
[Cloudflare 완전 정복: 입문부터 2026 AI 에이전트까지] 10/16화: Workers KV vs D1 vs Durable Objects 선택 가이드
이 글은 「Cloudflare 완전 정복」 시리즈 10회입니다. 지난 9회에서 Workers의 첫 배포와 엣지 컴퓨팅 기초를 다뤘다면, 오늘은 Workers가 데이터를 어디에, 어떻게 저장하는지를 깊이 파고듭니다.
서버리스 코드를 전 세계 300여 개 엣지에서 실행할 수 있다는 건 9회에서 확인했습니다. 그런데 코드만으로는 의미 있는 서비스를 만들 수 없습니다. 사용자 설정을 기억하고, 주문 이력을 쿼리하고, 실시간 채팅방의 참여자 목록을 관리하려면 — 상태(state)가 필요합니다. Cloudflare는 이 문제를 해결하기 위해 성격이 전혀 다른 세 가지 스토리지를 제공합니다. Workers KV, D1, 그리고 Durable Objects. 어떤 것을 언제 써야 할까요?
엣지에서 데이터를 저장한다는 것
전통적인 클라우드에서는 데이터베이스가 특정 리전(예: us-east-1)에 존재합니다. 사용자 요청이 서울에서 출발해도 데이터를 읽으려면 결국 미국까지 왕복해야 합니다. Cloudflare Workers의 핵심 가치는 코드를 사용자 가까이에서 실행하는 것인데, 데이터가 멀리 있으면 그 이점이 반감됩니다.
이 근본적인 딜레마를 해결하기 위해 Cloudflare는 세 가지 서로 다른 트레이드오프를 선택했습니다.
- Workers KV — 데이터를 전 세계에 복제해서 어디서든 빠르게 읽되, 쓰기 반영은 느린 것을 감수합니다.
- D1 — 관계형 SQL의 표현력을 유지하되, 리드 리플리카로 읽기 지연을 줄입니다.
- Durable Objects — 단 하나의 인스턴스에서 강한 일관성을 보장하되, 분산 읽기를 포기합니다.
CAP 정리를 떠올리면 직관적입니다. KV는 가용성(A)과 분할 내성(P)을, D1은 일관성(C)과 가용성(A)을, Durable Objects는 일관성(C)과 분할 내성(P)을 택한 셈입니다. 물론 실제 구현은 이보다 미묘하지만, 핵심 방향성은 이렇게 이해하면 됩니다.
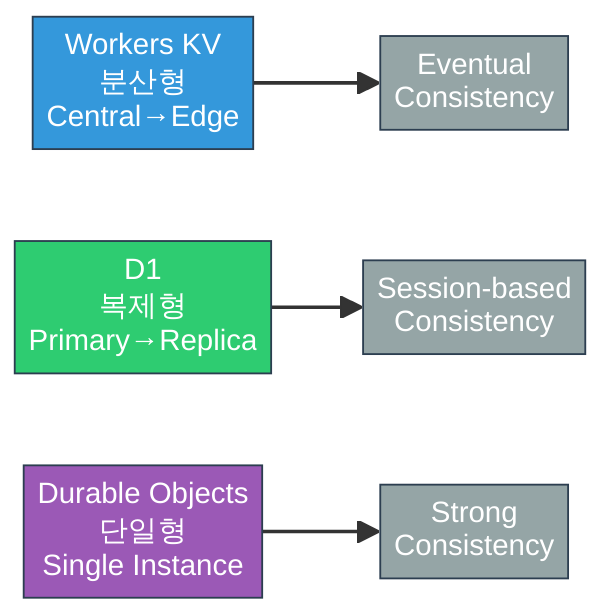
Workers KV — 글로벌 읽기 최적화 키-밸류 스토어
아키텍처: 쓰기는 중앙, 읽기는 엣지
Workers KV(Key-Value)는 Cloudflare가 가장 먼저 내놓은 엣지 스토리지입니다. 이름 그대로 키-밸류 구조이며, 핵심 특성은 결과적 일관성(eventual consistency)입니다.
데이터를 쓰면 먼저 중앙 스토어에 기록되고, 이후 전 세계 엣지 PoP(Point of Presence)로 비동기 복제됩니다. 복제가 완료되기 전에 다른 엣지에서 같은 키를 읽으면 이전 값이 반환될 수 있습니다. Cloudflare 공식 문서에 따르면 쓰기 후 전 세계 전파까지 최대 60초가 걸릴 수 있습니다.
반면 읽기는 극도로 빠릅니다. 이미 캐시된 값은 사용자에게 가장 가까운 엣지에서 바로 반환되므로, 읽기 지연이 사실상 0에 가깝습니다. 이런 특성 때문에 KV는 “자주 읽고 가끔 쓰는” 워크로드에 최적입니다.
각 밸류의 최대 크기는 25 MiB, 키는 최대 512 바이트입니다. 네임스페이스당 키 개수에는 제한이 없습니다. 하나의 Workers 프로젝트에 여러 KV 네임스페이스를 바인딩할 수 있으므로, 용도별로 네임스페이스를 분리하는 것이 일반적입니다.
핵심 API와 실전 코드
KV API는 놀라울 정도로 단순합니다. put, get, delete, list — 이 네 가지가 전부입니다.
// wrangler.toml에서 KV 네임스페이스 바인딩
// [[kv_namespaces]]
// binding = "SETTINGS"
// id = "abc123..."
export default {
async fetch(request, env) {
const url = new URL(request.url);
// 쓰기: 키에 값 저장 (TTL 옵션)
await env.SETTINGS.put("site:theme", "dark", {
expirationTtl: 86400 // 24시간 후 자동 삭제
});
// 읽기: 키로 값 조회
const theme = await env.SETTINGS.get("site:theme");
// theme === "dark"
// JSON 자동 파싱
await env.SETTINGS.put("user:1001", JSON.stringify({
name: "김개발",
plan: "pro",
createdAt: "2026-06-01"
}));
const user = await env.SETTINGS.get("user:1001", { type: "json" });
// user.name === "김개발"
// 목록 조회: 접두사 기반 필터링
const allUsers = await env.SETTINGS.list({ prefix: "user:" });
// allUsers.keys → [{ name: "user:1001" }, ...]
// 삭제
await env.SETTINGS.delete("site:theme");
return new Response(JSON.stringify(user), {
headers: { "Content-Type": "application/json" }
});
}
};코드에서 보듯 env.SETTINGS는 wrangler.toml에서 바인딩한 KV 네임스페이스 이름입니다. get에 { type: "json" }을 전달하면 자동으로 JSON.parse를 해주므로 편리합니다.
메타데이터 활용 패턴
KV의 숨은 기능 중 하나가 메타데이터(metadata)입니다. 각 키-밸류 쌍에 최대 1,024 바이트의 JSON 메타데이터를 붙일 수 있습니다. 핵심은 — list 호출 시 메타데이터가 함께 반환된다는 점입니다.
// 메타데이터와 함께 저장
await env.PAGES.put("post:2026-06-10", htmlContent, {
metadata: {
title: "Workers KV vs D1 완전 비교",
author: "김개발",
publishedAt: "2026-06-10T09:00:00Z",
tags: ["cloudflare", "workers", "storage"]
}
});
// list로 메타데이터만 빠르게 조회 (본문 읽기 없이!)
const posts = await env.PAGES.list({ prefix: "post:" });
for (const key of posts.keys) {
console.log(key.name, key.metadata.title);
// "post:2026-06-10" "Workers KV vs D1 완전 비교"
}
// 본문(25MiB까지 가능)을 읽지 않고도 목록+제목을 뽑을 수 있다!이 패턴은 블로그 글 목록, 제품 카탈로그, 설정 레지스트리 같은 시나리오에서 매우 유용합니다. 무거운 본문을 읽지 않고 메타데이터만으로 목록 페이지를 구성할 수 있기 때문입니다.
KV의 한계: 이것은 데이터베이스가 아닙니다
Workers KV를 쓸 때 반드시 기억해야 할 한계들이 있습니다.
- 결과적 일관성: 쓰기 직후 같은 키를 읽으면 이전 값이 나올 수 있습니다. 같은 엣지에서는 즉시 반영되지만, 다른 엣지에서는 최대 60초 지연.
- 쿼리 불가: “plan이 pro인 사용자를 모두 찾아줘”는 불가능합니다. 키의 접두사(prefix)로만 검색할 수 있습니다.
- 원자적 연산 없음: “조회수를 1 증가”를 안전하게 하려면 KV만으로는 부족합니다. 두 요청이 동시에 같은 키를 읽고 쓰면 하나가 덮어씌워집니다.
- 쓰기 제한: 같은 키에 대해 초당 1회 쓰기가 권장 상한입니다. 잦은 쓰기가 필요하면 KV 대신 Durable Objects를 고려하세요.
- list 성능: 한 번에 최대 1,000개 키를 반환합니다. 수십만 키를 순회하려면 커서(cursor) 기반 페이지네이션이 필요하고, 그만큼 시간이 걸립니다.
KV가 빛나는 곳: 설정(feature flag, A/B 테스트 변수), 정적 자산 매핑, URL 리다이렉트 맵, 지역별 요금표, i18n 번역 데이터, API 응답 캐시. 요약하면 — 많이 읽고, 가끔 쓰고, 즉각적 일관성이 필요 없는 모든 경우.
D1 — 엣지에서 돌아가는 SQLite
아키텍처: 리드 리플리카의 마법
D1은 Cloudflare의 관계형 데이터베이스입니다. 내부적으로 SQLite를 사용하며, 2025년 GA(General Availability)를 거쳐 2026년 현재 프로덕션에서 안정적으로 사용되고 있습니다.
D1의 아키텍처를 이해하려면 두 계층을 구분해야 합니다.
- Primary(주 인스턴스): 단일 위치에 존재하는 쓰기 담당. 생성 시 가장 가까운 Cloudflare 리전에 자동 배치됩니다. 모든
INSERT,UPDATE,DELETE는 여기서 처리됩니다. - Read Replicas(리드 리플리카): 사용자에게 가까운 엣지에 자동 생성되는 읽기 전용 복제본.
SELECT쿼리는 가장 가까운 리플리카에서 실행되므로 지연이 대폭 줄어듭니다.
이 구조 덕분에 D1은 “SQL의 표현력 + 엣지의 읽기 속도”를 동시에 제공합니다. 쓰기는 Primary에서만 이루어지므로 트랜잭션과 일관성이 보장되고, 읽기는 리플리카가 처리하므로 글로벌 사용자에게도 빠릅니다.
D1의 또 다른 강점은 Time Travel입니다. 30일간의 데이터 변경 이력을 자동 보존하여, 실수로 데이터를 삭제해도 특정 시점으로 복구할 수 있습니다. 별도 백업 설정 없이 기본 제공됩니다.
SQL로 데이터 모델링하기
D1은 SQLite 문법을 그대로 사용합니다. Workers 코드에서 env.DB로 바인딩된 D1 인스턴스에 SQL을 실행합니다.
// wrangler.toml
// [[d1_databases]]
// binding = "DB"
// database_name = "my-saas-db"
// database_id = "xxxx-yyyy-zzzz"
export default {
async fetch(request, env) {
const url = new URL(request.url);
// 테이블 생성 (최초 1회, 또는 마이그레이션으로)
await env.DB.exec(`
CREATE TABLE IF NOT EXISTS posts (
id INTEGER PRIMARY KEY AUTOINCREMENT,
slug TEXT UNIQUE NOT NULL,
title TEXT NOT NULL,
content TEXT,
author_id INTEGER NOT NULL,
view_count INTEGER DEFAULT 0,
created_at TEXT DEFAULT (datetime('now')),
updated_at TEXT DEFAULT (datetime('now'))
)
`);
// 데이터 삽입 — 바인드 파라미터로 SQL 인젝션 방지
const result = await env.DB.prepare(
"INSERT INTO posts (slug, title, content, author_id) VALUES (?, ?, ?, ?)"
).bind("kv-vs-d1", "KV와 D1 비교", "본문 내용...", 1001).run();
// result.meta.last_row_id → 삽입된 행의 ID
// 조건 검색 — KV로는 불가능한 쿼리
const posts = await env.DB.prepare(
"SELECT id, slug, title, view_count FROM posts WHERE author_id = ? ORDER BY created_at DESC LIMIT 10"
).bind(1001).all();
// posts.results → [{ id: 1, slug: "kv-vs-d1", ... }]
// 집계 쿼리
const stats = await env.DB.prepare(
"SELECT COUNT(*) as total, SUM(view_count) as total_views FROM posts WHERE author_id = ?"
).bind(1001).first();
// stats.total → 42, stats.total_views → 12580
// 배치 실행: 여러 쿼리를 하나의 트랜잭션으로
const batchResults = await env.DB.batch([
env.DB.prepare("UPDATE posts SET view_count = view_count + 1 WHERE slug = ?").bind("kv-vs-d1"),
env.DB.prepare("INSERT INTO view_logs (post_slug, viewed_at) VALUES (?, datetime('now'))").bind("kv-vs-d1"),
]);
// 둘 다 성공하거나 둘 다 롤백
return Response.json(posts.results);
}
};눈여겨볼 점은 DB.batch()입니다. 배열로 전달한 쿼리들이 하나의 트랜잭션으로 실행되어, 전부 성공하거나 전부 롤백됩니다. 조회수 증가와 로그 기록을 원자적으로 처리하는 것이 가능합니다.
D1 Sessions: 읽기-쓰기 일관성 문제 해결
D1을 사용하다 보면 마주치는 시나리오가 있습니다. 글을 저장한 직후 목록 페이지로 리다이렉트했는데, 방금 쓴 글이 보이지 않는 경우. 쓰기는 Primary에서 처리되고, 목록 읽기는 아직 복제가 완료되지 않은 리플리카에서 처리되기 때문입니다.
이 문제를 해결하기 위해 D1은 Sessions API를 제공합니다.
export default {
async fetch(request, env) {
// 세션 토큰으로 D1 세션 생성
// 같은 토큰을 가진 후속 요청은 "최소한 이전 쓰기 시점 이후"의
// 데이터를 읽는 것이 보장됨
const sessionToken = request.headers.get("x-d1-session") || crypto.randomUUID();
const session = env.DB.withSession(sessionToken);
if (request.method === "POST") {
// 쓰기: Primary에서 실행
const body = await request.json();
await session.prepare(
"INSERT INTO posts (slug, title, content, author_id) VALUES (?, ?, ?, ?)"
).bind(body.slug, body.title, body.content, body.authorId).run();
return new Response(null, {
status: 303,
headers: {
"Location": "/posts",
"x-d1-session": sessionToken // 세션 토큰을 클라이언트에 반환
}
});
}
// 읽기: 세션 토큰 덕분에 방금 쓴 데이터가 보장됨
const posts = await session.prepare(
"SELECT * FROM posts ORDER BY created_at DESC LIMIT 20"
).all();
return Response.json(posts.results, {
headers: { "x-d1-session": sessionToken }
});
}
};withSession(token)으로 생성한 세션을 통해 쿼리를 실행하면, 같은 토큰의 이전 쓰기가 반영된 시점 이후의 데이터를 읽는 것이 보장됩니다. 일반적으로 세션 토큰은 쿠키나 커스텀 헤더로 클라이언트에 전달합니다.
D1의 한계와 주의사항
- 데이터베이스 크기: Free 플랜에서 500 MB, Workers Paid에서 10 GB가 기본 상한입니다. 대용량 데이터에는 R2와 조합하세요.
- 쓰기 지연: 모든 쓰기가 Primary를 경유하므로, Primary가 미국에 있고 사용자가 한국에 있으면 쓰기 지연이 200~300ms에 달할 수 있습니다.
- 동시 쓰기 제한: 단일 Primary에 쓰기가 집중되므로, 초당 수천 건의 쓰기가 필요한 워크로드에는 적합하지 않습니다.
- SQLite 제약 상속:
ALTER TABLE의 일부 문법(DROP COLUMN등)이 SQLite 버전에 따라 제한됩니다. 스토어드 프로시저, 사용자 정의 함수도 없습니다. - 행 크기: 단일 행의 최대 크기가 제한되어 있으므로(약 1 MB), 대용량 BLOB은 R2에 저장하고 URL만 D1에 기록하는 패턴을 권장합니다.
D1이 빛나는 곳: 사용자 프로필, 게시글/댓글, 주문 이력, 제품 카탈로그, 태그·카테고리 관계, 검색 필터링 — 요약하면 관계가 있고, 조건으로 검색해야 하고, 쓰기보다 읽기가 많은 모든 정형 데이터.
Durable Objects — 단일 인스턴스 상태 조율기
아키텍처: 전 세계에 하나, 하지만 가까이
Durable Objects(이하 DO)는 세 스토리지 중 가장 독특합니다. KV나 D1이 “데이터를 저장하는 공간”이라면, DO는 “상태를 가진 살아 있는 객체”에 가깝습니다.
핵심 원칙은 단순합니다: 하나의 Durable Object ID에 대해 전 세계에 단 하나의 인스턴스만 존재합니다. 같은 ID로의 모든 요청은 반드시 그 단일 인스턴스를 거칩니다. 이 덕분에 잠금(lock) 없이도 강한 일관성(strong consistency)이 보장됩니다.
DO 인스턴스는 처음 생성될 때 요청자에게 가까운 Cloudflare 데이터센터에 배치됩니다. 그 후에는 해당 위치에 고정되며, 모든 후속 요청이 그 위치로 라우팅됩니다. 인스턴스가 유휴 상태가 되면 자동으로 메모리에서 내려가고(eviction), 다음 요청이 오면 다시 깨어납니다.
이 “단일 인스턴스” 보장이 DO의 가장 강력한 무기입니다. 분산 시스템에서 가장 어려운 문제인 동시성 제어(concurrency control)가 설계 자체에 의해 해결됩니다.
트랜잭셔널 스토리지 API
각 DO 인스턴스는 자신만의 영속 스토리지를 가집니다. 2026년 현재 두 가지 스토리지 백엔드를 선택할 수 있습니다.
- Key-Value 스토리지: 기본 옵션. DO 인스턴스 내에서 키-밸류 쌍을 읽고 쓸 수 있으며,
transaction()으로 원자적 다중 쓰기가 가능합니다. - SQLite 스토리지: 2025년 도입된 옵션. DO 인스턴스 내에 완전한 SQLite 데이터베이스를 가지며, 관계형 쿼리를 실행할 수 있습니다.
// Durable Object 클래스 정의
export class ChatRoom {
constructor(state, env) {
this.state = state;
this.env = env;
this.sessions = new Set(); // 현재 연결된 WebSocket들 (메모리)
}
async fetch(request) {
const url = new URL(request.url);
switch (url.pathname) {
case "/join": return this.handleJoin(request);
case "/history": return this.handleHistory();
case "/stats": return this.handleStats();
default: return new Response("Not found", { status: 404 });
}
}
async handleStats() {
// KV 스토리지: 단일 키 읽기/쓰기
const messageCount = await this.state.storage.get("messageCount") || 0;
const memberCount = await this.state.storage.get("memberCount") || 0;
return Response.json({ messageCount, memberCount, activeSessions: this.sessions.size });
}
async handleHistory() {
// KV 스토리지: 접두사로 여러 키 조회
const messages = await this.state.storage.list({ prefix: "msg:", limit: 50, reverse: true });
const history = [...messages.entries()].map(([key, value]) => value);
return Response.json(history);
}
async saveMessage(message) {
// 트랜잭션: 메시지 저장 + 카운터 증가를 원자적으로
await this.state.storage.transaction(async (txn) => {
const count = (await txn.get("messageCount")) || 0;
const msgKey = `msg:${Date.now()}:${count}`;
await txn.put(msgKey, {
text: message.text,
author: message.author,
timestamp: new Date().toISOString()
});
await txn.put("messageCount", count + 1);
});
}
}this.state.storage는 DO 인스턴스 전용 영속 스토리지입니다. Workers KV와 달리 즉시 일관성을 보장합니다 — 쓰기 직후 읽으면 반드시 새 값이 반환됩니다. transaction() 내의 모든 연산은 원자적이므로, 카운터 증가 같은 동시성 문제가 원천적으로 해소됩니다.
WebSocket과 Hibernation API
Durable Objects의 킬러 유스케이스 중 하나가 실시간 통신입니다. DO는 WebSocket 연결을 직접 관리할 수 있으며, Hibernation API를 통해 비용을 극적으로 줄일 수 있습니다.
export class ChatRoom {
constructor(state, env) {
this.state = state;
this.env = env;
}
async fetch(request) {
if (request.headers.get("Upgrade") === "websocket") {
const pair = new WebSocketPair();
const [client, server] = Object.values(pair);
// Hibernation API: DO가 유휴 상태여도 WebSocket은 유지
this.state.acceptWebSocket(server, ["chat"]);
// 태그를 활용해 WebSocket 그룹핑
const username = new URL(request.url).searchParams.get("user") || "익명";
server.serializeAttachment({ username, joinedAt: Date.now() });
return new Response(null, { status: 101, webSocket: client });
}
return new Response("WebSocket endpoint", { status: 400 });
}
// Hibernation 콜백: 메시지가 오면 DO가 자동으로 깨어남
async webSocketMessage(ws, message) {
const { username } = ws.deserializeAttachment();
const data = JSON.parse(message);
const outgoing = JSON.stringify({
type: "message",
author: username,
text: data.text,
timestamp: new Date().toISOString()
});
// 같은 태그를 가진 모든 WebSocket에 브로드캐스트
const sockets = this.state.getWebSockets("chat");
for (const socket of sockets) {
try { socket.send(outgoing); } catch (e) { /* 끊어진 연결 무시 */ }
}
// 메시지 영속 저장
await this.saveMessage({ text: data.text, author: username });
}
async webSocketClose(ws, code, reason) {
// 연결 종료 처리
ws.close(code, reason);
}
async webSocketError(ws, error) {
ws.close(1011, "Unexpected error");
}
}Hibernation이 핵심입니다. 일반적인 WebSocket 서버는 연결이 유지되는 동안 메모리를 계속 점유합니다. 하지만 DO의 Hibernation API를 사용하면, 메시지가 없는 유휴 시간에는 DO 인스턴스가 메모리에서 내려가고 WebSocket 연결만 Cloudflare 인프라에 의해 유지됩니다. 메시지가 도착하면 DO가 자동으로 다시 메모리에 올라와 webSocketMessage()를 실행합니다.
과금은 DO가 실제로 메모리에 올라가 코드를 실행하는 시간에만 발생하므로, 대화가 뜸한 채팅방이라면 비용이 극적으로 줄어듭니다.
SQLite in Durable Objects
2025년부터 DO 인스턴스 내부에 SQLite 데이터베이스를 직접 내장할 수 있게 되었습니다. 이는 D1과는 다른 포지션입니다.
// wrangler.toml에서 SQLite 스토리지 백엔드 지정
// [[durable_objects.bindings]]
// name = "GAME_SESSION"
// class_name = "GameSession"
//
// [[migrations]]
// tag = "v1"
// new_sqlite_classes = ["GameSession"]
export class GameSession {
constructor(state, env) {
this.state = state;
this.sql = state.storage.sql; // SQLite 인터페이스
}
async initialize() {
this.sql.exec(`
CREATE TABLE IF NOT EXISTS players (
id TEXT PRIMARY KEY,
nickname TEXT NOT NULL,
score INTEGER DEFAULT 0,
last_action TEXT
)
`);
this.sql.exec(`
CREATE TABLE IF NOT EXISTS moves (
id INTEGER PRIMARY KEY AUTOINCREMENT,
player_id TEXT NOT NULL,
action TEXT NOT NULL,
payload TEXT,
created_at TEXT DEFAULT (datetime('now')),
FOREIGN KEY (player_id) REFERENCES players(id)
)
`);
}
async recordMove(playerId, action, payload) {
// DO 내 SQLite는 자동으로 트랜잭션
this.sql.exec(
"INSERT INTO moves (player_id, action, payload) VALUES (?, ?, ?)",
playerId, action, JSON.stringify(payload)
);
this.sql.exec(
"UPDATE players SET score = score + ?, last_action = ? WHERE id = ?",
payload.points || 0, action, playerId
);
}
async getLeaderboard() {
const rows = this.sql.exec(
"SELECT nickname, score FROM players ORDER BY score DESC LIMIT 10"
).toArray();
return rows;
}
}DO 내 SQLite와 D1의 차이는 명확합니다.
- D1: 글로벌 공유 데이터베이스. 여러 Workers가 같은 D1에 접근. 리드 리플리카로 분산 읽기.
- DO SQLite: 특정 객체 인스턴스의 전용 데이터베이스. 오직 해당 DO만 접근. 강한 일관성이 보장되지만 분산 읽기 없음.
게임 세션, 문서 공동 편집, 주문 처리 파이프라인처럼 “특정 엔티티의 복잡한 상태를 관계형으로 관리하면서 동시성 충돌 없이 처리”해야 할 때 DO + SQLite 조합이 빛납니다.
DO의 한계와 비용 주의
- 단일 위치: 하나의 DO는 하나의 데이터센터에 고정됩니다. 전 세계에서 접근하는 사용자라면 일부는 높은 지연을 겪습니다. 글로벌 읽기 성능이 중요하면 KV나 D1을 쓰세요.
- 콜드 스타트: 유휴 상태에서 깨어나는 데 약간의 지연이 있습니다(보통 수십 ms).
- 비용 구조: DO는 CPU 시간과 Wall-clock 시간(Duration) 모두에 과금됩니다. WebSocket 연결을 유지하면 Hibernation 없이는 비용이 급격히 올라갑니다.
- 스토리지 제한: KV 스토리지는 인스턴스당 수백 MB, SQLite는 더 많이 저장 가능하지만 “하나의 DO = 하나의 엔티티” 설계이므로 DB 전체를 DO에 넣는 용도는 아닙니다.
- 복잡한 프로그래밍 모델: DO는 일반 스토리지가 아니라 Actor 모델에 가깝습니다. 클래스를 정의하고, fetch를 처리하고, 라이프사이클을 이해해야 합니다. 학습 곡선이 KV·D1보다 높습니다.
DO가 빛나는 곳: 실시간 채팅방, 공동 문서 편집(CRDT 조율), 게임 세션, 분산 잠금/카운터/레이트 리미터, IoT 디바이스 상태, 워크플로우 오케스트레이터 — 요약하면 “여러 요청이 같은 상태에 동시에 접근하며, 충돌 없는 일관성이 필수”인 모든 경우.
3종 비교 — 한눈에 보는 의사결정 매트릭스
세 스토리지의 핵심 특성을 표로 정리합니다. 프로젝트 초기에 이 표를 보고 첫 판단을 내리세요.
| 항목 | Workers KV | D1 | Durable Objects |
|---|---|---|---|
| 데이터 모델 | 키-밸류 | 관계형(SQLite) | 객체별 KV 또는 SQLite |
| 일관성 | 결과적 (최대 60초) | Strong(Primary) / 세션 기반(리플리카) | Strong (단일 인스턴스) |
| 읽기 지연 | 극히 낮음 (엣지 캐시) | 낮음 (리드 리플리카) | 가변 (인스턴스 위치 종속) |
| 쓰기 지연 | 중간 (중앙 저장소) | 중간 (Primary 위치) | 낮음 (인스턴스 로컬) |
| 쿼리 능력 | 키/접두사만 | 전체 SQL | 객체 내 KV 또는 SQL |
| 동시성 제어 | 없음 (Last-write-wins) | 트랜잭션 (Primary) | 자동 직렬화 (Actor 모델) |
| WebSocket | 해당 없음 | 해당 없음 | 네이티브 지원 + Hibernation |
| 최대 밸류 크기 | 25 MiB | ~1 MB/행 | 128 KiB/키(KV), DB크기 제한(SQLite) |
| 글로벌 복제 | 자동 (전 엣지) | 자동 (리드 리플리카) | 없음 (단일 위치) |
| 학습 곡선 | 낮음 | 중간 (SQL 필요) | 높음 (Actor + 라이프사이클) |
| 비유 | 글로벌 분산 Redis | 엣지 PostgreSQL | Erlang/Akka Actor |
실전 시나리오별 선택 가이드
이론은 충분합니다. 실제 프로젝트에서 어떤 스토리지를 골라야 하는지, 다섯 가지 시나리오로 살펴봅니다.
시나리오 1: 블로그 조회수 카운터
“각 게시글의 조회수를 정확히 세고 싶다.”
직감적으로 KV에 넣고 싶지만, KV는 잘못된 선택입니다. 두 사용자가 동시에 같은 글을 보면 둘 다 count=100을 읽고 count=101로 쓸 수 있습니다. 하나의 조회가 유실됩니다.
추천: Durable Objects. 게시글 ID를 DO ID로 사용하면, 같은 글에 대한 모든 조회수 증가 요청이 하나의 인스턴스에서 직렬 처리됩니다.
export class ViewCounter {
constructor(state) {
this.state = state;
}
async fetch(request) {
// 원자적 읽기-증가-쓰기: 동시성 문제 없음
let count = (await this.state.storage.get("views")) || 0;
count++;
await this.state.storage.put("views", count);
return Response.json({ views: count });
}
}
// Worker에서 호출
export default {
async fetch(request, env) {
const postId = new URL(request.url).searchParams.get("post");
const stub = env.VIEW_COUNTER.get(env.VIEW_COUNTER.idFromName(postId));
return stub.fetch(request);
}
};“매우 정밀한 카운터가 아니라 대략적 수치면 된다”라면? 그때는 KV도 가능합니다. 분석용(analytics-grade) 정확도면 KV, 결제/재고처럼 정확해야 하면 DO입니다.
시나리오 2: URL 단축 서비스
“짧은 URL → 원본 URL 매핑을 저장하고, 클릭 시 리다이렉트.”
추천: Workers KV. 이것은 KV의 교과서적 유스케이스입니다.
- 쓰기: 새 단축 URL 등록 (드물게 발생)
- 읽기: 매 클릭마다 원본 URL 조회 (빈번)
- 일관성: 등록 직후 60초간 안 될 수 있지만, URL 단축에서 이 정도 지연은 수용 가능
export default {
async fetch(request, env) {
const slug = new URL(request.url).pathname.slice(1);
if (!slug) return new Response("URL Shortener", { status: 200 });
const target = await env.URLS.get(slug);
if (!target) return new Response("Not found", { status: 404 });
return Response.redirect(target, 301);
}
};만약 클릭 통계(날짜별, 국가별)도 필요하다면? 리다이렉트 매핑은 KV에 두고, 클릭 로그는 D1에 INSERT하는 하이브리드 패턴이 최적입니다.
시나리오 3: 실시간 채팅방
“방에 들어온 사용자끼리 실시간 메시지를 주고받는다.”
추천: Durable Objects. WebSocket + 실시간 상태 관리 + 메시지 브로드캐스트 — 이 세 가지를 동시에 충족하는 건 DO밖에 없습니다.
채팅방 ID를 DO ID로 사용하면, 같은 방의 모든 참여자가 같은 DO 인스턴스에 WebSocket으로 연결됩니다. 새 메시지가 오면 DO가 즉시 다른 참여자에게 브로드캐스트합니다. 앞서 보여드린 ChatRoom 코드가 바로 이 패턴입니다.
시나리오 4: SaaS 멀티테넌트 앱
“사용자 계정, 팀, 프로젝트, 태스크를 관리하는 프로젝트 관리 도구.”
추천: D1 (주 저장소) + KV (캐시) + DO (실시간 알림). 세 가지를 모두 쓰는 하이브리드 아키텍처입니다.
- D1: 사용자·팀·프로젝트·태스크 테이블. JOIN과 WHERE로 복잡한 쿼리 처리. “팀 A의 마감 임박 태스크 중 미완료 건” 같은 쿼리는 SQL이 아니면 고통스럽습니다.
- KV: 팀 설정(테마, 알림 환경설정), 기능 플래그, i18n 문자열. 자주 읽히지만 거의 바뀌지 않는 데이터.
- DO: “프로젝트 보드” 단위의 실시간 WebSocket. 팀원이 태스크를 드래그하면 같은 보드를 보는 다른 팀원에게 즉시 반영.
시나리오 5: 이커머스 장바구니
“로그인한 사용자의 장바구니에 상품을 추가/삭제/수량 변경.”
추천: Durable Objects. 장바구니는 “사용자별로 독립적이고, 수량 변경이 원자적이어야 하며, 비교적 짧은 수명”입니다.
export class ShoppingCart {
constructor(state) {
this.state = state;
this.sql = state.storage.sql;
this.sql.exec(`
CREATE TABLE IF NOT EXISTS items (
product_id TEXT PRIMARY KEY,
name TEXT,
price REAL,
quantity INTEGER DEFAULT 1
)
`);
}
async fetch(request) {
const url = new URL(request.url);
if (request.method === "POST" && url.pathname === "/add") {
const { productId, name, price, quantity } = await request.json();
this.sql.exec(
`INSERT INTO items (product_id, name, price, quantity)
VALUES (?, ?, ?, ?)
ON CONFLICT(product_id) DO UPDATE SET quantity = quantity + ?`,
productId, name, price, quantity, quantity
);
return this.getCart();
}
if (request.method === "DELETE") {
const productId = url.searchParams.get("product");
this.sql.exec("DELETE FROM items WHERE product_id = ?", productId);
return this.getCart();
}
return this.getCart();
}
getCart() {
const items = this.sql.exec("SELECT * FROM items").toArray();
const total = this.sql.exec("SELECT SUM(price * quantity) as total FROM items").one();
return Response.json({ items, total: total?.total || 0 });
}
}사용자별 DO를 할당하면, 두 탭에서 동시에 같은 상품을 장바구니에 넣어도 수량이 정확히 반영됩니다. 결제가 완료되면 D1에 주문 기록을 영구 저장하고, DO의 장바구니는 비우면 됩니다.
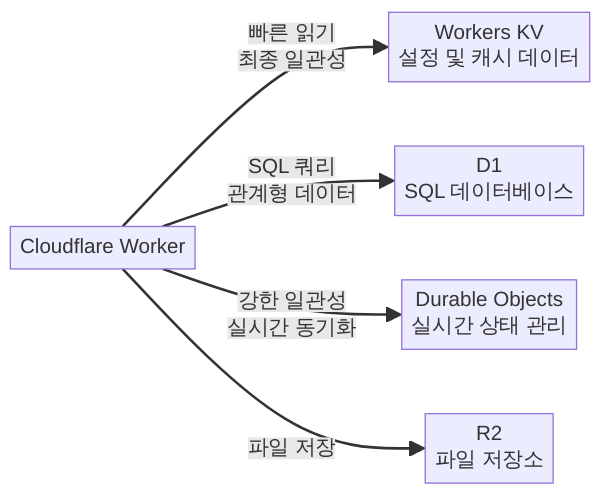
복합 사용 — 하나만 고를 필요 없다
시나리오 4에서 이미 보았듯, 실전에서는 여러 스토리지를 조합하는 것이 일반적입니다. 각 스토리지의 장점을 살리는 조합 패턴을 정리합니다.
패턴 1: KV as Cache + D1 as Source of Truth
async function getProduct(env, productId) {
// 1단계: KV 캐시 확인
const cached = await env.PRODUCT_CACHE.get(`product:${productId}`, { type: "json" });
if (cached) return cached;
// 2단계: D1에서 조회
const product = await env.DB.prepare(
"SELECT * FROM products WHERE id = ?"
).bind(productId).first();
if (product) {
// 3단계: KV에 캐시 (5분 TTL)
await env.PRODUCT_CACHE.put(
`product:${productId}`,
JSON.stringify(product),
{ expirationTtl: 300 }
);
}
return product;
}제품 정보는 D1에 정규화된 형태로 저장하고, 자주 조회되는 제품은 KV에 캐시합니다. 제품 정보가 업데이트되면 KV 캐시를 삭제(delete)하거나 덮어쓰면 됩니다.
패턴 2: DO for Real-time + D1 for Persistence
export class LiveAuction {
async placeBid(userId, amount) {
const currentBid = await this.state.storage.get("highestBid") || 0;
if (amount <= currentBid) {
return Response.json({ error: "입찰가가 현재 최고가보다 낮습니다" }, { status: 400 });
}
// DO: 실시간 최고가 갱신 (강한 일관성)
await this.state.storage.put("highestBid", amount);
await this.state.storage.put("highestBidder", userId);
// D1: 입찰 이력 영구 기록
await this.env.DB.prepare(
"INSERT INTO bid_history (auction_id, user_id, amount, bid_at) VALUES (?, ?, ?, datetime('now'))"
).bind(this.auctionId, userId, amount).run();
// WebSocket: 모든 참여자에게 알림
this.broadcast({ type: "newBid", amount, userId });
return Response.json({ success: true, highestBid: amount });
}
}실시간 입찰의 최고가 관리는 DO가 담당(강한 일관성 + 동시성 제어), 전체 입찰 이력은 D1에 영구 보관(관계형 쿼리 + 분석용). 이 패턴은 주식 거래, 좌석 예약, 인벤토리 관리에도 동일하게 적용됩니다.
패턴 3: KV for Config + DO for Rate Limiting
// KV: API 별 레이트 리밋 설정 저장
// key: "ratelimit:free" → value: { rpm: 60, rpd: 1000 }
// key: "ratelimit:pro" → value: { rpm: 600, rpd: 50000 }
export class RateLimiter {
async checkLimit(apiKey) {
const now = Math.floor(Date.now() / 60000); // 분 단위 윈도우
const key = `window:${now}`;
const count = (await this.state.storage.get(key)) || 0;
// 설정은 env.CONFIG(KV)에서 읽되, DO가 없어도 될 정도의 빈도
if (count >= this.maxRpm) {
return { allowed: false, remaining: 0, retryAfter: 60 - (Date.now() % 60000) / 1000 };
}
await this.state.storage.put(key, count + 1);
// 2분 후 자동 만료 (Alarm API)
if (count === 0) {
await this.state.storage.setAlarm(Date.now() + 120_000);
}
return { allowed: true, remaining: this.maxRpm - count - 1 };
}
async alarm() {
// 만료된 윈도우 정리
const keys = await this.state.storage.list({ prefix: "window:" });
const now = Math.floor(Date.now() / 60000);
for (const [key] of keys) {
const windowId = parseInt(key.split(":")[1]);
if (windowId < now - 1) await this.state.storage.delete(key);
}
}
}레이트 리밋 설정(분당 요청 수)은 KV에 저장하여 관리자가 대시보드에서 쉽게 변경할 수 있게 하고, 실제 카운팅은 DO에서 원자적으로 처리합니다. API 키별로 DO를 생성하면 키 간 간섭 없이 독립적인 레이트 리밋이 가능합니다.
홈랩 실습: Mac Studio에서 세 가지 스토리지 한번에 써보기
9회에서 설정한 Wrangler 환경이 있다면 바로 실습할 수 있습니다. Mac Studio 또는 Synology NAS의 SSH 터미널에서 따라 하세요.
# 1. 프로젝트 생성
mkdir cf-storage-lab && cd cf-storage-lab
npm init -y
npm install wrangler --save-dev
# 2. KV 네임스페이스 생성
npx wrangler kv namespace create CACHE
# → 출력된 id를 wrangler.toml에 붙여넣기
npx wrangler kv namespace create CACHE --preview
# → preview_id (로컬 개발용)
# 3. D1 데이터베이스 생성
npx wrangler d1 create my-app-db
# → 출력된 database_id를 wrangler.toml에 붙여넣기
# 4. D1 초기 스키마 적용
cat > schema.sql <<'EOF'
CREATE TABLE IF NOT EXISTS notes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
body TEXT,
created_at TEXT DEFAULT (datetime('now'))
);
EOF
npx wrangler d1 execute my-app-db --file=schema.sql
# 5. wrangler.toml 작성
cat > wrangler.toml <<'EOF'
name = "storage-lab"
main = "src/index.js"
compatibility_date = "2026-06-01"
[[kv_namespaces]]
binding = "CACHE"
id = "여기에_KV_id_붙여넣기"
preview_id = "여기에_preview_id_붙여넣기"
[[d1_databases]]
binding = "DB"
database_name = "my-app-db"
database_id = "여기에_D1_id_붙여넣기"
[durable_objects]
bindings = [
{ name = "COUNTER", class_name = "HitCounter" }
]
[[migrations]]
tag = "v1"
new_classes = ["HitCounter"]
EOF이제 세 스토리지를 모두 사용하는 Worker를 작성합니다.
# 6. Worker 코드 작성
mkdir -p src
cat > src/index.js <<'WORKER'
export class HitCounter {
constructor(state) {
this.state = state;
}
async fetch(request) {
let count = (await this.state.storage.get("hits")) || 0;
count++;
await this.state.storage.put("hits", count);
return Response.json({ hits: count });
}
}
export default {
async fetch(request, env) {
const url = new URL(request.url);
// /kv — KV 읽기/쓰기 테스트
if (url.pathname === "/kv") {
await env.CACHE.put("greeting", "안녕하세요, KV에서 왔습니다!", {
metadata: { lang: "ko", savedAt: new Date().toISOString() }
});
const value = await env.CACHE.get("greeting");
return new Response(value);
}
// /d1 — D1 SQL 테스트
if (url.pathname === "/d1") {
if (request.method === "POST") {
const { title, body } = await request.json();
const result = await env.DB.prepare(
"INSERT INTO notes (title, body) VALUES (?, ?)"
).bind(title, body).run();
return Response.json({ id: result.meta.last_row_id });
}
const notes = await env.DB.prepare(
"SELECT * FROM notes ORDER BY created_at DESC LIMIT 10"
).all();
return Response.json(notes.results);
}
// /counter — Durable Objects 테스트
if (url.pathname === "/counter") {
const id = env.COUNTER.idFromName("global");
const stub = env.COUNTER.get(id);
return stub.fetch(request);
}
return Response.json({
endpoints: {
"/kv": "Workers KV 테스트",
"/d1": "D1 SQL 테스트 (GET: 목록, POST: 추가)",
"/counter": "Durable Objects 카운터 테스트"
}
});
}
};
WORKER
# 7. 로컬 개발 서버 실행
npx wrangler dev
# 8. 테스트
# 다른 터미널에서:
curl http://localhost:8787/kv
curl http://localhost:8787/counter
curl http://localhost:8787/counter # 숫자가 증가하는 걸 확인
curl http://localhost:8787/d1
curl -X POST http://localhost:8787/d1 \
-H "Content-Type: application/json" \
-d '{"title":"첫 노트","body":"KV, D1, DO를 모두 써봤다!"}'
curl http://localhost:8787/d1 # 방금 쓴 노트가 보임
# 9. 엣지에 배포
npx wrangler deploywrangler dev는 로컬에서 KV, D1, DO를 모두 에뮬레이션합니다. 실제 Cloudflare 계정의 데이터에 영향을 주지 않으므로 안심하고 테스트하세요. wrangler deploy를 실행하면 프로덕션 바인딩(실제 KV 네임스페이스, D1 데이터베이스)으로 전환됩니다.
Synology NAS(DS+925)에서 실행한다면, SSH로 접속 후 Node.js와 npm이 설치되어 있는지 확인하세요. Container Manager의 Node.js 컨테이너 내에서 실행하는 것도 좋은 방법입니다.
의사결정 플로차트
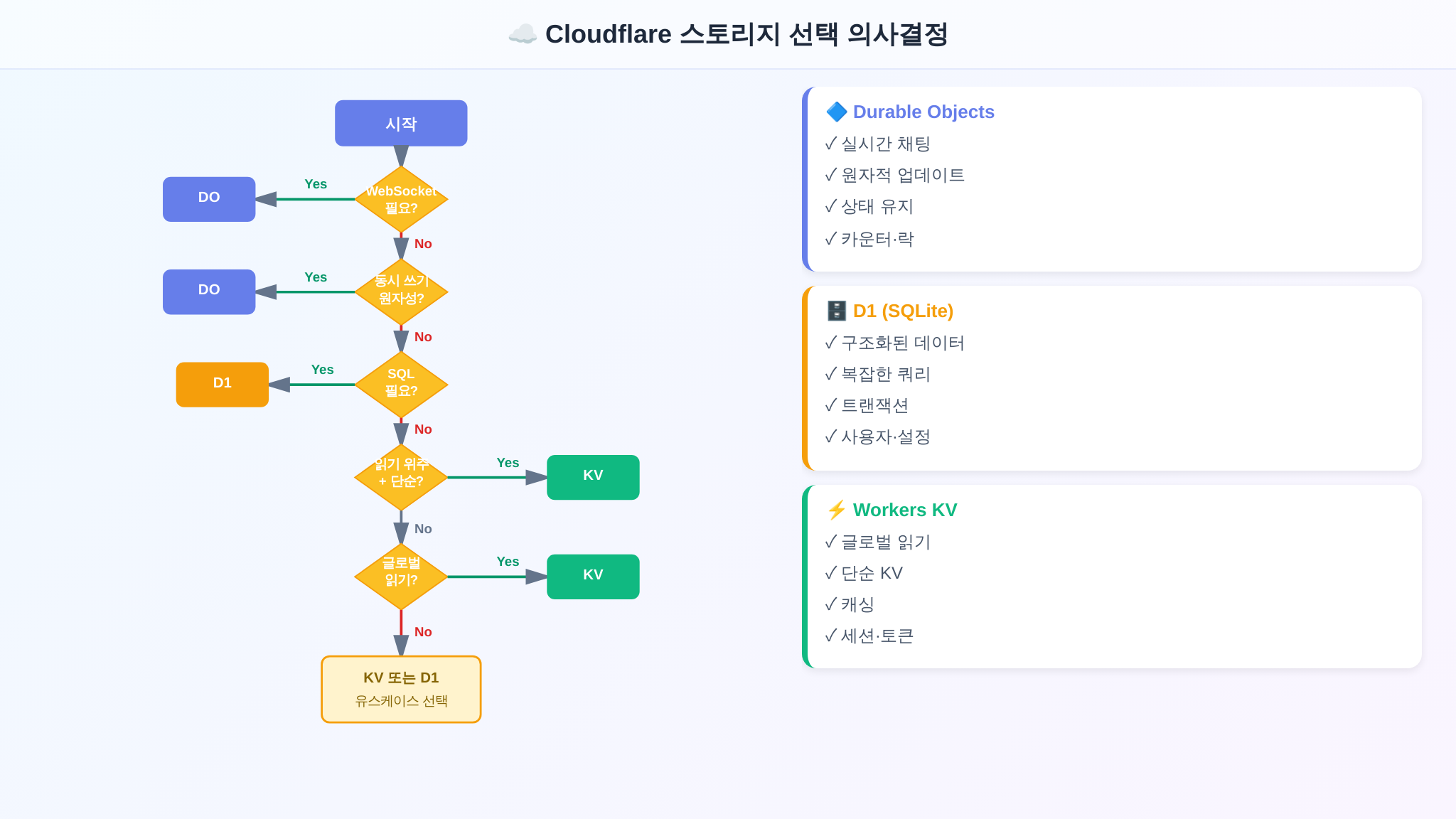
새 기능을 개발할 때 어떤 스토리지를 선택할지 고민된다면, 다음 질문을 순서대로 따라가세요.
Q1. 실시간 양방향 통신(WebSocket)이 필요한가?
- → Yes → Durable Objects
Q2. 동일 데이터에 동시 쓰기가 발생하며, 정확한 원자적 연산이 필수인가?
- → Yes → Durable Objects
Q3. SQL(JOIN, WHERE, GROUP BY, 집계)이 필요한가?
- → Yes → D1
Q4. 읽기가 압도적으로 많고 쓰기는 드문가?
- → Yes + 단순 키-밸류면 → Workers KV
- → Yes + 관계형 쿼리도 필요하면 → D1
Q5. 전 세계 어디서든 읽기 지연이 최소여야 하는가?
- → Yes + 키-밸류 → Workers KV
- → Yes + SQL → D1 (리드 리플리카)
Q6. 데이터가 특정 엔티티(사용자, 세션, 채팅방)에 귀속되는가?
- → Yes + 강한 일관성 필요 → Durable Objects
- → Yes + 일관성 덜 중요 → D1 또는 KV
여전히 판단이 어렵다면? D1부터 시작하세요. SQL은 대부분의 요구사항을 커버하며, 나중에 성능 병목이 확인되는 부분만 KV 캐시나 DO로 분리하면 됩니다.
자주 하는 실수 5가지
실수 1: KV를 카운터로 사용
앞서 설명했듯, KV는 동시 쓰기에서 last-write-wins입니다. 조회수, 좋아요 수, 재고 수량처럼 정확한 증감이 필요한 곳에 KV를 쓰면 데이터가 유실됩니다. 카운터에는 DO를 쓰세요.
실수 2: 모든 것을 DO에 넣기
DO는 강력하지만 비용이 높고, 단일 위치에 고정됩니다. 사용자 프로필처럼 “전 세계에서 빠르게 읽어야 하지만 동시 쓰기는 드문” 데이터까지 DO에 넣으면 불필요한 지연과 비용이 발생합니다.
실수 3: D1에 대용량 파일 저장
이미지, PDF, 비디오 같은 바이너리를 D1 행에 넣지 마세요. R2(8회에서 다룸)에 파일을 올리고, D1에는 R2 키(URL)만 저장하세요. DB 크기 한도를 빠르게 소진하고 쿼리 성능도 저하됩니다.
실수 4: KV의 list를 “전수 조사”에 사용
KV list()는 한 번에 1,000개만 반환합니다. 수만 개 키를 순회하며 필터링하는 건 극도로 비효율적입니다. 조건 검색이 필요하면 D1에 데이터를 넣고 SQL로 필터링하세요.
실수 5: DO에서 Hibernation 미사용
WebSocket을 사용하면서 Hibernation API를 쓰지 않으면, DO 인스턴스가 연결 유지 기간 내내 과금됩니다. 채팅방에 100명이 접속해 있지만 실제 메시지는 분당 1건이라면? Hibernation 없이는 100명분의 Wall-clock Duration이 계속 쌓이지만, Hibernation을 쓰면 메시지 처리 순간에만 과금됩니다.
월 비용 명세표
2026년 6월 기준 Cloudflare의 공식 요금입니다. Workers Free/Paid 플랜에 따라 달라집니다.
Workers KV
| 항목 | Free 플랜 | Workers Paid ($5/월) |
|---|---|---|
| 읽기 | 10만 회/일 | 1,000만 회/월 포함, 이후 $0.50/100만 회 |
| 쓰기 | 1,000 회/일 | 100만 회/월 포함, 이후 $0.50/100만 회 |
| 삭제 | 1,000 회/일 | 100만 회/월 포함, 이후 $0.50/100만 회 |
| 목록(list) | 1,000 회/일 | 100만 회/월 포함, 이후 $0.50/100만 회 |
| 저장 용량 | 1 GB | 1 GB 포함, 이후 $0.50/GB·월 |
D1
| 항목 | Free 플랜 | Workers Paid ($5/월) |
|---|---|---|
| 읽기 행 | 500만 행/일 | 250억 행/월 포함, 이후 $0.001/100만 행 |
| 쓰기 행 | 10만 행/일 | 5,000만 행/월 포함, 이후 $1.00/100만 행 |
| 저장 용량 | 5 GB (500MB/DB) | 5 GB 포함, 이후 $0.75/GB·월 |
| 데이터베이스 수 | 10개 | 50,000개 |
| Time Travel | 30일 | 30일 |
Durable Objects
| 항목 | Workers Paid ($5/월) 전용 |
|---|---|
| 요청 | 100만 회/월 포함, 이후 $0.15/100만 회 |
| Duration (Wall-clock) | 400,000 GB-초/월 포함, 이후 $12.50/100만 GB-초 |
| 저장 (KV 방식) | 1 GB 포함, 이후 $0.20/GB·월 |
| 저장 (SQLite 방식) | 5 GB 포함, 이후 $0.75/GB·월 |
| 읽기 단위 (SQLite) | 250억 행/월 포함, 이후 $0.001/100만 행 |
| 쓰기 단위 (SQLite) | 5,000만 행/월 포함, 이후 $1.00/100만 행 |
참고: Durable Objects는 Free 플랜에서 사용할 수 없습니다. Workers Paid($5/월) 이상이 필요합니다. KV와 D1은 Free 플랜에서도 일일 한도 내에서 무료로 사용 가능합니다.
비용 최적화 팁: 대부분의 개인 프로젝트/소규모 SaaS는 Workers Paid $5/월의 포함 한도 안에서 세 스토리지를 모두 충분히 사용할 수 있습니다. 포함 한도를 초과하는 주된 원인은 (1) Durable Objects의 Duration이 Hibernation 미적용으로 과도하게 누적되거나, (2) D1 쓰기가 로그성 데이터로 폭증하는 경우입니다. 전자는 Hibernation API를, 후자는 Analytics Engine(별도 서비스)이나 배치 쓰기를 검토하세요.
마무리 — “어디에 저장할까”는 설계의 시작
오늘 다룬 세 가지 스토리지를 한 문장으로 정리합니다.
- Workers KV: 전 세계에서 빠르게 읽고, 가끔 쓴다. 설정·캐시·매핑 테이블.
- D1: SQL로 쿼리하고, 관계를 표현한다. 사용자·주문·콘텐츠.
- Durable Objects: 동시성을 제어하고, 실시간으로 조율한다. 카운터·채팅·세션.
하나만 고를 필요 없습니다. 오히려 각 데이터의 성격에 맞는 스토리지를 조합하는 것이 Cloudflare 플랫폼의 진정한 힘입니다. 뜨거운(hot) 설정은 KV에, 정규화된 비즈니스 데이터는 D1에, 실시간 상태는 DO에 — 이 삼각 편대가 전통적인 “리전별 VM + RDS + Redis + PubSub” 조합을 $5/월로 대체합니다.
다음 11회에서는 오늘 사용한 wrangler CLI를 본격적으로 파헤칩니다. 로컬 개발 환경 설정, 환경 변수 관리, 스테이징/프로덕션 분리 배포, CI/CD 파이프라인 통합까지 — Wrangler CLI로 Workers 개발 워크플로우를 완성하는 방법을 다룹니다.
이미지는 Leonardo AI 로 생성되었습니다.
이미지는 Claude AI 로 생성되었습니다.
◀ 이전 9화 (다음 차수는 아직 게시되지 않았습니다)

