략히 짚어보겠습니다.
eBPF 기반 관측성
eBPF(extended Berkeley Packet Filter)를 활용한 관측성 도구가 빠르게 성장하고 있습니다. eBPF는 리눅스 커널 레벨에서 동작하기 때문에 애플리케이션 코드를 전혀 수정하지 않고도 네트워크 트래픽, 시스템 콜, 파일 I/O 등을 관측할 수 있습니다. Cilium의 Hubble, Grafana의 Beyla 같은 도구가 대표적이며, 특히 사이드카 없이 서비스 메시 수준의 관측성을 확보할 수 있다는 점에서 Kubernetes 환경에서 각광받고 있습니다.
연속 프로파일링(Continuous Profiling)
로그, 메트릭, 트레이스에 이어 프로파일이 관측성의 네 번째 기둥으로 부상하고 있습니다. Grafana Pyroscope, Parca 같은 오픈소스 도구로 프로덕션 환경의 CPU, 메모리 프로파일을 상시 수집할 수 있게 되었습니다. 트레이스에서 특정 스팬이 느린 것을 발견했을 때, 해당 시점의 프로파일로 드릴다운하면 어떤 함수가 CPU를 많이 사용했는지까지 확인할 수 있습니다. OpenTelemetry도 프로파일링 시그널을 공식 지원하기 시작했으며, 향후 네 가지 시그널이 완전히 통합될 것으로 기대됩니다.
AI 기반 이상 탐지
수천 개의 메트릭과 수백만 줄의 로그를 사람이 일일이 모니터링하는 것은 불가능합니다. AI/ML 기반 이상 탐지(Anomaly Detection)가 이 문제를 보완하고 있습니다. 정상 패턴을 학습한 모델이 비정상적인 메트릭 변동이나 로그 패턴을 자동으로 감지하고, 관련된 트레이스와 로그를 자동으로 상관시켜 알림을 보내는 것이죠. Datadog, Dynatrace 같은 상용 플랫폼이 선도하고 있지만, 오픈소스 진영에서도 Grafana의 ML 기능이나 별도의 이상 탐지 파이프라인을 구축하는 사례가 늘고 있습니다.
마무리: 작게 시작하고, 꾸준히 확장하기
관측성은 한 번 구축하고 끝나는 프로젝트가 아닙니다. 서비스가 성장하고 아키텍처가 변화함에 따라 관측성도 함께 진화해야 합니다. 하지만 첫걸음은 생각보다 어렵지 않습니다.
오늘 당장 시작할 수 있는 가장 작은 단계를 제안합니다. 여러분의 프로젝트에 OpenTelemetry 자동 계측을 적용해보세요. Python이라면 패키지 두 개 설치하고 실행 명령어만 바꾸면 됩니다. 그리고 Docker Compose로 Grafana + Tempo를 띄워서 트레이스를 시각화해보세요. 여러분의 서비스 내부에서 요청이 어떻게 흘러가는지 처음으로 눈에 보이는 순간, 관측성의 가치를 체감하게 될 것입니다.
모니터링이 “이상 있음”을 알려주는 화재 경보기라면, 관측성은 “왜 불이 났고 어디서 시작됐는지”를 보여주는 투시경입니다. 서비스 규모에 상관없이, 지금 시작하는 것이 가장 좋은 타이밍입니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.